

Cloud-Transformation in der Praxis: „Wir deployen in Stunden statt Wochen“
Frau Libiseller, Herr Dittmer, alle reden über künstliche Intelligenz und Sie kommen mit der Cloud. Sind Sie nicht etwas spät dran?

perplexity.ai.
Libiseller (lacht): Das geht ja gut los?! Fragen wir doch mal die KI selbst: Auf einer Skala von 1 bis 10, wie wichtig ist die Cloud für Banken? Acht bis neun, da hätte ich sogar noch etwas mehr getippt. Ohne Cloud funktioniert die KI nämlich auch nicht richtig. Vom Chatbot über Gen AI bis hin zu Agentic AI sind die KI-Werkzeuge darauf angewiesen, dass die Daten, die sie zum Arbeiten brauchen, jederzeit bereitstehen und fließen können. Der entscheidende Schlüssel lautet Zugriff, Zugriff auf möglichst viele Daten aus möglichst vielen Systemen. Darum werden Banken nicht darum herumkommen, tiefgreifende Cloud-Transformationen anzugehen.
Gerade erst ist die SIBOS in Frankfurt zu Ende gegangen, dort war an fast jedem Stand die Rede von KI. Cloud schien kein Thema zu sein.
Libiseller: Jeder versucht, KI in seine Produkte einzubauen. Denken Sie für einen Moment ans autonome Fahren. KI ist auch da der Fokuspunkt. Ohne anständig asphaltierte Straßen bleiben aber auch die KI-Autos stecken. So verhält es sich auch mit der Cloud. Das eine ist die notwendige Infrastruktur für das andere.
Selbst nicht mehr ganz aktuelle Studien zeigen, dass sich die allermeisten Banken bereits mit der Cloud beschäftigen. Wo sehen Sie da noch Potential?
Dittmer: Bei kritischen Applikationen. Sie haben Recht damit, dass viele Banken einzelne Cloud-Dienste nutzen. Durchgehend cloudifizierte Service-Architekturen mit Applikationen, die cloud-native entwickelt oder zumindest cloud-ready gemacht worden sind, bilden aber immer noch die absolute Ausnahme. Denken Sie etwa an Kernbanksysteme oder an Zahlungsverkehr. Aber auch aus Sicht eines Dienstleisters:
Ohne Cloud lassen sich praktisch keine Ausschreibungen mehr gewinnen, weil die Banken sich zunehmend dafür entscheiden, as a Service einzukaufen – und wer dabei auf die Cloud verzichtet oder darin nur eine andere Form von Rechenzentrum sieht, wird das kaum wirtschaftlich bewerkstelligen können.“
Ich wollte Sie nur ein wenig ärgern. Bitte erläutern Sie doch kurz, was genau Sie für die HCOB entwickelt haben und woraus die Plattform besteht.
