

Voice-AI wird in Banken scheitern – wenn man sie wie ChatGPT baut

von Horst Christian Wagner, Bestfriend
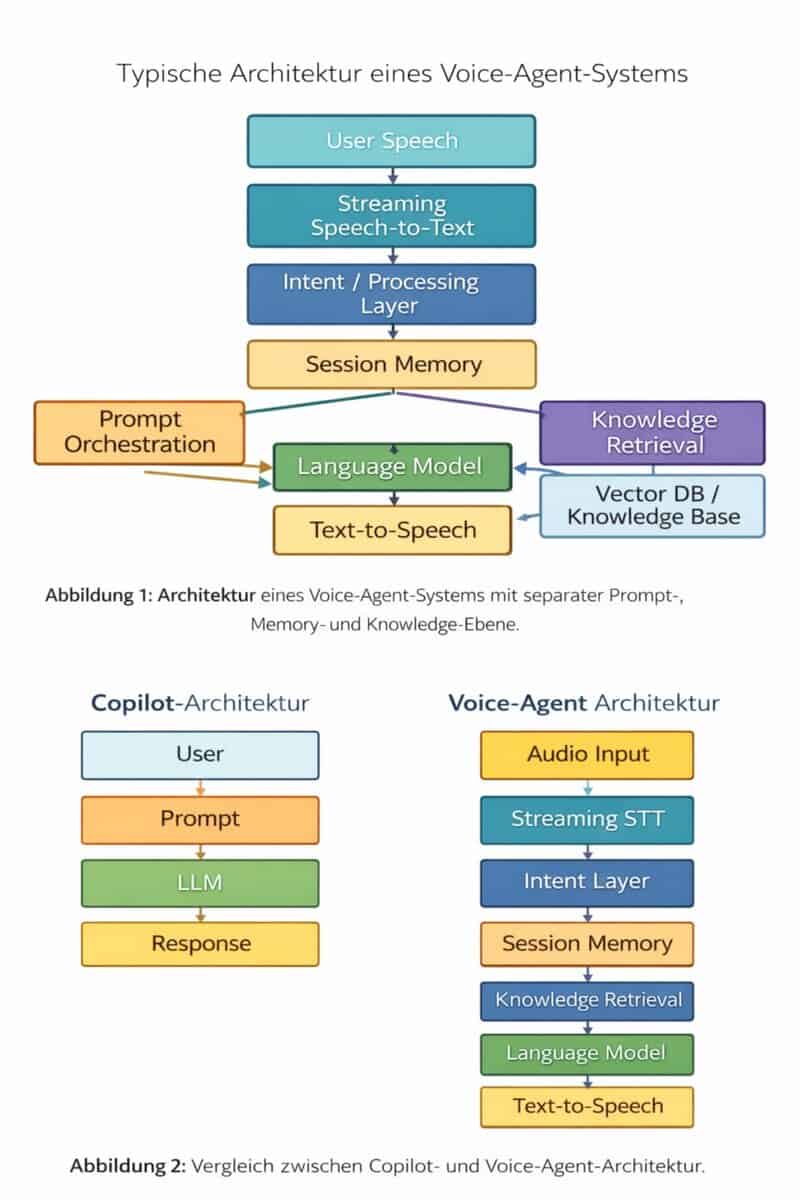
Der derzeitige Standardansatz für generative KI basiert auf der klassischen Copilot-Architektur: Ein Nutzer formuliert eine Anfrage, ein großes Sprachmodell verarbeitet den Prompt, und das System liefert eine Antwort. Für textbasierte Anwendungen funktioniert dieses Modell erstaunlich gut. Für Voice-AI ist diese Architektur jedoch strukturell ungeeignet.
Das Problem beginnt bei der Latenz. In klassischen LLM-Systemen wird der gesamte Prompt verarbeitet, bevor eine Antwort generiert wird. Selbst optimierte Modelle benötigen dafür mehrere hundert Millisekunden bis Sekunden. Für eine natürliche Sprachinteraktion ist das zu langsam. Menschen erwarten Gesprächsreaktionen im Bereich von 200 bis 400 Millisekunden. Alles darüber wirkt bereits künstlich. Hinzu kommt, dass Voice-Systeme völlig andere Datenströme erzeugen als textbasierte Interfaces. Ein einziger Sprachdialog kann schnell 30 bis 60 Sekunden Audio enthalten. Nach Transkription entstehen daraus mehrere tausend Tokens Kontext. Wird dieser Kontext vollständig an ein Sprachmodell übergeben, explodieren sowohl die Kosten als auch die Latenz.
