

Bank-IT: Mega-Probleme mit Metadaten? Lässt sich lösen …

Pentaho
Ambitionierte IT-Transformationsprojekte in einer Bank zu leiten, ist heutzutage ein wenig, wie Fußballmanager eines Erstligisten oder der Nationaltrainer zu sein: Man kann alles für den langfristigen Erfolg seines Teams richtig machen und wird es trotzdem schnell bereuen, sich jemals bei Twitter angemeldet zu haben. Bankmanager gleichen Fußballfans in ihrer Ungeduld für schnelle Ergebnisse und sofortige Siege. Wenn man aber tiefergehende, systematische Probleme lösen will, sind voreilige Lösungen nicht unbedingt die richtigen.
von Dominik Classen, Sales Engineering Team Lead EMEA & APAC bei Pentaho
Wer sich mit Bank-IT befasst, kennt die Probleme, die die Integration, Vorbereitung und Verarbeitung von Daten unter Einhaltung von Data Governance mit sich bringen. Besonders, wenn es sich um Insellösungen handelt und die Daten über verschiedene Standorte und auf verschiedenen Plattformen verteilt sind. In diesem Fall erscheint das Gerede über Big Data, Hadoop und den sogenannten „Single Point of Truth“ so abwegig wie der Aufstieg vom Außenseiter zum deutschen Meister. Das muss nicht sein. Das Premier-League-Märchen des englischen Meisters Leicester City und Griechenlands Triumph bei der Europameisterschaft 2004 in Portugal zeigen, dass es durchaus geht. Und es muss.
Pentaho
Wir sind an einem Punkt angelangt, an dem Untätigkeit zur Abseitsfalle wird. Unzufriedene Kunden, härtere Strafen bei Nichteinhaltung von Compliance-Richtlinien und Sicherheitsverstöße führen schnell zu negativen Schlagzeilen und Shitstorms. FinTech Start-ups stehen in den Startlöchern. Und zwar ohne Altsysteme, mit neuesten Technologien und Angeboten, die eine neue Generation von Kunden ansprechen.
Dabei ist es ja nicht so, dass Banken absichtlich ihre Daten in Insellösungen halten, um sich selbst und den Kunden das Leben schwerer zu machen.
Es scheint beinahe ein unmögliches Unterfangen, Metadatenstrukturen bei hunderten oder tausenden Datenquellen und Formaten zu definieren. Das muss aber geschehen, damit die Bank alle Daten zusammenführen und voll nutzen kann.”
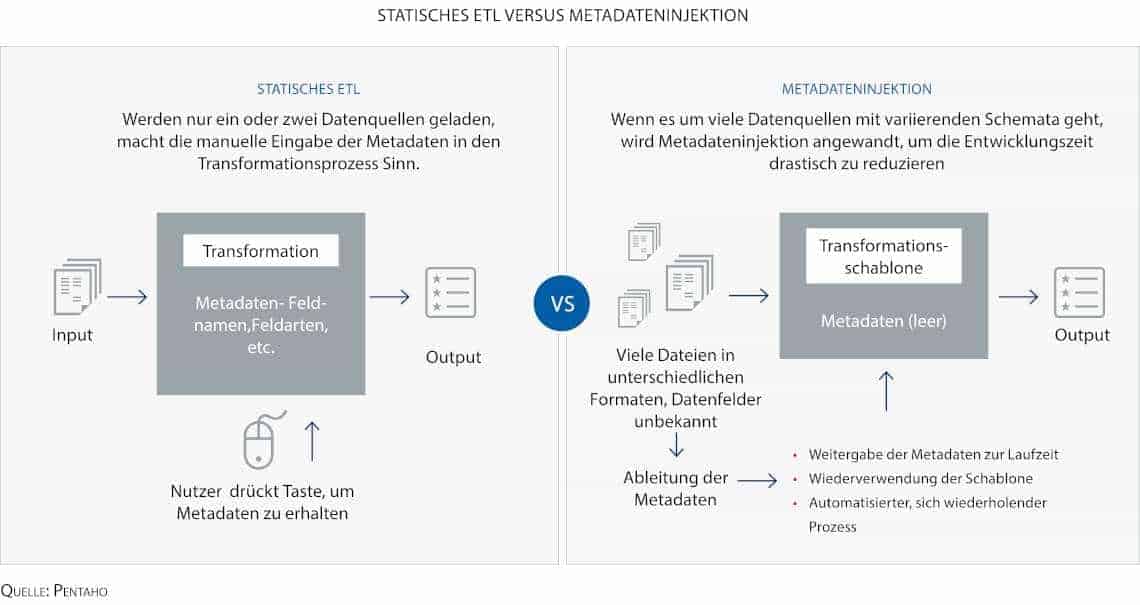
Bisher war der einzige Ausweg aus dieser Situation, während des Prozesses der Datenintegration die Metadatenstrukturen manuell mit Python oder anderen Programmiersprachen zu definieren. Skalieren lässt sich die manuelle Programmierung allerdings nur durch mehr Personal- und Zeitaufwand. Dabei gibt es auch für die Bank-IT längst so etwas wie den modernen Fußball.
Neue Ansätze und moderne Tools
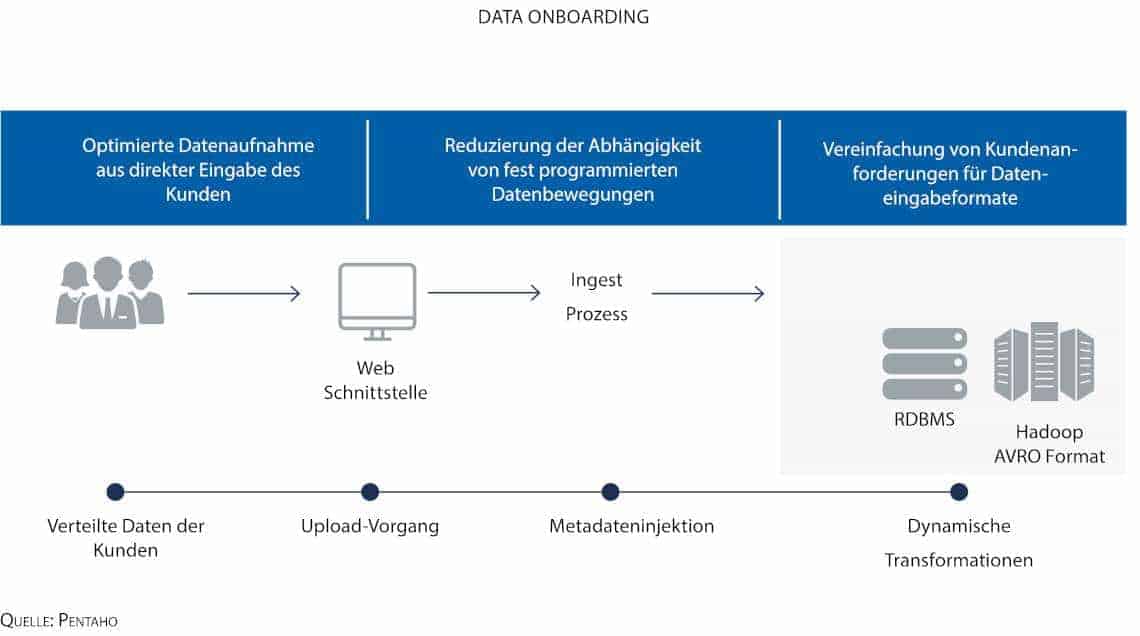
