Individuelle Datenverarbeitung (IDV): BaFin-konformer Umgang mit Lösungen, die nicht der Definition genügen
Beckmann & Partner Consult
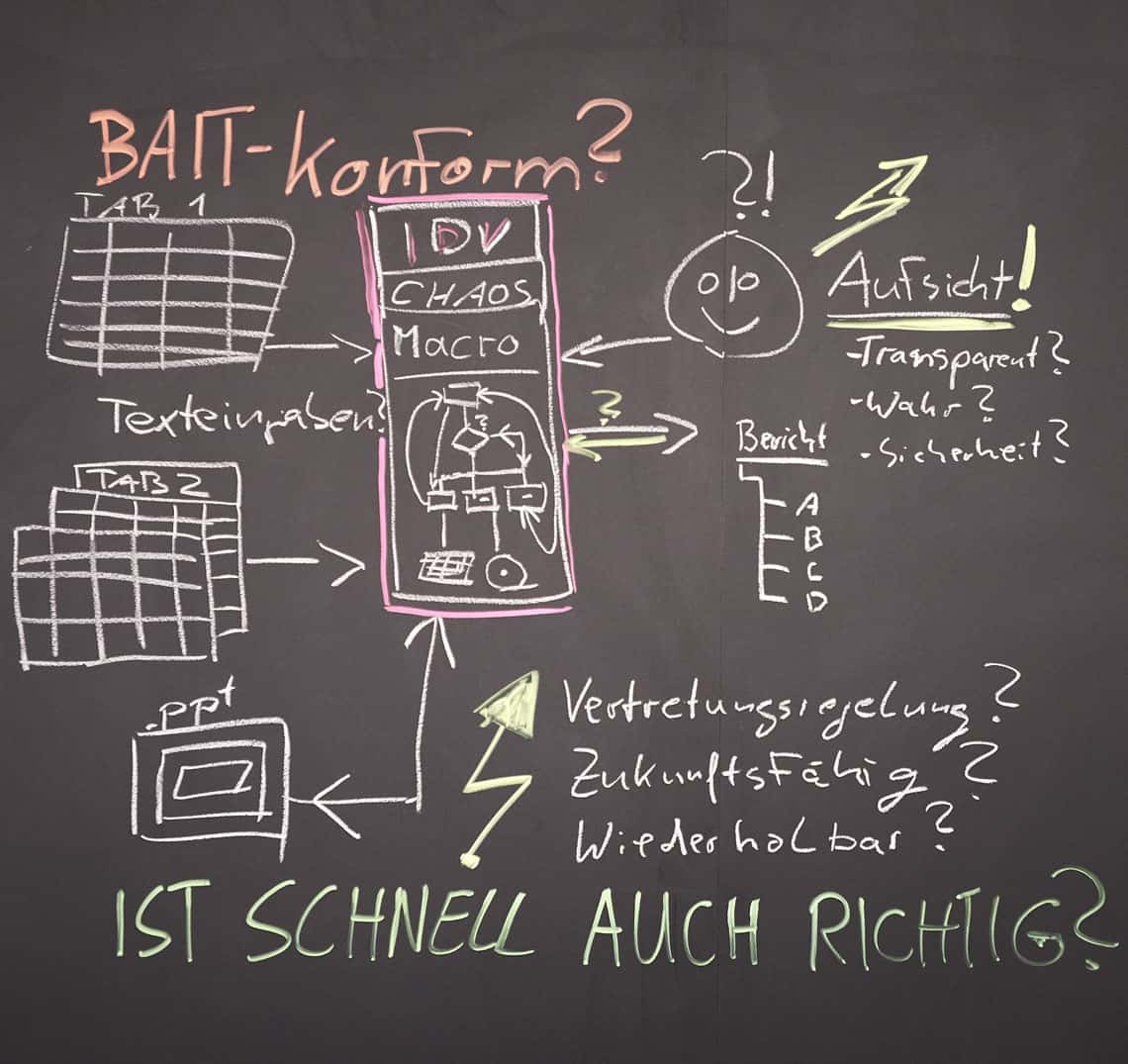
IDV-Anwendungen á la Excel & Co. gibt es wie Sand am Meer – samt Spannungsfeld zwischen Sicherheit & Schnelligkeit. Die BaFin hat allen Grund dazu, ein waches Auge auf IDV-Anwendungen zu richten – aber: Wie müsste der Umgang mit IDV für alle Beteiligten optimal organisiert sein? Der Vorschlag: Mit einem ‚Documentation Tree‘ können auch IDV-Anwendungen BaFin-konform sein.
