

Incident-Management: Ausfälle sind unvermeidlich. Schlechte Vorbereitung nicht!

Datadog
Ein effektiver Incident-Management-Workflow hängt von zugänglichen, integrierten Tools sowie von klaren, direkten Kommunikationskanälen ab. Und selbst nachdem die Angelegenheit gelöst wurde, ist die Dokumentation und Analyse des Postmortems entscheidend.
von Stefan Marx, Datadog
Hakt eine Finanzsoftware oder ist das Online-Banking nicht erreichbar, ist das für Angestellte und Kunden ärgerlich und kostet die Bank im Zweifel jede Minute bares Geld. Ausfälle sind in der modernen Welt der Hochgeschwindigkeits-Anwendungsentwicklung unvermeidlich. Die richtige Vorbereitung kostet Zeit und Ressourcen, will man eine ineffektive und unorganisierte Reaktion vermeiden, die im Zweifel alles nur noch viel schlimmer macht.„Aus Fehlern lernen“, das gilt auch in der IT. Jedes Incident ist auch eine Chance, es in Zukunft besser zu machen. Und so helfen Best Practices und etablierte Incident-Workflows, jeden Vorfall so schnell wie möglich zu beheben, die MTTR, die Mean Time to Resolution, zu drücken und dann wieder daraus zu lernen. Ein effizienter End-to-End-Incident-Management-Prozess kann so die Resilience der gesamten Infrastruktur stärken.
Einfach wäre langweilig
Die richtigen Daten und Tools sind entscheidend für die Reaktion auf Incidents – von Metriken über Logs bis hin zu Anwendungs-Traces, sowie Chat-, Messaging- und Video-Tools für die Kommunikation.
Der Incident-Management-Prozess sollte die einzelnen Maßnahmen und Möglichkeiten sowie die in Verbindung zum Vorfall stehenden Daten strukturieren. Er bringt aber nichts, wenn nicht auch für klare Zuständigkeiten bei Alarmierung, in der Zusammenarbeit und der Dokumentation der Vorfälle gesorgt ist.”
Dass die Bewältigung dieser Aufgabe dem Alltag in einem Hühnerhaufen gleich kommt, wenn sie erst bei Problemen in Angriff genommen wird, ist verständlich. Der Prozess muss also dann festgelegt und etabliert werden, wenn die Systeme reibungslos laufen und für entsprechende Planungen und Absprachen die notwendige Zeit und Ruhe vorhanden ist.
Denn selbst wenn alles läuft, sorgen komplexe Prozesse und notwendiges Expertenwissen dafür, dass die Workflow-Definition kein Strandspaziergang ist. Wer ist für das Reaktionsmanagement verantwortlich? Welche weiteren Rollen und Verantwortlichkeiten im Team müssen vergeben werden? Welche Informationen werden wann, wo benötigt? Wo kommen die Daten her und wie mache ich sie universell zugänglich? Wie wird der Vorfall für zukünftige Learnings dokumentiert? Wie wird kommuniziert? Das alles will im Voraus geplant und dokumentiert werden – aber wenn es einfach wäre, wäre es ja langweilig!
Datadog
Ding Dong
Startpunkt ist in der Regel ein ausgelöster Alarm. Klar. Es ist entsprechend wichtig festzulegen, welche Daten oder Anomalien überhaupt für ein Alarmsignal in Frage kommen. Welche Daten über die gesamte Anwendungsökonomie hinweg deuten darauf hin, dass hier gerade etwas gewaltig schiefläuft? Neben automatischen Alerts muss es natürlich auch manuelle Auslöser geben, etwa wenn ein synthetischer Browser-Test vermuten lässt, dass auf Grund eines JavaScript-Fehlers ein Schlüsselelement von der Online-Banking-Seite verschwunden sein könnte, aber noch nicht klar ist, ob es ein singuläres oder generelles Problem ist. Natürlich können die Machine-Learning-Algorithmen auch selber einen Alarm basierend auf erkannten Trends auslösen, aber manche Unregelmäßigkeiten bedürfen eben der Überprüfung des Ops-Teams.