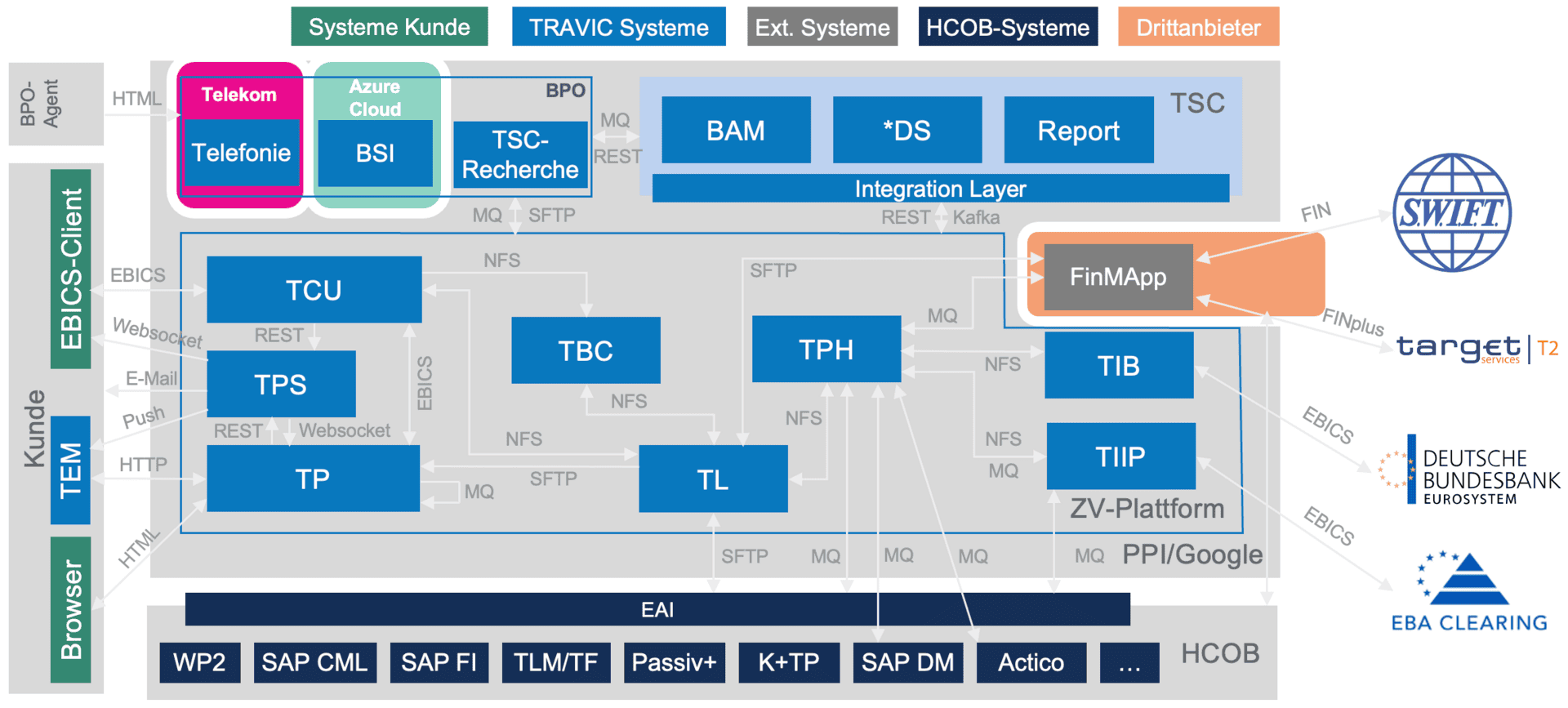
 Dittmer: Im Prinzip besteht der fachliche Teil der Service-Architektur aus vier Gruppen von Applikationen: Die eigentliche Zahlungsverkehrsplattform umfasst die von uns entwickelten Software-Komponenten, um Zahlungsaufträge von den Kunden der Bank anzunehmen, zu verarbeiten und an Clearing-Häuser wie EBA Clearing, Bundesbank oder T2 und SWIFT weiterzugeben. Über eine fachliche Betriebsumgebung organisieren wir das regulatorisch erforderliche Reporting und halten die juristischen Langzeitarchive. Hinzu kommt der Kundensupport, für den wir die Telefonie, das CRM-System und die Recherche für einzelne Transaktionen vorhalten. Schließlich gibt es noch die Anbindungen zu den bankfachlichen Umsystemen, die von der HCOB selbst betrieben werden.
Dittmer: Im Prinzip besteht der fachliche Teil der Service-Architektur aus vier Gruppen von Applikationen: Die eigentliche Zahlungsverkehrsplattform umfasst die von uns entwickelten Software-Komponenten, um Zahlungsaufträge von den Kunden der Bank anzunehmen, zu verarbeiten und an Clearing-Häuser wie EBA Clearing, Bundesbank oder T2 und SWIFT weiterzugeben. Über eine fachliche Betriebsumgebung organisieren wir das regulatorisch erforderliche Reporting und halten die juristischen Langzeitarchive. Hinzu kommt der Kundensupport, für den wir die Telefonie, das CRM-System und die Recherche für einzelne Transaktionen vorhalten. Schließlich gibt es noch die Anbindungen zu den bankfachlichen Umsystemen, die von der HCOB selbst betrieben werden.
PPI AG
So könnte auch eine Architektur aussehen, die von einer Bank „On-Prem“ betrieben wird. Was ist so besonders daran?
 Libiseller: „On Prem“ und Cloud folgen beide völlig unterschiedlichen Prinzipien, wenn es darum geht, Software zu entwickeln und zu betreiben. Ganz klassisch haben auch wir Software wie kleine Monolithen geschrieben und sie über Middleware oder APIs miteinander verbunden. Also eine Applikation für das Clearing, eine für das Online-Banking, und so weiter. Jede dieser Applikationen ließ sich individuell konfigurieren, mit eigenen Datenbankzugängen, Netzwerken und allem, was so eine Applikation eben braucht, um lauffähig zu sein.