von Dr. rer.pol. Bruno Kaiser und Matthias Wieking, Beckmann & Partner Consult
Individuelle Datenverarbeitung (IDV) kommt in Banken immer dann zum Tragen, wenn der Einsatz einer zum Beispiel betriebswirtschaftlichen Standard-Software (organisatorisch verbindlich geregelte Datenverarbeitung, kurz ODV) zu komplex, zu teuer oder einfach zu zeitintensiv ist.1
Eine mögliche Definition lässt sich aus den Anforderungen an eine Standard-Software herleiten. Das Bundesministerium für Finanzen (BMF) hat in seinen Erörterungen der Grundsätze zur ordnungsmäßigen Führung und Aufbewahrung von Büchern, Aufzeichnungen und Unterlagen in elektronischer Form sowie zum Datenzugriff (GoBD) Anforderungen an ein Software-System gestellt.2 So gelten zum Beispiel die Grundsätze der Wahrheit, der Klarheit und fortlaufenden Aufzeichnung (siehe unter 3.2):
1. Vollständigkeit (siehe unter 3.2.1),2. Richtigkeit (siehe unter 3.2.2),
3. zeitgerechte Buchungen und Aufzeichnungen (siehe unter 3.2.3),
4. Ordnung (siehe unter 3.2.4),
5. Unveränderbarkeit (siehe unter 3.2.5)
Allein die Grundsätze der Wahrheit umzusetzen, erhöht die Komplexität eines Softwareproduktes um ein Vielfaches.
Betrachtet man nun noch weitere Anforderungen an eine betriebswirtschaftliche Software wie Release-Wechsel, Updates, die Vergabe von Zugriffsrechten oder Parametrisierungen und die Vollständigkeit und Richtigkeit der eingegebenen Daten, wird deutlich, warum die Revision und die Aufsicht ein waches Auge auf IDV haben: Denn hier sind die Anforderungen häufig nicht vollständig umgesetzt. Die Anforderungen an IDV hat die BaFin mit ihrem Rundschreiben 09/2017 konkretisiert:
„Die Anforderungen aus AT 7.2 sind auch beim Einsatz von durch die Fachbereiche selbst entwickelten Anwendungen (Individuelle Datenverarbeitung – „IDV“) entsprechend der Kritikalität der unterstützten Geschäftsprozesse und der Bedeutung der Anwendungen für diese Prozesse zu beachten. Die Festlegung von Maßnahmen zur Sicherstellung der Datensicherheit hat sich am Schutzbedarf der verarbeiteten Daten zu orientieren.“ (Rundschreiben 09/2017 (BA) vom 27.10.2017 – Seite 17)
Wo wird IDV eingesetzt?
Stellen sie sich bitte die folgende Situation vor: Aus dem Wertpapierhandel erreicht den Projektausschuss einer Bank die Anforderung, innerhalb von einem Monat ein neues Wertpapierprodukt handeln zu können. Dieses Produkt besteht aus verschiedenen Komponenten, die teilweise aus dem Bereich Kredit und teilweise aus dem Bereich Wertpapier hervorgehen. In einer Vorstudie hat man festgestellt, dass eine komplette ODV-Umsetzung in den Bank-Kernsystemen 500 Personentage kosten würde und im aktuellen Jahr nicht umgesetzt werden kann, da das Projektportfolio bereits zu 25 % überplant ist.
Der Fachbereich hat ausgerechnet, dass er durch Einsatz des Produktes innerhalb von fünf Monaten die erste Million verdienen könnte. Das ist in der Tat im Verhältnis zum Bank-Projektportfolio wenig, aber für die Abteilung selbst ein riesiger Erfolg.
 Dr. rer.pol. Bruno Kaiser ist seit 25 Jahren Spezialist für Risikomanagement, sowohl für Marktpreis- als auch für Adressenausfallrisiko. Eine besondere Passion hat er für die Automatisierung von IDV-Lösungen mittels Access und Lua und lebt diese Passion in Projekten für Beckmann & Partner aus.