 Stefan Marx ist Director Product Management für die EMEA-Region beim Cloud-Monitoring-Anbieter Datadog. Marx ist seit über 20 Jahren in der IT-Entwicklung und -Beratung tätig. In den vergangenen Jahren arbeitete er mit verschiedenen Architekturen und Techniken wie Java Enterprise Systemen und spezialisierten Webanwendungen. Seine Tätigkeitsschwerpunkte liegen in der Planung, dem Aufbau und dem Betrieb der Anwendungen mit Blick auf die Anforderungen und Problemstellungen hinter den konkreten IT-Projekten.
Stefan Marx ist Director Product Management für die EMEA-Region beim Cloud-Monitoring-Anbieter Datadog. Marx ist seit über 20 Jahren in der IT-Entwicklung und -Beratung tätig. In den vergangenen Jahren arbeitete er mit verschiedenen Architekturen und Techniken wie Java Enterprise Systemen und spezialisierten Webanwendungen. Seine Tätigkeitsschwerpunkte liegen in der Planung, dem Aufbau und dem Betrieb der Anwendungen mit Blick auf die Anforderungen und Problemstellungen hinter den konkreten IT-Projekten.Und im nächsten Schritt:
Wer wird alarmiert und wann? Eine effektive Reaktion ist nur dann möglich, wenn direkt die richtigen Personen mit den richtigen Daten an der Hand alarmiert werden.”
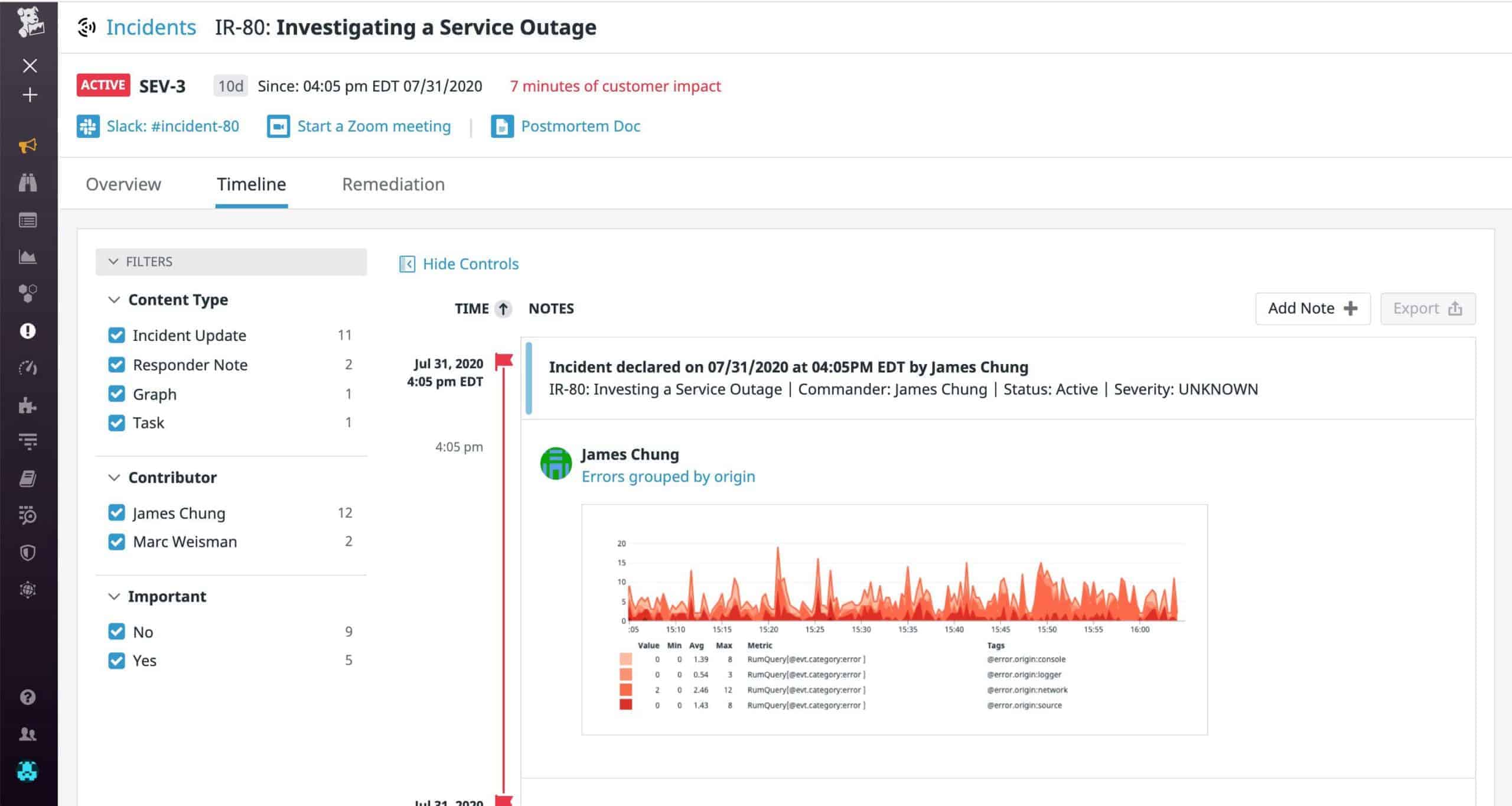
Ein gemeinsamer Informationspool inklusive Ablage und Kommunikationsstream bildet die Grundlage zur gemeinsamen Problemlösung. Dafür müssen der Alarm ebenso wie die dazugehörigen Grafiken und Diagramme sowie die Kommunikationswege in kollaborativen – und das heißt heute nun mal plattformübergreifenden Tools zugänglich gemacht werden.