Libiseller: „On Prem“ und Cloud folgen beide völlig unterschiedlichen Prinzipien, wenn es darum geht, Software zu entwickeln und zu betreiben. Ganz klassisch haben auch wir Software wie kleine Monolithen geschrieben und sie über Middleware oder APIs miteinander verbunden. Also eine Applikation für das Clearing, eine für das Online-Banking, und so weiter. Jede dieser Applikationen ließ sich individuell konfigurieren, mit eigenen Datenbankzugängen, Netzwerken und allem, was so eine Applikation eben braucht, um lauffähig zu sein.
In der Cloud gilt aber, dass die Betriebsumgebung, bei uns Kubernetes, alle Applikationen steuert und nicht mehr die Applikationen sich selbst.“
Von den Konfigurationen über die Middleware muss deshalb alles aus den Applikationen raus, damit sich diese durch Kubernetes steuern lassen.
Dittmer: Kubernetes arbeitet mit sogenannten Pods. In jedem dieser Pods steckt typischerweise eine fachliche Anwendung in Form von Containern. Jeder Container enthält dabei einen sinnvoll abgegrenzten Anwendungsteil. Die benötigte Middleware steckt ebenfalls in Pods. Kubernetes, das Betriebssystem für die Cloud, steuert die Zugriffe der Anwendungs-Pods auf die Middleware-Pods. Sinnvoll zusammengestellte Pods entlasten so die Betreiber davon, sich überlegen zu müssen ob erforderliche Ressourcen für die gesamte Applikation vorhanden sind oder nicht. Grund dafür sind Entscheidungen, die sich praktisch auf die Ebene der Pods verlagern lassen. Gerade bei Lastspitzen ist das relevant.
Kubernetes stellt auf der Gesamt-Ebene sicher, dass alle erforderlichen Ressourcen allokiert und wenn möglich auch wieder freigegeben werden.“
Und das elastisch, abhängig von der Lastsituation.
1.Technische und fachliche Konfiguration, egal ob abhängig oder unabhängig von der jeweiligen Umgebung, werden außerhalb der Applikationen verwaltet
2.Sensible oder umgebungsspezifische Konfigurationen, wie Credentials oder Zugangsinformationen, werden in einem Vault oder via Sidecar („Hilfscontainer“) für alle Applikationen bereitgestellt.
3.Jede Applikation verfügt mindestens über zwei Operatoren, die das Deployment durchführen (Code und Infrastruktur) und vollautomatisiert aktualisieren (Daten-Migration).
4.Zugänge werden über Ingress- und Egress-Regeln gesteuert, die konfigurativ definiert werden können.
5.Rollen- und Rechte für individuelle Personen und Applikationen sind im IAM geregelt und folgen dem „Prinzip der geringsten Rechte“.
6.Persistente Datenablagen laufen über ein verteilbares Volume, auf das spezialisierte Datenablagen, wie relationale Datenbanken oder Messaging, aufsetzen. Fachliche Applikationszustände werde stets in diesen Datenablagen gespeichert.
7.Logging unterscheidet zwischen technischen Logs für die Monitoring und Alerting-Systeme und fachlichen Logs für eventuell notwendige, manuelle Bearbeitung von einzelnen Vorgängen zu unterscheiden.
Individuelle Container halt – sozusagen ein maßgeschneiderter Anzug für jede Applikation.
Dittmer: Ja. Könnte man so sagen.
Libiseller: Wir können das Bild auch noch etwas größer machen: Ein ganzes Orchester, bei dem jeder einen Maßanzug trägt. Dabei wird jedoch übersehen, dass es nicht nur die Musiker gibt, die auf der Bühne stehen, sondern auch noch die Bühnenbauer, Licht, Akustik, jemanden, der die Instrumente aufbaut. Worauf ich hinaus möchte: Damit ein Orchester klingt, kommt es nicht nur auf die Musiker an.
Bezogen auf Service-Architekturen heißt das, dass nicht nur die fachlichen Applikationen auf der Bühne wichtig sind, sondern auch die Applikationen, die im Hintergrund notwendig sind, um nicht-fachliche Anforderungen zu erfüllen.“
Bei der HCOB laufen ständig zwischen 400 und 500 einzelne Pods in jeder Umgebung. Ungefähr 70 Prozent davon haben nichts mit den fachlichen Applikationen zu tun, sondern stellen die Middleware bereit, erfüllen betriebliche Aufgaben oder eben jene nicht-fachlichen Anforderungen.
