
Datenschleuder REST: Warum klassische APIs Versicherungsdaten systematisch korrumpieren

Vinlivt
von Dariusz Borowski, Vinlivt
Das Problem:
Wenn drei Systeme denselben Kunden kennen
In der digitalen Versicherungslandschaft sieht die IT-Realität vieler Maklerorganisationen so aus: Ein Kunde existiert gleichzeitig als Datensatz im CRM des Maklers, als Vertragsnehmer im Maklerverwaltungsprogramm (MVP) und als Lead im Vergleichsrechner des Pools. Drei Systeme, drei Datenmodelle, drei Schreibpfade, aber kein koordinierter Schreibzugriff.
Das strukturelle Problem ist nicht mangelnde Sorgfalt der Entwickler. Es ist das Fehlen eines gemeinsamen Fundaments: einer eindeutigen Quelle der Wahrheit für jede fachliche Entität, mit klar definierten Regeln, wer für welches Datenfeld verantwortlich ist.“
Was stattdessen passiert, ist bekannt: Der Makler legt einen Kunden im CRM an. Der Pool übermittelt denselben Kunden über eine Batch-Datei aus dem MVP. Parallel onboardet der Kunde sich selbst über ein Webportal. Drei parallele Schreibvorgänge, keine Abstimmung, keine Dublettenerkennung vor dem Speichern, und der Fehlerdatensatz-Pool wächst täglich.
Warum klassische APIs dieses Problem nicht lösen
Das Pull-Problem
Das Polling-Modell, bei dem ein System periodisch ein anderes abfragt, um Änderungen zu erkennen, ist in modernen Architekturen ein grundlegendes Anti-Pattern. Zwischen zwei Abfragezyklen (typisch: 5 bis 60 Minuten) entstehen Lücken. Mehrere Änderungen am selben Datensatz innerhalb eines solchen Fensters verschmelzen zu einem einzigen Ergebnis, die Zwischenzustände gehen verloren.
In regulierten Umgebungen ist das mehr als ein technisches Problem. DORA Artikel 9 fordert eine lückenlose Dokumentation von IT-Risiken. Ein System, das Zwischenzustände nicht nachvollziehbar protokolliert, kann diese Anforderung grundsätzlich nicht erfüllen.
 Dariusz Borowski ist CTO und Mitgründer von Vinlivt (Website), einer digitalen Plattform für Versicherungsmakler und Finanzvermittler mit Sitz in München. Er verantwortet die technische Architektur der Plattform mit Fokus auf verteilte Systeme, ereignisgesteuerte Integration und regulierte Finanzumgebungen in der Cloud.
Dariusz Borowski ist CTO und Mitgründer von Vinlivt (Website), einer digitalen Plattform für Versicherungsmakler und Finanzvermittler mit Sitz in München. Er verantwortet die technische Architektur der Plattform mit Fokus auf verteilte Systeme, ereignisgesteuerte Integration und regulierte Finanzumgebungen in der Cloud.
Eine API-Anfrage ohne eindeutigen Wiederholungsschutz ist gefährlich, sobald Netzwerkfehler oder Timeouts auftreten. Wird dieselbe Anfrage mehrfach gesendet, weil ein Timeout fälschlicherweise als Fehler interpretiert wurde, entstehen mehrfache Datensätze im Zielsystem. Das ist kein Sonderfall, sondern Alltag in jedem produktiven System mit automatischen Wiederholungsmechanismen.
In einem System, das täglich hunderte Vertragsabschlüsse verarbeitet, ist das kein theoretisches Risiko, sondern eine verlässliche Quelle für wachsende Dublettenbestände.
Das Versionierungsproblem
REST-APIs liefern den aktuellen Zustand eines Datensatzes, aber nicht seine Geschichte. Wer hat wann was geändert? Welcher Stand war der letzte konsistente? Diese Fragen lassen sich ohne explizite Versionierung auf Datenbankebene nicht beantworten.
Wenn CRM und MVP denselben Kunden innerhalb von Sekunden parallel ändern, ohne dass eines der Systeme vom Schreibvorgang des anderen weiß, gehen Informationen verloren, ohne dass irgendjemand eine Fehlermeldung sieht. Die Daten sind einfach falsch, still und leise.