Dr. rer.pol. Bruno Kaiser ist seit 25 Jahren Spezialist für Risikomanagement, sowohl für Marktpreis- als auch für Adressenausfallrisiko. Eine besondere Passion hat er für die Automatisierung von IDV-Lösungen mittels Access und Lua und lebt diese Passion in Projekten für Beckmann & Partner aus.
 Matthias Wieking ist Geschäftsführer und Gesellschafter bei Beckmann & Partner Consult. Er ist verantwortlich für die Kundengewinnung und Finanzen. Seit 1995 arbeitet der Bankkaufmann und Diplom-Betriebswirt in Projekten mit Schwerpunkt im Wertpapiergeschäft mit verschiedenen Banken zusammen. Wieking will mit pragmatischen Mitteln Mehrwerte schaffen, die nicht nur den aufsichtsrechtlichen Anforderungen genügen, sondern den Kunden echten Nutzen stiften.
Matthias Wieking ist Geschäftsführer und Gesellschafter bei Beckmann & Partner Consult. Er ist verantwortlich für die Kundengewinnung und Finanzen. Seit 1995 arbeitet der Bankkaufmann und Diplom-Betriebswirt in Projekten mit Schwerpunkt im Wertpapiergeschäft mit verschiedenen Banken zusammen. Wieking will mit pragmatischen Mitteln Mehrwerte schaffen, die nicht nur den aufsichtsrechtlichen Anforderungen genügen, sondern den Kunden echten Nutzen stiften.
Was passiert nun? Warum wird IDV eingesetzt?
Die Million will niemand liegen lassen. Also werden Workarounds geplant und Excel-Lösungen kreiert. Einer der Mitarbeiter im Fachbereich hat sich privat in Excel eine Musikverwaltung erstellt und so tiefere Excel-Makro-Kenntnisse erlangt. Genau dieser Kollege Namens „Herr Excelfit“ hat die schnelle Lösung – allerdings ohne zum Beispiel die GoDV auch nur zu kennen.
Er erzeugt ein, zwei, drei Makros. Er importiert täglich über die Zwischenablage des PCs Daten aus dem Handelssystem. Seine Ergebnisse bereitet er in PowerPoint auf und der Vorstand bekommt täglich einen Hochglanzbericht, der sogar besser aussieht als die normale Liste aus der Standard-Software. Das macht Lust auf mehr.
Wo liegen denn die Vorteile?
Losgelöst von allen Projektmanagementverfahren und IT-Vorgaben hat sich der Fachbereich eine Lösung geschaffen, die es ihm ermöglicht, schnell die oben genannte Million zu verdienen. Er bekommt eine Lösung, die absolut auf seine Bedürfnisse zugeschnitten ist. Dadurch, dass der Anforderer und der Umsetzer in Personalunion unterwegs sind, gibt es nur wenige Diskussionen, der Abstimmungsbedarf ist ebenfalls extrem gering. Es entstehen keine Projektkosten, denn die Lösung entsteht „so nebenbei“. Für die Lösung fallen auch keine zusätzlichen Lizenzkosten an, denn MS-Office ist ja eh da. Die „Time to Market“ ist extrem kurz. Am Markt wird die schnelle Produkteinführung mit Begeisterung aufgenommen. Der ROI ist riesig. Schneller kann man kein Geld verdienen. In der Folge wird das „Produkt“ kontinuierlich weiterentwickelt, neue Features eingebaut und der eine oder andere kleine Fehler behoben.
Wo liegen die Risiken?
Denken wir das Szenario einmal ein paar Wochen weiter. Der Tagesprozess ist inzwischen etabliert, das Geschäft läuft. Auf der Basis einer Kundenreklamation wird ein Fehler festgestellt. Das zu Grunde liegende Geschäft stammt aus der „ersten Stunde“ der Produkteinführung. Der Kollege „Herr Excelfit“ hat Urlaub oder – schlimmer noch – die Abteilung verlassen. Für die Dokumentation des Geschäftes liegen natürlich alle Belege und Dokumente vor. Warum das Geschäft aber nun so und nicht anders abgebildet wurde, ist unklar.