O.k. – das ist viel. Woher kommen die nicht-fachlichen Anforderungen und warum treiben sie die zusätzlich benötigten Applikationen in die Höhe?
Dittmer: Neben der Middleware stellen viele der Pods die einheitliche Betreibbarkeit der Anwendungs-Pods sicher. Dazu zählen insbesondere das Logging und Monitoring und weitere querschnittliche Aspekte, wie ein Single Sign On für alle Oberflächen. Wir als Betreiber müssen zudem in der Lage sein, die Einhaltung der mit den Kunden abgeschlossenen Service Level Agreements nachzuweisen. All dies sind also keine Features, die sich direkt in die Applikationen einbauen lassen. Vielmehr müssen zusätzliche Applikationen beschafft oder entwickelt werden, um die gewünschten Funktionen zu realisieren.
Dies treibt die Anzahl der Pods auf der Service-Architektur nach oben und daraus folgt eine höhere Komplexität, die sich wiederum auswirkt auf Aspekte wie die Performanz des Systems oder Disaster Recovery, für deren Umsetzung ebenfalls wieder zusätzliche Pods vorgesehen werden müssen.“
Libiseller: Disaster Recovery ist eines der kritischen Beispiele. Weil Zahlungsverkehr zur KRITIS-relevanten Infrastruktur gehört, gelten strenge Regeln, wie schnell und mit welchem Datenbestand eine total ausgefallene Plattform wieder verfügbar sein muss. Sie müssen sich also genau überlegen, wie sich die fachlichen Applikationen, die Persistenzen, übrige Middleware und eben auch die benötigte Software, um die nicht-fachliche Anforderungen zu erfüllen, verhalten und ob sich die Zielvorgaben damit erfüllen lassen.
Grundsätzlich gilt: Je mehr der Hyperscaler von sich aus mitbringt, desto einfacher wird dieser Balanceakt.“
Lassen Sie uns hier nochmals ins Detail gehen. Warum müssen Sie in der Cloud für Disaster Recovery sorgen und wie funktioniert es?
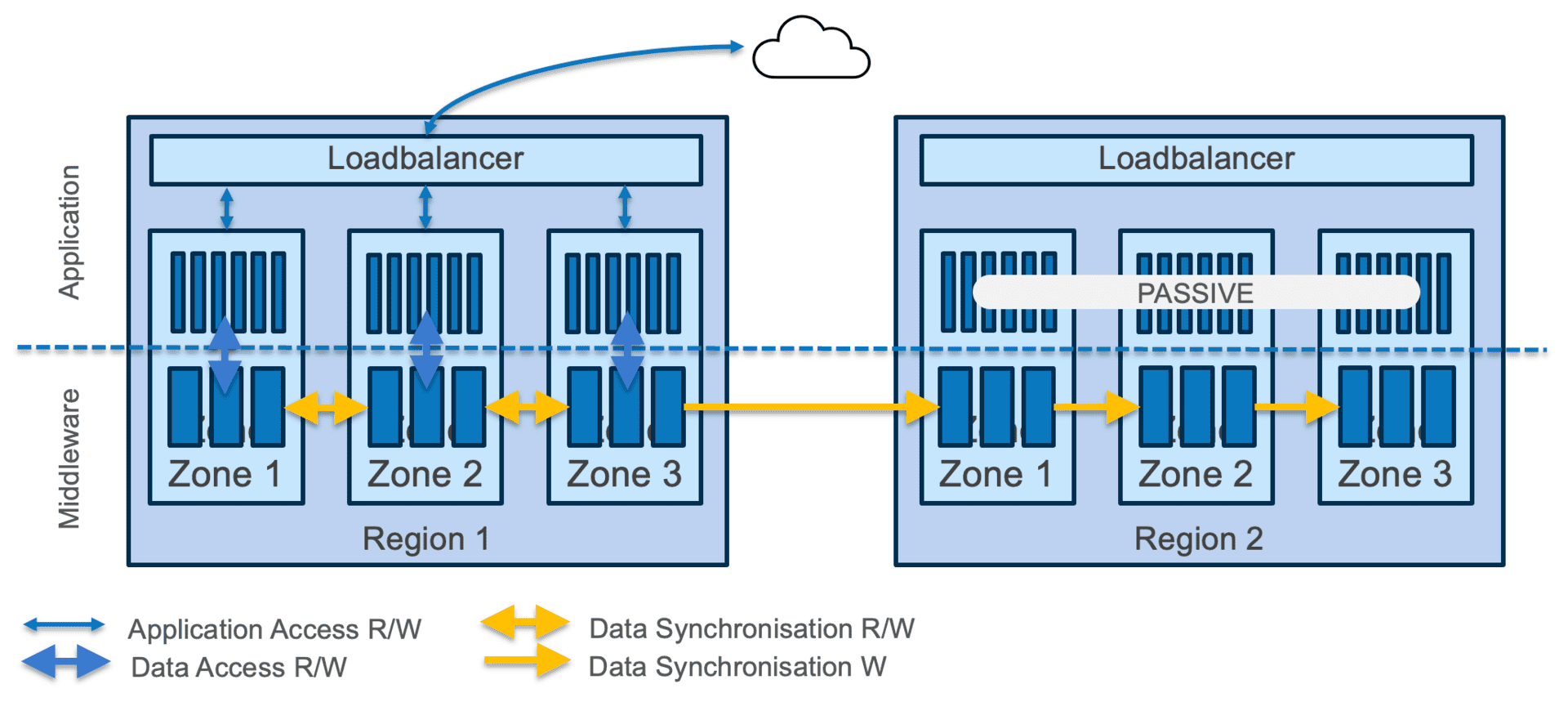
Libiseller: Hyperscaler betreiben physische Rechenzentren, beispielsweise in Frankfurt am Main und in Amsterdam. Innerhalb dieser Regionen richten wir für den Betrieb meist drei Zonen ein, um den Workload zu verteilen und für Ausfallsicherheit zu sorgen. Falls die ganze Region abrupt ausfällt, wegen eines Sturms oder Stromausfalls, müssen Sie aber dafür sorgen, dass die Service-Architektur in