Kernthese
→ REST ist ein Übertragungsprotokoll, kein Konsistenzprotokoll.
→ Ohne Wiederholungsschutz, Versionierung und eine gemeinsame Wahrheitsquelle ist REST in parallelen Schreibszenarien strukturell ungeeignet.
→ Das ist kein Anbieter-Problem, es ist ein Architekturproblem.
Der Architekturansatz: ereignisgesteuert, konsistent, nachvollziehbar
Ereignisgesteuerte Architektur als Fundament
Der Wechsel von Polling zu Push ist keine Kür, sondern Pflicht, wenn Datenkonsistenz in regulierten Umgebungen gefordert ist. In einer ereignisgesteuerten Architektur (Event-driven Architecture) ist jede Zustandsänderung ein explizit gespeichertes Ereignis mit eindeutiger Kennung, Zeitstempel und Herkunftsangabe.
Der Ereignisspeicher ist die primäre Informationsquelle, nicht die Datenbank des jeweiligen Zielsystems.“
Nachrichtenbroker wie Apache Kafka oder RabbitMQ bilden das technische Rückgrat. Entscheidend ist dabei nicht die Produktwahl, sondern die Garantien: Jedes Ereignis wird mindestens einmal zugestellt, das Schema ist versioniert und maschinenlesbar vertraglich definiert, und jeder Konsument kann seinen Verarbeitungsstand nachvollziehbar dokumentieren.
Wiederholungsschutz als Systemversprechen
Idempotenz bedeutet: dieselbe Operation, beliebig oft ausgeführt, erzeugt immer dasselbe Ergebnis. Das ist die Grundvoraussetzung für Systeme, die bei Fehlern automatisch wiederholen.
Jeder schreibende Vorgang erhält eine eindeutige Vorgangs-ID.“
Vor dem Speichern wird geprüft, ob diese ID bereits verarbeitet wurde. Ist das der Fall, wird der Vorgang stillschweigend ignoriert. Das System wird damit fehlertolerant, ohne Duplikate zu erzeugen.
Versionierung als Sicherheitsnetz
Jeder fachliche Datensatz braucht drei Pflichtfelder, die kein Standard-Framework automatisch mitliefert: eine systemweit eindeutige unveränderliche Kennung, einen Versionsstempel für konfliktsichere parallele Änderungen, und eine Schemaversion für den kontrollierten Austausch zwischen Diensten. Ohne diese Felder ist jede Integration ein geduldetes Risiko.
Schemaänderungen folgen dabei einem klaren Vertrag: Neue optionale Felder ergänzen bestehende Versionen.“
Grundlegende Änderungen erfordern eine neue Version mit dokumentiertem Migrationspfad. Systeme, die diesen Vertrag nicht kennen, können nicht kontrolliert weiterentwickelt werden.
Architekturdiagramm: Problem vs. Lösung
Das folgende Diagramm zeigt links das typische Datenchaos-Muster, bei dem CRM, MVP, Vergleichsrechner und Legacy-Backend unkontrolliert gegenseitig schreiben, sowie rechts den strukturierten Lösungsansatz mit einem zentralen Ereignis-Layer, einer Identitätsauflösung und einem Golden Record als einziger Wahrheitsquelle.