Dadurch, dass keine Konzepte oder Product-Backlogs erstellt wurden, sind die einzelnen Entwicklungsschritte nicht mehr nachvollziehbar. Kollege „Excelfit“ ist Autodidakt – seine Art der Entwicklung von Makros oder kleinen VBA-Modulen spiegelt das wider, was er in dem Moment für richtig hielt. Die Dokumentation seines Tuns ist weder innerhalb der Lösung noch in Form eines Handbuches erfolgt. Andere Mitarbeiter in der Abteilung sind bzw. waren froh, dass sie nicht noch ein weiteres Thema bearbeiten müssen. Im Ergebnis ist genau das entstanden, was eigentlich alle vermeiden wollten: Ein Kopfmonopol. Die Einarbeitung in solche Lösungen erfolgt oft dadurch, dass sie ein zweites Mal entwickelt werden müssen.
Die BaFin hat in diesem Moment viele gute Gründe, mit der Umsetzung der Lösung unzufrieden zu sein. Die Folge werden bei einer Prüfung auf jeden Fall Monita sein. So hat die Bank neben dem prozessualen Problem auch noch ein aufsichtsrechtliches. Denn die Forderungen der BaFin sind eindeutig: „Aus Sicht der BaFin ist es sinnvoll, IDV-Anwendungen, die die Fachbereiche entwickeln beziehungsweise betreiben, in Risikoklassen einzuteilen. Dies schafft institutsintern Transparenz über die Risiken, die aus dem Umgang mit diesen Anwendungen resultieren. Darüber hinaus erwartet die Aufsicht, dass das Institut alle IDV-Anwendungen, die insbesondere für bankgeschäftliche Prozesse, für die Risikosteuerung und -überwachung oder für Zwecke der Rechnungslegung Bedeutung haben, in einem zentralen Register führt.“ 4
Wo ist das eigentliche Problem?
In dem oben dargestellten – zugegeben erdachten – Fallbeispiel wird klar, wo die Probleme liegen: Auf Grund der schnellen Lösung erfolgt eben keine Risikoklassifizierung, die Dokumentation ist mangelhaft und zu allem Überfluss fehlt schlichtweg die Kompetenz, das Software-Produkt weiterzuentwickeln.
Ist die Angst vor der Nicht-Beherrschbarkeit somit berechtigt? Müssen die Fachbereiche Quick-Wins durch zunächst schnelle IDV-Lösungen abschreiben? Wie könnte das Dilemma gelöst werden?
Im Wesentlichen liegen die Ansätze für eine Lösung in drei Bereichen:
1. Kompetenz der Mitarbeiter vom Typ „Herr Excelfit“2. Einschränkung der flexiblen Nutzung von MS-Office Produkten
3. Organisation und Dokumentation von IDV
Kompetenzen
Die Mitarbeiterentwicklung und Ausbildung muss so gestaltet werden, dass „Herr Excelfit“ die Konsequenzen seines Handelns erkennt und dass er Verständnis dafür entwickelt, warum die klassische IT (ODV) so handelt, wie sie ihre Software-Produkte entwickelt. Er muss Vorgehensweisen und Verfahren kennen. Er muss Kenntnisse der IT-Sicherheit erwerben, um beurteilen zu können, in welcher Schutzklasse seine Anwendung einzuordnen ist. Seine technische Ausbildung muss so weit entwickelt werden, dass er IDV-Lösungen schafft, die durch Dritte weiterentwickelt werden können.
Eine klassische Berufsbezeichnung für diese Kompetenzen gibt es nicht. Hier ist die Kreativität und Innovationskraft der Personalabteilungen gefragt. „Programmieren ist das neue Englisch“, so drückte es Trendforscher Torsten Rehder während seiner Live-Demonstration „The World in 2025“ auf dem Schweizer Strategietag 2017 am 12. Januar in Zürich aus.
MS-Office Produkte
Nicht alles, was möglich ist, muss der Anwender auch nutzen. Weniger ist manchmal mehr. Hier gilt es – am besten unternehmensweit – eine Einigung zu erzielen, welche Komponenten im Unternehmen eingesetzt werden sollen und auf welche Funktionen gegebenenfalls verzichtet wird. Sollen Makros oder VBA-Module erstellt werden? Werden Reports in Access, in Excel oder mittels PowerPivot erstellt? Und wie ist der grundsätzliche Aufbau von Modulen? Welche Datenquellen werden auf welche Weise genutzt? Mit Access/Excel ist es möglich, externe Datenquellen zu nutzen. Wie soll verhindert werden, dass die Datenquelle irgendein Cloud-Speicher ist? Auch an dieser Stelle müssen sich die Unternehmen Gedanken machen, in welchem Rahmen sich der IDV-Ersteller bewegen darf und soll. Eine Unternehmens-Guideline ist zwingend notwendig.