Anbieter von Business Analytics- und Datenintegrationslösungen haben damit begonnen, neue Tools auf den Markt zu bringen, die den Umgang mit Metadaten vereinfachen. Ein neuer Ansatz ist hier das sogenannte Metadata Driven Data Onboarding, das durch Metadateninjektion realisiert wird. Beim Data Onboarding geht es um mehr als nur die Einspeisung einzelner weniger Datensätze während der Datenintegration. Es wird bei vielen, sich stetig ändernden Datenquellen als ein sich wiederholender, skalierbarer Prozess angewandt, bei dem die Kontrolle und Data Governance gewährleistet wird. Traditionelle ETL-Methoden stoßen in diesem Big Data-Szenario an ihre Grenzen, weil die ETL-Jobs für die Einspeisung jeder Datenquelle manuell definiert und ausgeführt werden müssen. Gerade im Bankumfeld, wo es viele verschiedene Systeme gibt, ist das nicht nur eine zeitaufwendige Arbeit, die Programmierkenntnisse verlangt, sondern sie ist auch fehleranfällig und nur mit viel Aufwand zu warten.
Petaho
Beim Metadata Driven Data Onboarding hingegen wird lediglich eine Datenschablone definiert, die in groben Zügen die Datenintegration vorgibt und die zur Laufzeit automatisch mit Informationen sowie Anweisungen gefüllt und zur Ausführung gebracht wird. Vor seinem Einstieg bei Pentaho 2014 war Dominik Claßen in verschiedenen Positionen im Sales Engineering und im Technischen Support tätig, unter anderen für Unternehmen wie Microstrategy, IBM, Cognos und T-Systems. Der Diplom-Wirtschaftsinformatiker verfügt über Abschlüsse der Berufsakademie Mannheim und der Open University London. Dominik Claßen ist Sales Engineering Team Lead EMEA & APAC bei Pentaho. Er ist ein Branchenkenner mit mehr als zehnjähriger Arbeitserfahrung im Bereich Business Analytics/Business Intelligence.
Dominik Claßen ist Sales Engineering Team Lead EMEA & APAC bei Pentaho. Er ist ein Branchenkenner mit mehr als zehnjähriger Arbeitserfahrung im Bereich Business Analytics/Business Intelligence.
Vorbereitung für Big Data und IoT
Wenn das Mega-Problem mit den Metadaten erst einmal gelöst ist, dann ist auch der Weg frei für zukunftsweisende Big Data- oder IoT-Anwendungsfälle. Wie wir durch unsere Arbeit wissen, arbeiten viele etablierte Banken nicht nur mit Tools für Metadata Driven Data Onboarding, sondern sind auch daran beteiligt, die Funktionalitäten zu definieren. Das ist sinnvoll, denn je gezielter die Metadateneinspeisung für spezifische Anwendungsfälle definiert wird, desto einfacher wird es hinterher, die Daten voll auszuschöpfen, und dann kann dem Hadoop-Sommermärchen in der Bank eigentlich nichts mehr entgegenstehen.aj
Sie finden diesen Artikel im Internet auf der Website:
https://itfm.link/32577


Schreiben Sie einen Kommentar