

Smart Retail Banking: Wie die Bank-KI laufen lernt

Senacor
Bis zu 25 Prozent mehr Gewinn sei drin, wenn Unternehmen auf Künstliche Intelligenz setzen. Das hat das Bundeswirtschaftsministerium gerade erst ausrechnen lassen. Auch bei der Rendite schneiden KI-affine Firmen demnach besser ab. Doch viele Banken tun sich schwer, herauszufinden, wo genau sich das versprochene Geld versteckt, wie die KI-Studie Smart Retail Banking zeigt.
Als größtes Problem beschreiben die Institute, dass sie zu wenig Fälle identifiziert hätten, in denen sich eine Künstliche Intelligenz auszahlt. Meist geht es darum, bestehende Muster zu erkennen, um etwa aufzudecken, ob jemand Geld wäscht oder Betrügereien stattfinden. Diese AML/Fraud-Prozesse eignen sich deshalb besonders gut für KI, weil sie vergleichsweise klaren Regeln folgen, die sich einer Maschine leicht vermitteln lassen. Zudem stehen mit den Konto- und Umsatzdaten ausreichend viele Informationen bereit, um die KI zu füttern und zu trainieren.Bei anspruchsvolleren Aufgaben, bei denen Kunden und KI interagieren, sieht die Welt dagegen schon anders aus.
KI vom Kunden abgeschirmt
Wie die Befragten erläutern, verzichten die Banken überwiegend darauf, eine KI zu nutzen, um Kunden zu ermöglichen, ihre Ausgaben mit Schlagworten zu versehen oder ihr Konto zu analysieren (vgl. Abb. 1). Obwohl es schon Chatbots gibt, die diese Aufgaben übernehmen oder erleichtern, bieten die Institute das noch nicht flächendeckend an. Auch digitale Helfer, die beim Investieren unter die Arme greifen, suchen die Kunden vergebens.
Freiberuflich Tätige oder Inhaber eines kleinen Unternehmens bekommen von ihrer Bank ebenfalls kaum Unterstützung, etwa durch ein intelligentes Rechnungs- und Mahnwesen. Nach vorne zum Kunden heraus bietet so gut wie kein Institut KI-unterstützte Dienste an.”

Fraunhofer, Senacor.
Viele FinTechs, vor allem aus den USA, trauen sich schon mehr. Beispielsweise berechnen sie aus den Bildungsdaten wie dem SAT-Score (Scholastic Assessment Test) oder Noten aus dem Studium, ob sie jemandem einen Kredit gewähren würden oder nicht. Andere Anbieter werten soziale oder psychometrische Informationen aus, um einen Risikowert zu errechnen. Diese Anbieter profitieren einerseits vom weniger strengen Datenschutz in den USA, aber auch von einem Geschäftsmodell, dass sie auf der grünen Wiese entwickelt haben. Dennoch können die Banken davon lernen, weil sich die von FinTechs eingesetzte KI kaum von der unterscheidet, auf die auch Banken setzen. Sie verarbeiten bloß verschiedene Datensätze.
Eine Bankkundin möchte beispielsweise eine Immobilie kaufen. Sie ist 35 Jahre alt, hat einen positiven Schufa-Score und verfügt über 120.000 Euro Eigenkapital. Ihr Konto war immer im Plus und monatlich fließt ein fester Betrag ins Depot. Eine KI gleicht diese Daten mit jenen ab, auf denen sie zuvor trainiert worden ist, und errechnet daraus die Bonität der Kundin (vgl. Abb. 2). Neuronale Netze und Deep Learning machen dies heute schon möglich. Vereinfacht ausgedrückt durchlaufen die Daten mehrere Schichten, in denen die Algorithmen der KI arbeiten. Dabei versucht sie, bestehende Muster zu erkennen (Unsupervised Learning). Doch das ist gleich aus drei Gründen für viele Banken nicht trivial.