Organisation und Dokumentation
IDV darf und soll genutzt werden. Sie ist auch nicht zu verhindern. Und das soll sie auch nicht. Aber – und das ist der Wunsch der Aufsicht – IDV muss organisiert sein. Es muss transparent sein, wo IDV anfängt, wo und wofür sie genutzt wird. Ändern sich Datenstrukturen in den Core-Systemen einer Bank, muss klar sein, wo sich diese Änderungen in IDV-Anwendungen niederschlagen. Genauso, wie für Core-Systeme Verantwortlichkeiten geregelt werden, so müssen diese Informationen auch für IDV hinterlegt werden. Um zu vermeiden, die gleiche Information auf unterschiedliche Weise in unterschiedlichen Fachbereichen zu erzeugen, ist es notwendig, den Applikationskatalog zu pflegen.
Fazit IDV – Mit Organisation & Steuerung zu genießen
Entscheidend ist die „Time To Market“. IDV ist schneller umgesetzt und aus den Fachbereichen heraus machbar. Auf sie zu verzichten würde bedeuten, auf Chancen zu verzichten. Allerdings gilt es immer dann, wo IDV als Surrogat für die klassische DV eingesetzt wird, besondere Vorsicht walten zu lassen. IDV muss organisiert sein. IDV darf kein Wildwuchs sein. IDV muss – abhängig von der Kritikalität – in ODV überführt werden. Wie so häufig gilt auch hier in Anlehnung an Paracelsus: Sola dosis facit venenum (Nur die Dosis macht das Gift)!
Für das IDV-Problem hat Beckmann & Partner Consult eine Lösung, der die wesentlichen Informationen in einer IDV-Landschaft transparent dokumentiere: den Documentation Tree.

Beckmann & Partner Consult
So sei es zum Beispiel mit den Documentation Trees möglich festzustellen, welche Information in welcher IDV verwendet wird und wer für diese Information verantwortlich ist. Das Ganze funktioniert analog einer „Cross Reference“ im Bereich der Programmierung. Eine weitere Funktion ist, fachliche Prozess- bzw. Verarbeitungsschritte analog eines Workflows zu dokumentieren (z.B. das tägliche Bearbeiten einer Excel-Liste, das Umkopieren von Dateien etc.)
Das Produkt Documentation Tree (Beckmann & Partner Consult) gebe dem Anwender die Möglichkeit, in einfacher Weise Zusammenhänge zwischen Verarbeitungsschritten in einer Datenbank, über mehrere Datenbanken hinweg, zwischen verschiedenen Programmen und auch in Form von manuellen Schritten in einer Baumstruktur darzustellen. Beliebige Texte werden als Knoten (nodes) oder Blätter (leafs) in einer bisweilen weit verästelten Struktur geordnet sichtbar gemacht.
IDV-Lösung per ‚Documentation Tree‘
Ein sauber gepflegtes Documentation Tree hat den großen Vorteil, leicht die Vollständigkeit der Dokumentation zu gewährleisten. Alle Datenabnehmer und -zulieferer sind mit ihm sichtbar. Daraus erwächst ein sehr guter Überblick über die gesamte erfasste IDV-Landschaft.