Viele der derzeit getesteten Copilot-Systeme ignorieren dieses Problem. Sie behandeln Voice lediglich als zusätzliche Eingabeschicht: Audio wird transkribiert, als Textprompt an ein LLM gesendet und anschließend wieder synthetisiert ausgegeben. Technisch funktioniert das – aber die Architektur skaliert schlecht.
Eine produktive Voice-AI benötigt eine Pipeline, die deutlich näher an klassischen Echtzeitsystemen liegt als an Chatbots.“
Typischerweise besteht eine solche Pipeline aus mehreren spezialisierten Komponenten:
Audio Input
Streaming Speech-to-Text
Intent Layer
Session Memory
Sprachmodell
Text-to-Speech
Entscheidend ist dabei die Streaming-Verarbeitung. Während der Nutzer spricht, muss das System bereits mit der Verarbeitung beginnen. Moderne Speech-to-Text-Systeme liefern kontinuierliche Transkriptionsfragmente. Diese können parallel analysiert werden, bevor der gesamte Satz beendet ist.
Ebenso wichtig ist ein explizites Session-Memory.“
Klassische LLM-Ansätze speichern Kontext ausschließlich im Prompt. Bei längeren Gesprächen wächst dieser Kontext schnell auf mehrere tausend Tokens. Für Voice-Systeme ist das ineffizient. Stattdessen wird Kontext in einer separaten Memory-Struktur gespeichert und nur selektiv in Modellaufrufe eingebunden.
Prompt-Orchestrierung und Knowledge Layer
Ein häufig unterschätzter Bestandteil moderner Agentensysteme ist die Steuerungsebene des Modells selbst. In vielen Proof-of-Concept-Projekten besteht der Prompt lediglich aus einer statischen Systemanweisung. Für produktive Anwendungen ist das unzureichend.
In der Praxis benötigt jeder spezialisierte Agent eine definierte Steuerungsstruktur, die aus mehreren Komponenten besteht:
System Prompt
beschreibt Rolle, Verhalten und Entscheidungslogik des Agenten
Kontextlayer
enthält Sitzungsinformationen, Nutzerhistorie und Gesprächszustand
Knowledge Layer
stellt domänenspezifisches Fachwissen bereit
Dieser Knowledge Layer wird typischerweise über Retrieval-Mechanismen realisiert, etwa Vektor-Datenbanken oder strukturierte Wissensbasen. Anstatt das gesamte Fachwissen im Prompt zu speichern, werden relevante Informationsfragmente dynamisch zur Laufzeit abgerufen und in den Modellkontext eingebunden.
Gerade in regulierten Branchen ist diese Trennung entscheidend. Fachwissen kann versioniert, überprüft und auditiert werden, ohne die Modelllogik selbst zu verändern. Gleichzeitig lässt sich damit vermeiden, dass große Mengen statischen Wissens permanent im Prompt enthalten sind, was Tokenkosten und Latenz erhöht.
Bestfriend
In der Praxis entsteht dadurch eine dreistufige Architektur:
Steuerungsebene (Prompt-Orchestrierung)
definiert Rolle und Verhalten des Agenten
Wissensebene (Retrieval / Knowledge Base)
liefert fachliche Inhalte
Modellebene (LLM)
generiert die Antwort
Diese Trennung erlaubt es, spezialisierte Agenten für unterschiedliche Aufgaben zu betreiben, ohne das zugrunde liegende Modell austauschen zu müssen. Für Unternehmen bedeutet das eine deutlich bessere Kontrolle über Verhalten, Kosten und Compliance von KI-Systemen.
Ein weiterer kritischer Punkt ist das Kostenmodell.
Während ein Chatbot häufig nur einzelne Fragen beantwortet, können Voice-Systeme mehrere Minuten durchgehende Interaktion erzeugen.“
Jede dieser Interaktionen erzeugt kontinuierliche Modellaufrufe, Transkriptionskosten und TTS-Generierung. Ohne Token-Management und Session-Begrenzung entstehen schnell unkontrollierbare Betriebskosten.