Lösung durch Datenvorsprung
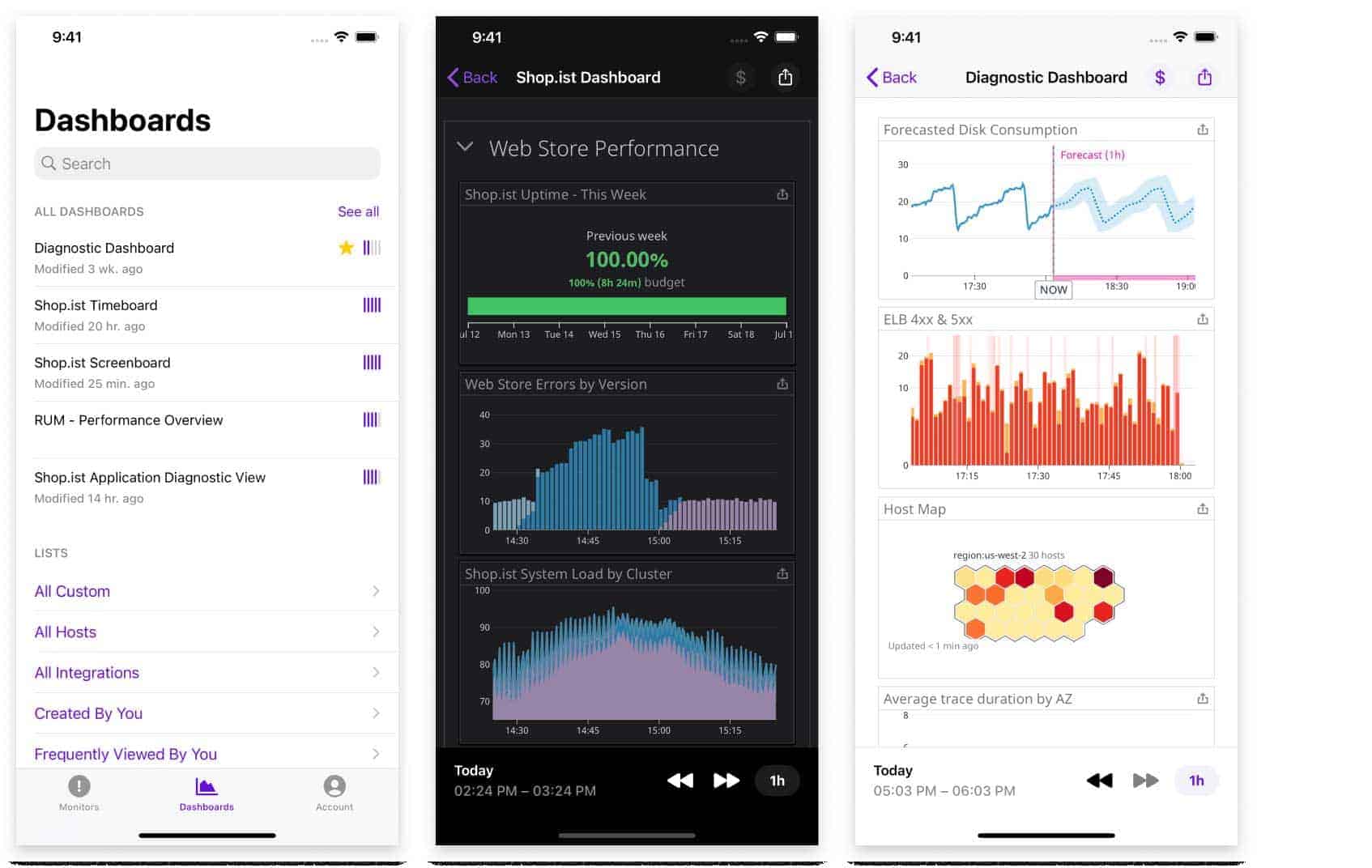
Die richtigen Personen sind alarmiert, der erste Schritt ist gemacht. Neben Zugriff auf die erste Fehlermeldung (wann genau ist wo was zum ersten Mal passiert) braucht das Team unbedingten Zugriff auf alle relevanten Daten. Silodenken und Kleinfürstentum innerhalb der IT-Teams sind mit das Unnötigste, wenn ein Problem schnell gelöst werden soll. Damit es hier nicht knirscht, müssen im Vorfeld Schnittstellen, idealerweise eine zentrale Incident UI, etabliert werden, damit neben Daten zum aktuellen Vorfall auch die früherer, sowie die Baseline im ungestörten Regelbetrieb abgerufen werden kann.
Die Teams benötigen für eine effektive Root-Cause-Untersuchung außerdem Zugriff auf Logs, Traces, Netzwerk-Traffic oder Infrastruktur-Metadaten und die Möglichkeit, diese entsprechend zu sortieren, sowie eine chronologische Liste der zum Problem und seiner Lösung beitragenden Aktualisierungen. Teammitglieder können Links oder Text in der Zeitachse hinterlegen, um Kommentare, Kontext und andere hilfreiche Informationen für alle bereitzustellen, etwa Dashboards mit relevanten Metriken.
Datadog