Wenn Zusammenhänge in den IDV-Landschaften, zum Beispiel die Informationen über die ISIN, in verschiedenen Office-Dokumenten gesucht werden oder der Frage nachgegangen wird, wohin Daten fließen und woher sie kommen, hilft ein Documentation Tree weiter.“
Durch die Darstellung der Zusammenhänge kann leicht nachvollzogen werden, wie die Herstellung der Daten erfolgt und wo überall die Information (z. B. ISIN) verarbeitet wird. Besonders die Markierungsfunktion hebt gleichlautende Texte in der Baumstruktur farblich hervor. Auch wenn ein Text nicht ausgewählt wird und sich an anderen Stellen in der Baumstruktur befindet, wird dieser überall gefunden. Knoten oberhalb und Knoten bzw. Blätter unterhalb im Baum verglichen mit dem markierten Text werden ebenfalls in einer anderen Farbe kenntlich gemacht. Diese farblichen Markierungsfunktionen helfen, alle Zusammenhänge zwischen Verarbeitungsschritten zu analysieren, auch wenn die Verbindungen in separaten Ästen dargestellt werden. Damit erlangt ein Anwender eine Klarheit über die Zusammenhänge der Verarbeitungsschritte.
Eine große Hilfe ist ein fortlaufend aktuell gehaltener Documentation Tree bei der Änderung von Datenbanken und Programmen. Leicht wird erkannt, welche nachfolgenden Systeme Abnehmer der Daten sind. Abhängigkeiten werden damit richtig wiedergegeben. Bei Änderungen muss nicht befürchtet werden, dass Daten fehlen oder falsch geliefert werden. Schnell kann ermittelt werden, welche Verarbeitungsschritte existieren. So wird klar, welche Dateien angepasst werden müssen bzw. umgekehrt, welche nicht betroffen sind.
Ein aktueller Documentation Tree hilft bei der Suche in Programmen, selbst wenn sich jemand in einer IDV-Landschaft zurechtfinden möchte, die er selbst nicht errichtet hat. Bei der Einarbeitung neuer Mitarbeiter, die neben den Programmen auch die Abläufe kennenlernen müssen, hilft ein Documentation Tree ebenfalls weiter. Der Documentation Tree bietet somit bei personellen Engpässen große Vorteile.
Documentation Tree: Erklärung und Beispiel aus dem Benutzerhandbuch auf Github8
Technisch gesehen kann ein Documentation Tree als IDV-Anwendung durch das IUP-Lua-Framework als Skript realisiert werden (Siehe https://sourceforge.net/projects/iup/files/ und als Grundlage die Beispieldatei „tree3.lua“ im Unterordner „Docs and Sources“ in der Zip-Datei der examples) Als ODV-Anwendung kann ein Documentation Tree mit einem Java-Programm hergestellt werden (Siehe www.github.com/BeckmannundPartnerCONSULT/DocumentationTree). Für beide Varianten wird eine Textdatei manuell oder automatisch hergestellt, indem im Format einer Lua-Tabelle (Siehe www.lua.org/pil/2.5.html oder http://lua.lickert.net/tables/index.html) in geschweifte Klammern und durch Kommata getrennt die jeweiligen Knoten durch die Elemente branchname=“Knotenname“ und die jeweiligen Blätter durch die einfachen Textangaben in Anführungsstrichen „Blattbezeichnung“ eingegeben werden.
Der Vorteil, einen Documentation Tree manuell zu gestalten, besteht darin, die Inhalte frei eingeben zu können. Damit können beliebige Zusammenhänge zwischen Verarbeitungsschritten, zum Beispiel in Excel-Dateien und anderen Programmen, dargestellt werden, auch wenn Daten aus diesen Programmen nicht extrahiert werden können. Der Nachteil der manuell erstellten Documentation Trees ist die langsame Verarbeitung.“
Der Nachteil, einen Documentation Tree automatisch zu erstellen, ist, dass die Dokumentation nicht immer vollständig sein kann: Erklärende Zusatztexte und nicht automatisch erfasste Programme können nicht oder nur schwer in diesen standardisierten Dokumentationen eingebaut werden. Der Vorteil eines automatisch erstellten Documentation Trees liegt in der schnellen Verarbeitung. Eine solche Automatisierung ist bei MS-Access-Datenbanken möglich. Durch die schnelle Verarbeitung ist es einfach, die Dokumentation aktuell zu halten.
Mit den manuellen und den automatischen Documentation Trees zusammen lassen sich also die Anforderungen der Vollständigkeit, Richtigkeit, Ordnung, Wahrheit und Klarheit für die IDV-Anwendungen realisieren. Durch beständige Pflege erfüllt die IDV die Anforderung der fortlaufenden Aufzeichnung.aj
Sie finden diesen Artikel im Internet auf der Website:
https://itfm.link/84667


Schreiben Sie einen Kommentar