
Studie: Vertrauen verspielen mit KI – Fehler in der Dateninfrastruktur gefährden Projekte im BFSI-Sektor

Hitachi Vantara

Hitachi Vantara
Noch schlimmer: 84% der Befragten sagen, ein Datenverlust hätte für sie „katastrophale Folgen“. Wurde das System einmal kompromittiert oder liefert Halluzinationen, ist das Vertrauen der Kunden dahin. Verbraucher stellen sich zu Recht die Frage, ob KI ihre Kontodaten versehentlich preisgeben oder ob ein KI-basierter Beratungsservice falsche Finanzentscheidungen anstoßen könnte. Trotzdem setzen viele BFSI-Entscheider vor allem auf traditionelle Maßnahmen wie Firewalls und das Prinzip Hoffnung. Motto „Es wird schon gutgehen“. Dabei gefährdet nur ein einziger Fehler in der Dateninfrastruktur KI-Projekte – und damit das Vertrauen der Kundschaft.
Die wichtigsten technischen Schwachstellen
Welche Setup-Fehler sind typisch? Und wie kann eine durchdachte Architektur – inklusive Data-Governance, Hybrid-Cloud-Strategie und Recovery-Plan – der Branche helfen, KI sicher und effektiv zu nutzen?
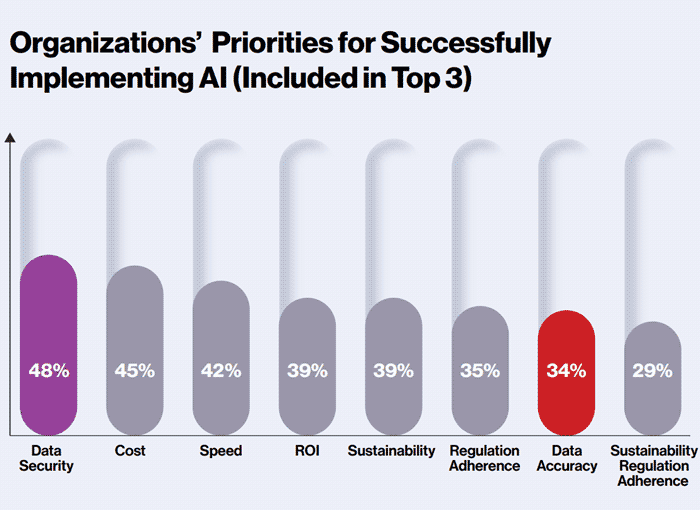
Die Studie gibt an, dass 48% der BFSI-IT-Verantwortlichen „Security“ als höchste Priorität nennen, während „Data Quality“ trotz ihrer zentralen Bedeutung deutlich dahinter rangiert (34%). Hier liegt laut Studie ein Hebel. Scheinbar kleine Unstimmigkeiten in den Daten können sich fatal auswirken. Fehlende oder fehlerhafte Börsenkurse, unvollständige Kundenprofile oder fehlende Compliance-Felder – kann zu falschen KI-Vorhersagen führen.
Hitachi Vantara
Gleichzeitig prüfen laut Studie 27% der befragten BFSI-Organisationen ihre Daten überhaupt nicht auf Qualität oder Accuracy. Das illustriert den Widerspruch aus Wunsch und Wirklichkeit: Man investiert in GPUs und zieht hohe Sicherheitsmauern ein, doch die eigentliche Basis – saubere, verlässliche Daten – bleibt vernachlässigt.
Technische Problemzonen im BFSI: Wo es konkret scheitert
Selbst modernste KI-Setups können fragil sein:
- Hybrid-Cloud-Probleme: Viele BFSI-Organisationen verteilen ihre Daten zwischen On-Prem, Public Clouds und Edge-Standorten. APIs, Firewalls und Netzwerk-Policies sind oft nicht sauber aufeinander abgestimmt. Ergebnis: Silo-Bildung und Engpässe, beispielsweise wenn ein Trainings-Cluster plötzlich nicht mehr auf Echtzeitdaten zugreifen kann.
- Rollback-Desaster: Mehr als 73% der IT-Leader vertrauen darauf, dass Infrastruktur für KI-Projekte keine große Rolle spielt. Entsprechend fehlen Konzepte wie eine „Data-Time-Machine“ oder eine stringente Archivstrategie. Werden Datenbestände korrumpiert, ist dann oft kein „Zurückspulen” mehr möglich. Das bedeutet teure Ausfälle und Probleme mit Aufsichtsbehörden.
- Fehlende Data Governance: Wer verantwortet eigentlich die Daten? Wer hat Zugriffsrechte und wie wird die Korrektheit sichergestellt? 40% der BFSI-Organisationen führen zwar regelmäßige KI-Audits durch, doch ein Viertel hat keine Strategie, um z. B. Modelloutputs nachvollziehbar zu erklären oder IP-Leaks zu verhindern.
- Security vs. Performance: Sicherheit ist zwar laut Studie die höchste Priorität, aber jede zusätzliche Sicherheitsschicht erhöht Latenzen. Ein KI-Cluster, der nonstop auf Security-Overhead wartet, bringt keinen geschäftlichen Nutzen. Hinzu kommt, dass 32% der Befragten eine KI-basierte Attacke als ernsthafte Gefahr für Datenlecks sehen, was Bedarf an weiteren Sicherheitstools auslöst und die Performance weiter drosselt.
Konkrete Konsequenzen für die Infrastruktur
Die Stolpersteine zwingen BFSI-IT-Leiter dazu, ihre Infrastruktur neu zu denken.
- Strukturiertes Datenmanagement: KI-Modelle können nur so gut sein wie ihre Datenbasis. Da 27% der Befragten ihre Datenqualität kaum oder gar nicht überprüfen, ist klar, warum Modelle auf Grund laufen. Eine „Data-Time-Machine“ (Versionierung von Modellen und Daten) ermöglicht jederzeit Rollbacks und verhindert, dass ein Bugfix zum Totalschaden führt.
- Hybrid-Cloud ohne Chaos: Statt blindem „Cloud-Hopping“ braucht es gut definierte APIs, Netzwerk-Policies und Kubernetes-Orchestrierungen, damit Latenzen kalkulierbar bleiben. Failover-Konzepte sind Pflicht, damit ein regionales Problem nicht das gesamte System abschießt.
- Performante Infrastruktur: Wer GPU-Cluster betreibt, sollte Flaschenhälse bei Storage und Netzwerk verhindern – etwa durch NVMe-Flash, GPUDirect Storage oder High-Speed-Backbones. So werden CPU-Engpässe reduziert und Trainingsdaten effizient bewegt.
- Klare Governance und Security-Strategien: Encryption-at-Rest, Zugriffsmanagement, Logging und automatisches Tiering (z. B. für Archivdaten) sind laut Studie gerade im BFSI essenziell. 84% der BFSI-Entscheider erachten Datenverluste als „katastrophal“ – entsprechend müssen Verschlüsselung und Wiederherstellungsprozesse schon in der Architektur eingeplant sein.
„AI kills trust“ – wirklich?
Laut der Studie arbeiten 69 % der Befragten bereits an konkreten KI-Anwendungsfällen. Damit diese erfolgreich umgesetzt werden können, müssen sie genau wissen, welche Daten dafür genutzt werden dürfen – und in welchem Umfang. Ein erster Schritt ist die systematische Erfassung sämtlicher Datensätze, inklusive Eigentümer, Sensibilität und Zugriffsrechten. Eine revisionierbare Speicherung von KI-Modellen, Datenversionen und Trainingsläufen ist hier ein Muss, denn nur so lassen sich bei Datenausfällen oder Modellfehlern schnell stabile Zustände wiederherstellen und die Datengrundlage der KI-Modelle nachweisen.