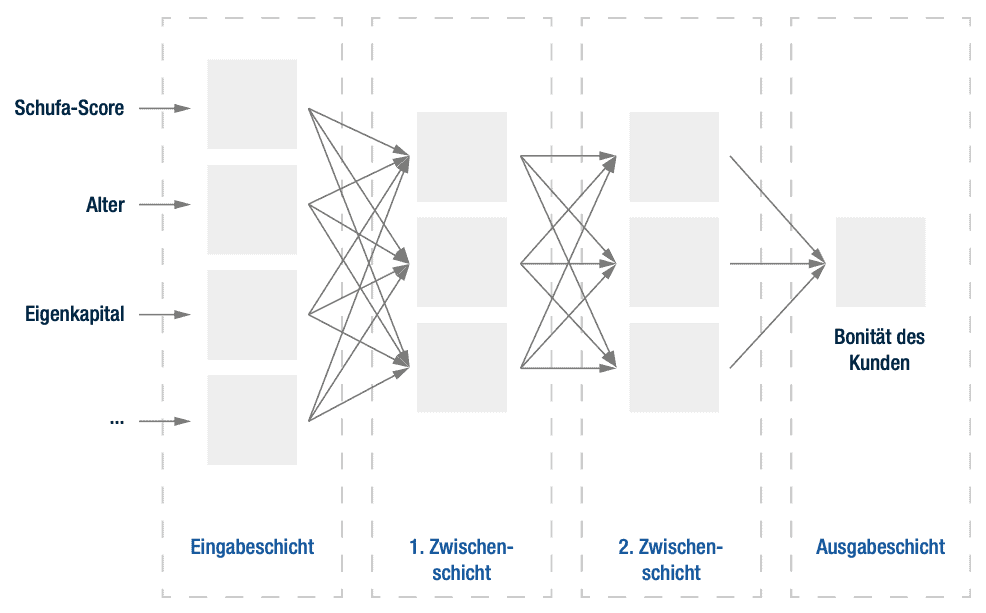
Fraunhofer, Senacor.
KI-Hürden für Banken
Wer einen Kredit ablehnt, muss erklären können, warum. Das ist gar nicht so einfach, weil sich später kaum nachvollziehen lässt, wie die KI entschieden hat. Was die KI rechnet, bleibt meist ihr Geheimnis, weil nicht jede ihrer Schlussfolgerungen offensichtlich ist.”
Wer einen Kredit ablehnt, muss erklären können, warum. Das ist gar nicht so einfach, weil sich später kaum nachvollziehen lässt, wie die KI entschieden hat. Was die KI rechnet, bleibt meist ihr Geheimnis, weil nicht jede ihrer Schlussfolgerungen offensichtlich ist.”
Zudem darf eine Maschine nicht alles, was sie aufdeckt, auch nutzen. Manches ist tabu. Dazu gehört etwa das Geschlecht oder die Herkunft einer Person sowie manche Zusammenhänge, über die zwar Daten vorliegen, die sie jedoch nicht ohne weiteres verwenden darf. Daher müssen Banken versichern, dass sie nicht alle Informationen verwerten, über die sie verfügen – oder sie holen sich explizit die Erlaubnis ihrer Kunden dafür (Opt-In).
Ein anderer Bereich, in denen die Banken die KI-Aktivitäten „accountable“ machen müssen, ist der Hochfrequenzhandel. Mit Explainable AI oder XAI, einer erklärbaren KI, zeichnet sich bereits ab, wie es künftig gehen kann. Allerdings dürfte dafür noch etwas Zeit für Forschung und Entwicklung ins Land ziehen.
Viele Banken fürchten sich aber auch davor, ihre Kunden vor den Kopf zu stoßen.”
Niemand möchte etwa das Gefühl bekommen, dass sich die eigene Bank durch einen Chatbot bloß das persönliche Gespräch spart. Zudem zeigen Umfragen, dass sich jeder dritte Bundesbürger vor KI ängstigt. Die Menschen zeigen sich skeptisch, weil sie womöglich die Kontrolle verlieren, überwacht werden oder unethischen Entscheidungen ausgesetzt sind. Das hat die Firma Bosch ermitteln lassen, wohl auch deshalb, weil sie alle ihre Geräte bis 2025 mit KI ausstatten oder von KI produzieren lassen möchte. Allerdings zeigen sich die Kunden offener, je länger eine neue Technologie sich bereits bewährt hat. Es gilt: Vertrauen durch Vertrautheit.
Wie gut das klappt, zeigt auch ein Blick aufs Smartphone. Mehr als die Hälfte der Deutschen erledigt damit inzwischen ihre Bankgeschäfte – und zwar per App. Vor drei Jahren waren es nur 30 Prozent, wie eine Umfrage des Digitalverbands Bitkom zeigt. Wer seinen Kunden dabei helfen möchte, Vorbehalte gegenüber KI abzubauen, muss also dafür sorgen, dass diese sich darauf einlassen, weil sie neugierig sind. Das gelingt vor allem dann, wenn die KI ihnen etwas bietet, das sie noch nicht kennen, was sie begeistert. Nur so lassen sich die Kunden mitreißen, weil sie erleben, was sie nicht sowieso schon längst erwarten (vgl. Abb. 3). Darum lohnt es sich, mehr in KI zu investieren und – das ist die dritte Hürde – die eigene Organisation KI-fähig zu machen.