einer anderen Region wieder startet und den Betrieb übernimmt. Dafür gibt es zwei Kennzahlen. RPO und RTO, das steht für Recovery Point Objective und Recovery Time Objective. RPO gibt vor, auf welchem Datenbestand aufgesetzt werden muss. RTO beschreibt die Dauer, bis die Service-Architektur wieder verfügbar sein muss. Üblicherweise sind bei kritischen Applikationen sehr kurze Zeitfenster vorgesehen.
Welche Zeiten gelten denn als normal?
Dittmer:
Bei RPO sind wenige Minuten bis zu einer Stunde akzeptabel, bei RTO meist ein paar Stunden.“
Das hängt einerseits von den regulatorischen Vorgaben ab, andererseits aber auch von den Service Level Agreements, die Sie als Dienstleister vereinbaren. Bei einem RPO von 15 Minuten und einem RTO von zwei Stunden, gilt an einem Montagabend um Viertel nach Acht: Alle Daten vor Beginn der Tagesschau müssen wiederhergestellt und verfügbar sein – und vor den Tagesthemen muss die Service-Architektur mit diesen Daten wieder laufen. Darum kommt es auf ein präzises Anforderungsmanagement an, damit gewährleistet bleibt, dass die Service-Architektur insgesamt „disaster-recovery-fähig“ betrieben werden kann.
PPI AG
Okay, verstanden. Glücklicherweise passieren Katastrophen nicht ständig. Wie wirken sich die komplexen Anforderungen auf den Alltag aus?
Libiseller: Technisch betrachtet, gehört vor allem das Staging zum Alltag.
Der Regulator und der gesunde Menschenverstand sehen vor, dass nicht auf derselben Umgebung, welche produktiv im Einsatz ist, gleichzeitig entwickelt oder getestet wird.“
 Tanja Monika Libiseller ist Unit Lead Cloud Technology und Senior Manager bei PPI (Website). Zuvor war sie mehr als fast sieben Jahre als Leiterin Digitalisierung bei der Hypo Vorarlberg tätig und mehr als zehn Jahre bei der Commerzbank. Dort hat sie Großprojekte geleitet und das Multiprojektmanagement für das Corporate Payment verantwortet.
Tanja Monika Libiseller ist Unit Lead Cloud Technology und Senior Manager bei PPI (Website). Zuvor war sie mehr als fast sieben Jahre als Leiterin Digitalisierung bei der Hypo Vorarlberg tätig und mehr als zehn Jahre bei der Commerzbank. Dort hat sie Großprojekte geleitet und das Multiprojektmanagement für das Corporate Payment verantwortet.