Wichtig sind hier, neben Daten zu Infrastruktur und Performance, auch Verknüpfungen mit Geschäftsdaten und Informationen zur Anwendungsarchitektur. Betrifft der Incident nur bestimmte Kundengruppen, Lokationen oder Releases? Wie ist der Impact zu bewerten in Bezug auf die Anzahl betroffener Benutzer, Gesamtmenge der betroffenen Transaktionen oder Transaktionsvolumen?
Aufstehen, Krone richten, besser werden
Wie welches Incident bewältigt werden kann, lässt sich natürlich vorher nicht planen. Dann bräuchte es keinen Workflow, sondern nur ein Erste-Hilfe-Kit. Ist das Problem behoben, fällt die Anspannung ab. Die Arbeit ist jedoch noch nicht vorbei. Nun gilt es dafür zu sorgen, dass das gleiche Problem nicht wieder auftritt oder wenn doch die MTTR zu verkürzen, indem es schneller identifiziert und behoben werden kann.
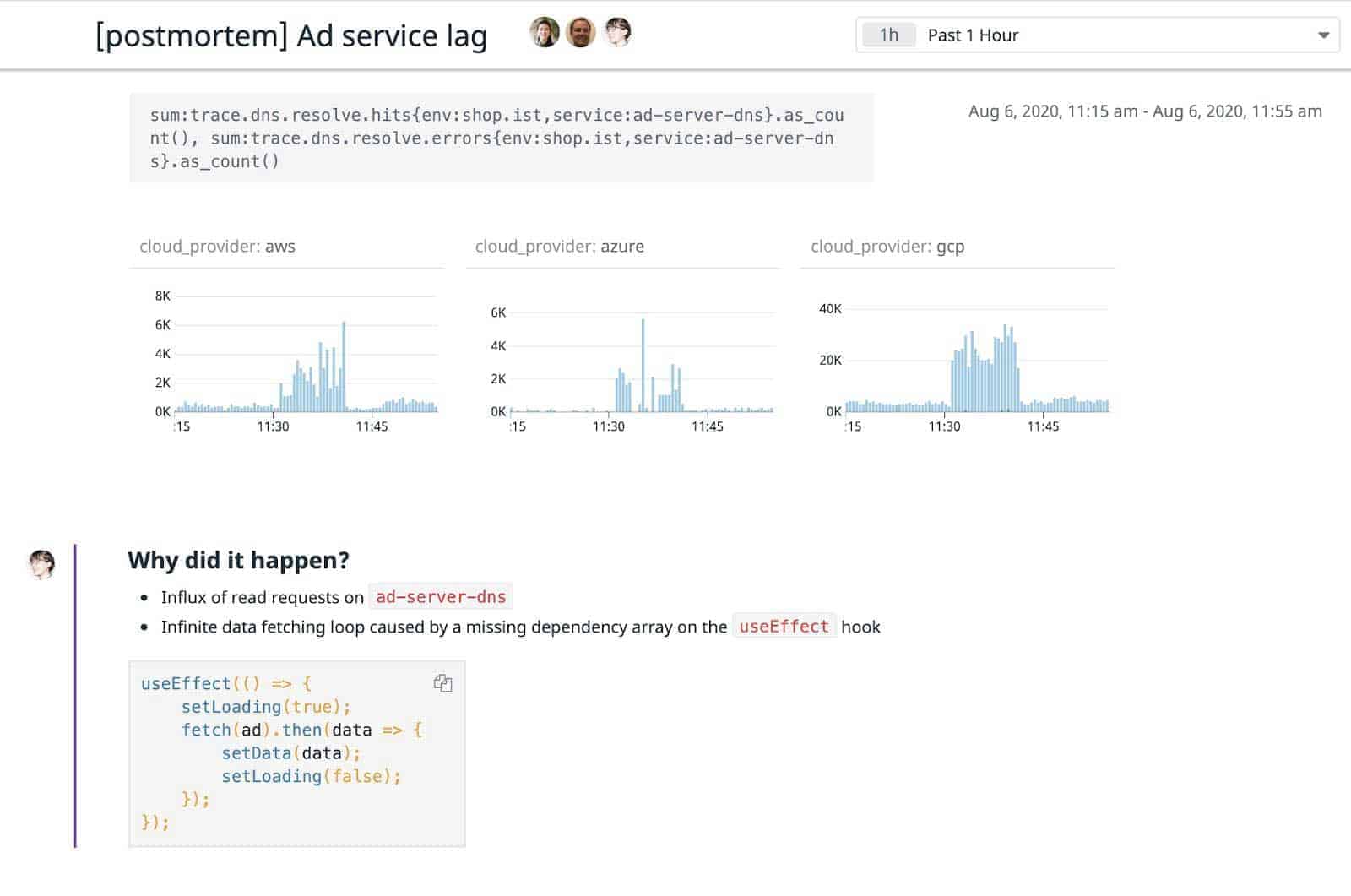
Dokumentation und sogenannte Postmortems, in denen gesammelte Daten dokumentiert und gespeichert werden, sind entscheidend für das Incident Management. Korreliert ein neuer Vorfall mit einem vergangenen, können Probleme oder Teile davon schneller erkannt werden.
Datadog