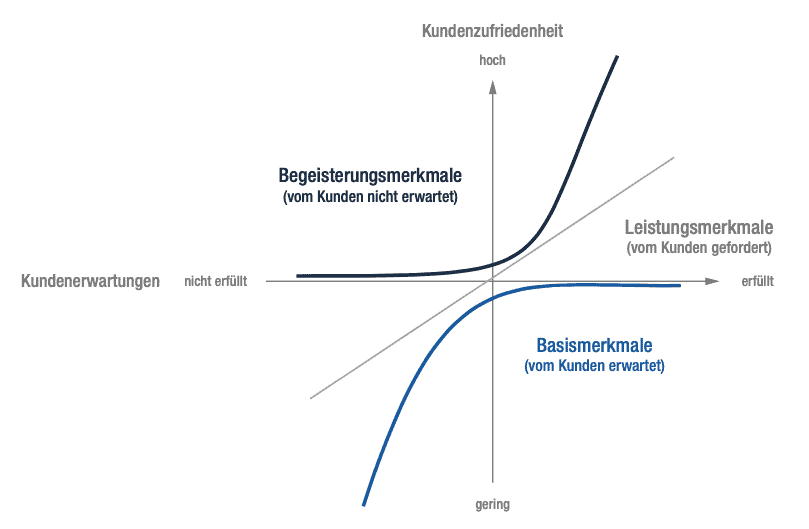
Kano, 1978/Senacor
KI-fähig bedeutet zweierlei: Auf der einen Seite geht es darum, passende Anwendungsfälle zu identifizieren, und auf der anderen Seite, die KI an sich in Gang zu kriegen. Beides zusammen lässt sich lernen.
KI braucht eine konkrete Aufgabe
Im ersten Schritt geht es darum, herauszufinden, wie eine Bank ihren Kunden helfen und sie dabei begeistern kann. Die Bankkundin von vorhin könnte etwa selbständig arbeiten, als Grafikerin, und regelmäßig Rechnungen empfangen und versenden. Über eine App speichert, erstellt und versendet sie die Dokumente. Weil sie ihr Konto über eine PSD2-Schnittstelle eingebunden hat, gleicht die App automatisch ab, ob alles pünktlich bezahlt ist. Obwohl Banken wie der natürliche Anbieter für solche Dienste erscheinen, müssen sich die meisten Selbständigen dafür die App eines Drittanbieters installieren. Und das, obwohl der „Use Case“ gerade hier wirklich auf der Hand liegt.
 Prof. Dr. Gilbert Fridgen ist Inhaber des vom luxemburgischem National Research Fund und Paypal gestifteten Lehrstuhls für Digital Financial Services an der Universität Luxemburg und Mitgründer des Fraunhofer BlockchainLab. Er forscht vor allem zu disruptiven Technologien wie der Distributed Ledger Technology (DLT), digitalen Identitäten, dem Internet der Dinge und Künstlicher Intelligenz.
Prof. Dr. Gilbert Fridgen ist Inhaber des vom luxemburgischem National Research Fund und Paypal gestifteten Lehrstuhls für Digital Financial Services an der Universität Luxemburg und Mitgründer des Fraunhofer BlockchainLab. Er forscht vor allem zu disruptiven Technologien wie der Distributed Ledger Technology (DLT), digitalen Identitäten, dem Internet der Dinge und Künstlicher Intelligenz.
 Dr. Werner Steck ist Partner bei Senacor Technologies und verantwortet die Practice „New Technologies“. Zu seinen Schwerpunkten zählen Geschäftsmodelle von Retail-Banken sowie neue Technologien und wie sie sich auf das Bankgeschäft auswirken. Den promovierten Wirtschaftsinformatiker interessiert dabei vor allem, wie Unternehmen in der digitalen Welt ihren Kunden die besten Angebote machen.
Dr. Werner Steck ist Partner bei Senacor Technologies und verantwortet die Practice „New Technologies“. Zu seinen Schwerpunkten zählen Geschäftsmodelle von Retail-Banken sowie neue Technologien und wie sie sich auf das Bankgeschäft auswirken. Den promovierten Wirtschaftsinformatiker interessiert dabei vor allem, wie Unternehmen in der digitalen Welt ihren Kunden die besten Angebote machen.