 Jens Dittmer ist Entwicklungsleiter und Lead Architect bei PPI (Website). Der studierte Informatiker arbeitet inzwischen seit 30 Jahren bei PPI in verschiedenen Rollen. Er zeichnet verantwortlich für die Architektur des gesamten Software-Portfolios von PPI im Zahlungsverkehr, für im Service betriebene Software (Payments as a Service) und den Cloud-Betrieb.
Jens Dittmer ist Entwicklungsleiter und Lead Architect bei PPI (Website). Der studierte Informatiker arbeitet inzwischen seit 30 Jahren bei PPI in verschiedenen Rollen. Er zeichnet verantwortlich für die Architektur des gesamten Software-Portfolios von PPI im Zahlungsverkehr, für im Service betriebene Software (Payments as a Service) und den Cloud-Betrieb.
Dies geschieht auf eigens dafür vorgesehenen, separaten Umgebungen, den Stages. Es reicht aber nicht aus, einfach dieselben Applikationen eins zu eins auf mehreren Betriebsumgebungen laufen zu lassen. Damit das Ziel erreicht werden kann, dasselbe fachliche Verhalten des Services von der Abnahmeumgebung in die Produktion zu übertragen, sind die fachlichen Konfigurationen auf allen Stages gleich. Die technischen aber unterscheiden sich. Und auch die Umsysteme sind nicht immer vorhanden. Sie werden insbesondere auf den unteren Stages meist durch Platzhalter, so genannte Mocks, simuliert. Je mehr Applikationen und je umfangreicher die Anforderungen, desto schwieriger wird das. Auch wir haben dabei viel Lehrgeld bezahlt und nach dem freundlichen Hinweis unseres Kunden, dass wir mit mehreren Wochen vielleicht nicht besonders schnell deployen, nochmals genau geschaut, wie wir das beschleunigen können, ohne an der Qualität zu sparen.
Und wie?
Dittmer: Automatisieren. Wir arbeiten mit Infrastructure as Code, um die Infrastruktur von der Middleware über die Netzwerkkomponenten bis hin zu Konfigurationen für die jeweils gewünschte Betriebsumgebung wiederholbar bereitzustellen. Eine selbstentwickelte Software, welche wir Stagedive nennen, automatisiert heute den gesamten Lebenszyklus der technischen Service-Architektur.
Wenn man so will, wird dadurch der technische Unterbau, den wir benötigen, um Software in der Cloud zu betreiben, durch Infrastructure as Code wiederverwendbar und durch Stagedive automatisierbar.“
Das hat noch einen weiteren Vorteil: Infrastructure as Code ist wie anderer Quellcode auch in unserem Versionskonstrollsystem hinterlegt. So bleibt vollständig nachvollziehbar, was zu welchem Zeitpunkt auf eine Stage gebracht worden ist.
Können Sie uns konkrete Zahlen nennen, wie schnell Sie inzwischen sind?
Dittmer: Wir deployen eine komplette Zahlungsverkehrsplattform inzwischen in wenigen Stunden statt mehreren Wochen.
Wie viele Leute brauchen Sie, um den Betrieb zu gewährleisten?
Dittmer (überlegt kurz): Insgesamt machen wir mit gut einem Dutzend Kolleginnen und Kollegen, wofür andere vielleicht 30 bis 40 Leute brauchen. Oder, Tanja?
Libiseller: Kommt hin.
Sind die Jobs bei einem so hohen Automatisierungsgrad noch sicher?
Libiseller: Darum geht es nicht. Wir müssen jeden Prozess dokumentieren, auch wie wir in welcher Reihenfolge welche Konfiguration in welche Applikation einspielen. Dies einmal mit Infrastructure as Code abzubilden, garantiert, dass wir regulatorisch sauber arbeiten und auch im Ernstfall nichts schiefgeht. Die Zeit, die wir dadurch sparen, hilft uns woanders, vor allem bei der Software-Entwicklung, weil wir so in der Lage sind, auch kurzfristig eine zusätzliche Entwicklungsumgebung aufzubauen oder parallel an Hotfixes zu arbeiten.
Wir automatisieren nicht in erster Linie aus Kostengründen, sondern um stets dieselbe Qualität zu gewährleisten, wenn wir Betriebsumgebungen aufbauen, und um belegen zu können, dass unsere Service-Architektur tatsächlich genau so funktioniert, wie wir es vorher dokumentiert haben.“
Wie genau gelangen denn Änderungen auf die produktive Umgebung?