Eine Liste mit Folgeaufgaben zur Behebung akuter Probleme, fixe Pläne zur Aktualisierung von Warnmeldungen und ein detailliertes, für das gesamte Team zugängliches Postmortem-Dokument sind essentiell, damit alle Beteiligten das überstandene Problem und seine Auswirkung verstehen und zukünftig ähnliche Probleme schneller identifizieren können. Auch diese Dokumentation sollte zentral zugänglich sein und die Datenpunkte in zukünftige Incident-Untersuchungen einfließen.
Postmortem-Dokumente helfen außerdem dabei, die Ursachen im Rahmen eines Software-Release nachhaltig zu beseitigen und diese Änderung anschließend auf Wirksamkeit zu überprüfen.
Aufwand, der sich lohnt
Ein Incident Management-Workflow ist sicher nicht mal eben festgezurrt. Er braucht Sinn, Verstand, Schnittstellen und Liebe zum Detail.”
Ein Incident Management-Workflow ist sicher nicht mal eben festgezurrt. Er braucht Sinn, Verstand, Schnittstellen und Liebe zum Detail.”
Mit alledem kann auf Vorfälle jedoch effektiver und effizienter reagiert werden, ohne planlos Feuerwehrmann oder -frau spielen zu müssen. Und am Ende schafft er – einmal etabliert – Luft für Innovationen, weil die Systemstabilität in Gänze profitiert und so Freiräume entstehen.Stefan Marx, Datadog
Sie finden diesen Artikel im Internet auf der Website:
https://itfm.link/119444


Schreiben Sie einen Kommentar