Die KI bekommt semi-strukturierte Daten geliefert und wäre in der Lage, automatisch die gezahlte und empfangene Umsatzsteuer zu ermitteln, monatlich beim Finanzamt – über die Elster-Schnittstelle – zu melden und rechtzeitig zu warnen, falls das Konto nicht ausreichend gedeckt ist, wenn das Finanzamt abbuchen will.”
Die gleiche KI versteht auch, dass sie eine eingehende Rechnung bezahlen muss. Und das kann sie, indem sie auf dem Konto prüft, ob die Rechnung schon bezahlt worden ist und falls nicht, eine Überweisung anlegt und durch eine Push-Nachricht signalisiert, dass sie freigegeben werden kann – auch zu einem späteren Zeitpunkt als Terminüberweisung.
Auf solche Ideen zu kommen, setzt ein konkretes Ziel voraus.”
Die befragten Experten geben jedoch an, dass ihre KI-Versuche bislang gerade nicht auf einen bestimmten Zweck hin ausgerichtet waren. Deshalb hätten sie sich weder mit den Folgeprozessen beschäftigt noch damit, wie sich eine solche Idee zu Geld machen lässt. Das Problem: Ähnlich wie vor einigen Jahren, als Big Data in Mode war, begeben sich viele Unternehmen auf die berühmte Suche nach der Nadel im Heuhaufen. Schließlich müsse die Antwort ja in den Daten stecken. Doch das klappt nur, wenn sich eine konkrete Aufgabe formulieren lässt, die eine KI lösen soll, und wenn KI von vornherein integriert ist, wenn die Bank ein solches Produkt entwickelt.
Von DevOps zu MLOps
Das Dilemma „keine Idee für die Daten“ und „keine Daten für die Idee“ müssen die Banken sowohl technisch wie organisatorisch angehen.”
Das Dilemma „keine Idee für die Daten“ und „keine Daten für die Idee“ müssen die Banken sowohl technisch wie organisatorisch angehen.”
Technisch, weil viele Legacy-Systeme nicht dafür gemacht sind, Daten offen und in real time auszutauschen. Je schneller und einfacher die KI an alle benötigten Informationen gelangt, desto besser. Eine modulare IT-Architektur hilft dabei, ähnlich wie sie sich bei Kernbanksystemen, API-Plattformen und automatisierten Prozessen bereits bewährt. Am Ende steht ein KI-basiertes Ökosystem, das sich stufenweise weiterentwickelt. Doch das ist nicht alles, auch im Betrieb ändern sich die etablierten Vorgehensweisen.
Organisatorisch lohnt es sich für die Institute, sich an DevOps zu orientieren und zu so etwas wie einer MLOps zu gelangen. KI-relevante Abläufe, die sich vor allem darum drehen, die KI richtig zu trainieren (vgl. Abb 4), gehören von vornherein mit in die Entwicklung. Der Grund: Ein ML-System, das idealerweise eigenständig lernt, besteht nur zu einem kleinen Anteil aus dem ML-Code. Ebenso relevant sind etwa Testing und Debugging, Datenintegration sowie die Infrastruktur, auf der das alles läuft. Data Scientists einzustellen, reicht darum allein noch nicht aus, um einer KI das Laufen beizubringen. Damit das klappt, müssen diese Spezialisten mit den Software-Entwicklern und Fachbereichen zusammenarbeiten.

Fraunhofer, Senacor
MLOps – oder: Machine Learning plus Operations – führt in mehreren Schritten zum gewünschten Ergebnis. Zuerst modellieren Data Scientists, wie eine KI lernen soll. Dafür entwickeln sie ein weitgehend eigenständiges Modell, das sie als Artefakt an die Software-Entwickler übergeben und das diese über einen Service zugreifbar machen. Die ML-Pipeline (vgl. Abb. 5) hilft dabei, diese Modelle ständig zu überprüfen (Monitoring) und neue Versionen per Knopfdruck in das laufende System zu integrieren. Das Ziel: ein ML CI/CD-System (Continuous Integration/Continuous Development), das sowohl den Data Scientists eine einfache Weiterentwicklung erlaubt als auch den Betrieb der Software unterstützt.