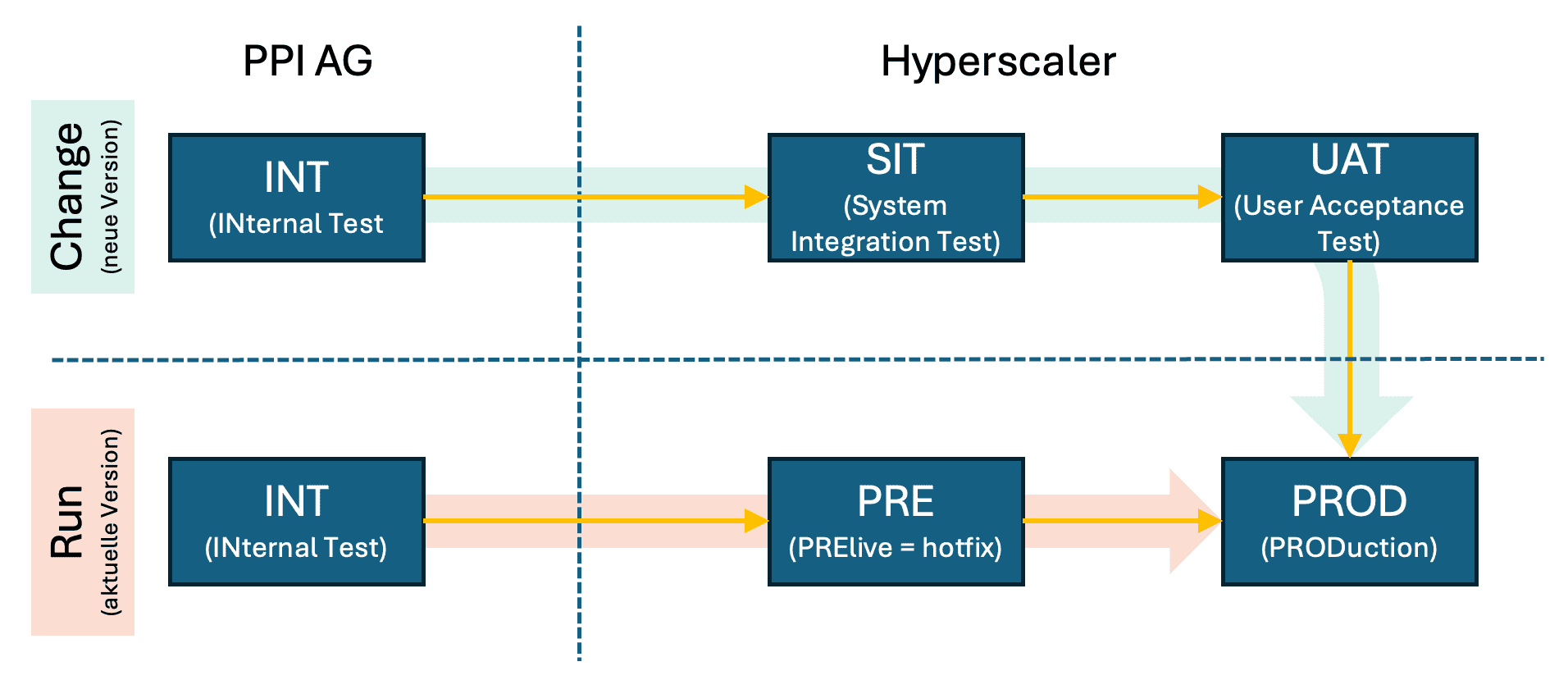
Dittmer: Das kommt darauf an, ob wir eine neue Version mit fachlichen Neuerungen einspielen oder die bestehende Version aktualisieren, beispielsweise durch einen Patch oder ein Infrastruktur-Update.
Neue fachliche Funktionen einzuführen, erfordert immer eine Freigabe durch den Kunden und wird in einem Change-Projekt abgewickelt.“
Dafür starten wir auf einer PPI-internen Umgebung namens INT, kurz für Internal Test. Danach geht es auf den Hyperscaler, wo wir auf der SIT-Stage einen System Integration Test vornehmen, dann auf die UAT, die Stage für den User Acceptance Test, auf der wir die Kundenabnahme durchführen lassen, und schließlich auf die PROD, die produktive Betriebsumgebung. Falls wie etwas an der bestehenden Umgebung aktualisieren müssen, wird das als „Run-Projekt“ durch die Kollegen in der Linie übernommen. Hier folgt auf die INT sofort die PRE oder Pre-Live-Stage, um Patches oder Infrastruktur-Updates regressiv zu testen und danach direkt auf der PROD zu deployen.