Für Banken und Versicherer kommt ein zusätzlicher Faktor hinzu: regulatorische Anforderungen. In BaFin- oder FINMA-regulierten Umgebungen müssen Systeme nachvollziehbar sein. Das betrifft Logging, Auditability und teilweise auch die Reproduzierbarkeit von Entscheidungen. Klassische Copilot-Architekturen bieten hier kaum Lösungen. Viele Modelle arbeiten probabilistisch ohne deterministische Reproduzierbarkeit.
Für Compliance-relevante Prozesse müssen daher zusätzliche Schichten implementiert werden, etwa Event-Logging, Replay-Mechanismen oder strukturierte Entscheidungsbäume vor Modellaufrufen.“
Voice-AI wird deshalb langfristig nicht als Erweiterung bestehender Chatbots entstehen, sondern als eigene Architekturklasse. Systeme werden stärker an Streaming-Architekturen, Event-Bussen und dedizierten Session-State-Systemen orientiert sein.
Warum generische Foundation Models allein nicht ausreichen
Ein weiteres Missverständnis in vielen KI-Projekten besteht darin, dass große Foundation Models als vollständige Lösung betrachtet werden. In der Praxis übernehmen diese Modelle jedoch nur einen Teil der Gesamtarchitektur.
Foundation Models sind hervorragend darin, Sprache zu generieren und semantische Zusammenhänge zu erkennen. Sie besitzen jedoch kein strukturiertes Domänenwissen über spezifische Unternehmensprozesse oder regulatorische Anforderungen.
Ohne zusätzliche Architekturkomponenten entstehen daher Systeme, die zwar sprachlich überzeugend wirken, aber fachlich unpräzise oder inkonsistent reagieren.“
In der Finanzwirtschaft ist das besonders problematisch. Antworten müssen nicht nur plausibel sein, sondern fachlich korrekt, nachvollziehbar und auditierbar.
Deshalb entstehen derzeit zunehmend Architekturen, in denen Foundation Models nur eine Komponente innerhalb eines größeren Systems darstellen.“
 Horst Christian Wagner arbeitet seit über 30 Jahren an digitalen Plattform- und Systemarchitekturen. Sein Schwerpunkt liegt auf KI-Agent-Systemen, Voice-Interaktion und Wissensarchitekturen für datenintensive Anwendungen. In verschiedenen Projekten untersucht er derzeit skalierbare Architekturen für Echtzeit-Voice-AI und personalisierte KI-Agenten.
Horst Christian Wagner arbeitet seit über 30 Jahren an digitalen Plattform- und Systemarchitekturen. Sein Schwerpunkt liegt auf KI-Agent-Systemen, Voice-Interaktion und Wissensarchitekturen für datenintensive Anwendungen. In verschiedenen Projekten untersucht er derzeit skalierbare Architekturen für Echtzeit-Voice-AI und personalisierte KI-Agenten.Für IT-Abteilungen bedeutet das eine wichtige strategische Erkenntnis: Der Wettbewerbsvorteil entsteht nicht durch das verwendete Foundation Model, sondern durch die Systemarchitektur, die dieses Modell kontrolliert und mit domänenspezifischem Wissen verbindet.
Für IT-Architekten in Banken ergibt sich daraus eine klare Konsequenz: Wer Voice-AI plant, sollte sie nicht als Copilot-Funktion betrachten. Es handelt sich um ein eigenständiges Systemdesign mit eigenen Anforderungen an Infrastruktur, Kostenkontrolle und Echtzeitverarbeitung.
Die Zukunft von Voice-AI liegt nicht im nächsten Sprachmodell – sondern in der Architektur der Systeme, die es einsetzen.
Experimentelle Voice-Agent-Systeme
Im Rahmen mehrerer Entwicklungsprojekte untersucht Wagner derzeit zwei unterschiedliche Klassen von KI-Agent-Systemen: eine Voice-Agent-Plattform für Unternehmensanwendungen sowie eine experimentelle Companion-AI für dialogorientierte Mensch-KI-Interaktion. Ziel dieser Projekte ist es, skalierbare Architekturen für Echtzeit-Sprachdialoge zu entwickeln. Horst Christian Wagner
Sie finden diesen Artikel im Internet auf der Website:
https://itfm.link/241755


Schreiben Sie einen Kommentar