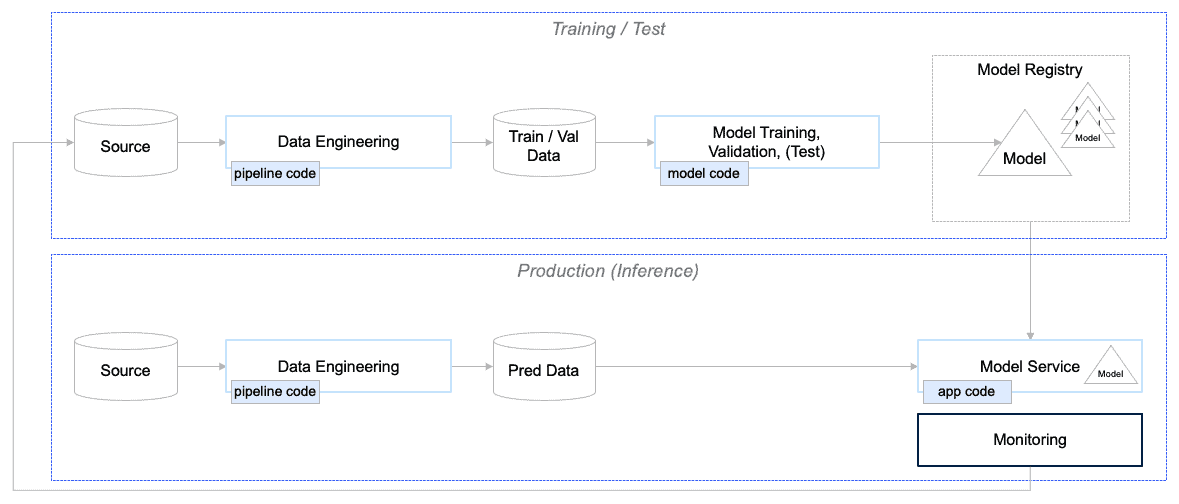
Senacor
KI vollkommen unabhängig zu betreiben, dürfte dagegen scheitern. Das funktioniert nur in sehr eng abgegrenzten Fällen und kaum im direkten Kundenkontakt. Ein britisches Start-Up hat beispielweise eine KI darauf trainiert, KFZ-Schäden zu analysieren. Wer einen Unfall melden möchte, braucht den Schaden nur zu fotografieren und die Bilder über eine App an den Versicherer zu schicken – den Rest erledigt die Maschine. Solche Ideen sind schön, weil sie zeigen, wohin die Reise geht.
Doch wenn KI nicht in den größeren Unternehmenskontext eingebunden ist, bleibt sie isoliert und ähnlich beschränkt, wie einige Cloud-Projekte, die zwar als Leuchtturm existieren, aber noch keinen nennenswerten Erlösbeitrag leisten.”
Fazit
KI kommt langsam in den Banken an.”
KI kommt langsam in den Banken an.”
Damit auch die Kunden davon etwas haben, müssen sich die Institute aber noch mehr trauen – und sich häufiger fragen, was ihre Kunden neben klassischen Bankangeboten noch gebrauchen können. Schlagwörter wie Embedded Banking zeigen schon seit längerem auf, wie sich Kunden Banking künftig vorstellen: unkompliziert und eingebunden in ihren Alltag. Das bedeutet für die Banken, sich zu überlegen, wie sie über Konten und Kredite hinaus für ihre Kunden relevant bleiben. KI-unterstützte Dienste stellen dabei einen von sicherlich vielen Bausteinen dar. Wer das ernsthaft betreiben möchte, sollte sich jedoch darauf einstellen, mehr als nur ein technisches Problem zu lösen. KI wirkt sich, genau wie agile Methoden, auf die gesamte Organisation aus. Im Vorteil sind Banken, die ohnehin schon damit begonnen haben, sich mehr wie ein Technologie-Unternehmen zu fühlen. Ihnen fällt es leichter, Ansätze wie MLOps zu adaptieren und KI dadurch schneller fruchtbar zu machen.
Über die KI-Studie: “Smart Retail Banking”
Die praxisorientierte Studie „Smart Retail Banking: Potenziale und Herausforderungen Künstlicher Intelligenz“ wurde vom Interdisciplinary Center for Security, Reliability and Trust der Universität Luxemburg, der Projektgruppe Wirtschaftsinformatik des Fraunhofer-Instituts für Angewandte Informationstechnik FIT und Senacor Techologies erstellt. Dafür wurden insgesamt 22 qualitative Interviews mit Entscheidern auf C-Level, Bereichsleitern und Gründern von Universalbanken, Direktbanken, FinTechs sowie IT-Dienstleistern, einem Anbieter von Bonusprogrammen und einer Spezialbank geführt.
Wer die eigenen Kontaktdaten preisgibt, bekommt hier die Studie kostenfrei.Prof. Dr. Gilbert Fridgen und Dr. Werner Steck, Senacor
Sie finden diesen Artikel im Internet auf der Website:
https://itfm.link/120178


Schreiben Sie einen Kommentar