PPI AG
Libiseller: Wichtig: PRE muss immer auf den jeweils aktuellen Stand von PROD gebracht werden. Dadurch ermöglichen wir uns, Fehlersituationen nachzuvollziehen, die in der PROD aufgetreten sind. Sonst kann es passieren, dass die Ursachen nicht oder falsch ermittelt werden und Patches nicht wie beabsichtigt wirken.
Wie lange haben Sie gebraucht, um das Ganze zu entwickeln und mit der HCOB-Plattform wirklich cloud-ready zu sein?
Libiseller: Nageln Sie mich jetzt bitte nicht auf einen genauen Tag fest. Das Migrations-Projekt, also die HCOB mit unserer bereits eingeführten Software auf einen Hyperscaler zu bringen, wurde im Juli 2024 unterzeichnet und wir sind um Ostern 2025 live-gegangen. Wie und wann wir was entwickelt oder angepasst haben, lässt sich so genau aber nicht eingrenzen.
Lassen sich die Ideen und Konzepte, um in die Cloud zu kommen, übertragen? Wir haben ja vorhin von Maßanzügen gesprochen. Auf mich wirkt auch die Plattform der HCOB wie eine individuelle Anfertigung.
Dittmer: Das stimmt teilweise.
Falls Banken ihren Zahlungsverkehr auslagern und dafür genau dieses oder ein ähnliches Setup verwenden möchten, dann können wir sie relativ zügig onboarden, von der Integration bei der Bank vielleicht mal abgesehen.“

In Kürze erscheint im FCH-Verlag das Praktikerhandbuch „DORA & Cloud Sicherheit: Praxisleitfaden für Banken & IT-Dienstleister“. Tanja Libiseller ist Co-Autorin für das Kapitel „Hamburg Commercial Bank: Cloud-Transformation im Zahlungsverkehr“. Darin erläutert sie, zusammen mit Nico Frommholz, Head of Payments (HCOB), und Hubertus von Poser, Head of Sales & Consulting Payments (PPI), worauf es bei einer Cloud-Transformation ankommt.
Banken, die selbst ihre Applikationen betreiben und cloud-ready machen wollen, können das Konzept, das wir entwickelt haben, adaptieren. Theoretisch geht das hyperscaler-agnostisch. Doch je nach Applikationszoo und eingesetzter Middleware kann dies zu unterschiedlichem Aufwand führen, um denselben Automatisierungsgrad zu erreichen wie wir mit Stagedive.
Warum wagen sich Ihrer Meinung nach so wenig Unternehmen daran, kritische Software in die Cloud zu heben? Scheuen Sie den Aufwand, den Sie gegangen sind?
Libiseller: Bei KRITIS-relevanter Software steht einfach viel auf dem Spiel.
Wenn wir vom Zahlungsverkehr oder dem Kernbanksystem reden, meinen wir die Herz-Lungen-Maschine einer Bank. Da darf einfach nichts schiefgehen.“
Wie beurteilen Sie Cloud-Transformationen in der aktuellen politischen Lage? Cloud heißt in den meisten Fällen, sich auf US-amerikanische Anbieter zu verlassen – Stichwort: FISA 702.
Dittmer: Rein vom Sicherheitsaspekt her, rate ich jedem Unternehmen dazu, alle Daten zu verschlüsseln und die Schlüssel auch selbst vorzuhalten.
Hold your own key (HYOK) ist nach unserer heutigen Einschätzung eine der wirksamsten Methoden, um den US-Bezug in der eigenen Architektur zu behandeln, falls auf einen der großen Hyperscaler gesetzt wird.“
Libiseller: Souveränität braucht Europa an vielen Stellen, nicht nur bei der Cloud. Die EU möchte auch im Zahlungsverkehr unabhängiger werden von internationalen Netzwerken, auf die wir im Zweifelsfall wenig Einfluss haben. Mit dem digitalen Euro und Wero erleben wir das auch ganz praktisch. Damit müssen die Banken operativ umzugehen lernen und das Beherrschen der Cloud ist der entscheidende Schlüssel dazu.
Frau Libiseller, Herr Dittmer, vielen Dank für das Gespräch.Das Interview führte Joachim Jürschick, ITFM/ aj
Sie finden diesen Artikel im Internet auf der Website:
https://itfm.link/234790


Schreiben Sie einen Kommentar