Hitachi Vantara
Die Gefahr eines Vertrauensverlustes: 32% sorgen sich, dass KI-gestützte Angriffe zu Datenlecks führen. Falsche Kreditentscheidungen oder manipulierte Börsendaten können Institutionen ruinieren, deren Hauptkapital das Vertrauen der Kunden ist.
Doch es wäre zu kurz gegriffen, zu sagen, KI zerstöre pauschal Vertrauen. Im Gegenteil: 40% der BFSI-Organisationen auditieren ihre Modelle bereits regelmäßig, um Outputs erklärbar zu machen und Regulierungsvorgaben einzuhalten. Richtig eingesetzt, bietet KI unschlagbare Vorteile – von schneller Betrugserkennung bis hin zu personalisierten Angeboten. Wer hingegen versucht, KI „quick & dirty“ einzuführen, wird mit Reputations- und Compliance-Schäden zahlen.

Hitachi Vantara
Die Vorteile von KI in der BFSI überwiegen
Die gute Nachricht ist: Die Regulatorik gibt einen Rahmen vor, um KI sauber und sicher zu betreiben. Wichtig ist, dass BFSI-Unternehmen nicht nur auf Security, sondern auch auf Datenqualität, Infrastruktur-Redundanz und branchenspezifische Vorgaben achten.
Wichtig ist, dass die Hybrid-Cloud nicht zum Datengrab verkommt. Dazu ist es sinnvoll, die wichtigsten Deployments und Audits zu automatisieren und regelmäßig die Belastungsgrenzen der Sicherheitsarchitektur zu testen. 67% der befragten BFSI-Unternehmen nutzen dabei externe Partner, um Lücken in Skalierbarkeit und Security zu schließen.
Die Hitachi-Vantara-Studie „“ können sie hier gegen Abgabe Ihrer Kontaktdaten heruterladen.
Sie finden diesen Artikel im Internet auf der Website:
https://itfm.link/226661


Schreiben Sie einen Kommentar