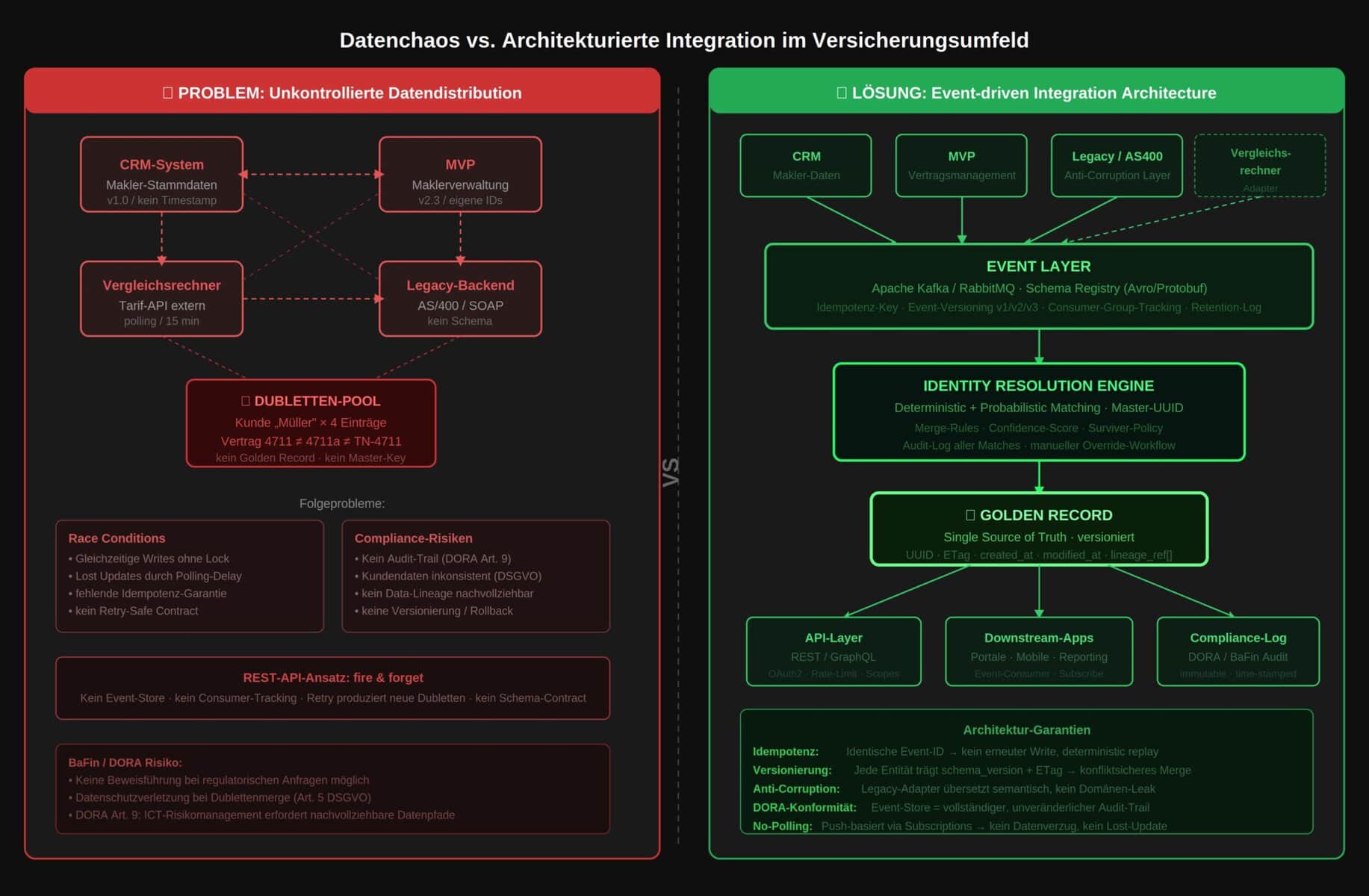
Vinlivt
Dubletten als systemisches Versagen, nicht als Datenpflegeproblem
Dubletten werden in der Praxis als Datenpflegeproblem behandelt: Bereinigungsskripte, nächtliche Abgleiche, manuelle Prüfungen. Das ist die falsche Ebene. Dubletten sind ein Symptom fehlender Schreibkoordination auf Architekturebene, und sie lassen sich dort auch nur dauerhaft beheben.
Das Golden-Record-Prinzip setzt genau hier an: Es definiert einen kanonischen Masterdatensatz für jede fachliche Einheit, dem alle anderen Datensätze aus allen Quellsystemen eindeutig zugeordnet werden.“
Das Prinzip funktioniert auf zwei Ebenen: technisch über regelbasierte und ähnlichkeitsbasierte Erkennungsalgorithmen (Adressnormalisierung, Namensähnlichkeit, Schlüsselübereinstimmung) sowie fachlich über klare Zuständigkeitsregeln, welches System für welches Datenfeld die Hoheit besitzt.
Entscheidend ist: Der Golden Record entsteht nicht durch nachträglichen Merge, sondern durch eine Erkennungskomponente, die vor jedem Schreibvorgang prüft, ob der Datensatz bereits existiert.
Die Dublettenerkennung ist Teil des Schreibpfads, kein nachgelagerter Aufräumprozess.“
Konfidenz und manueller Eingriff: Kein Algorithmus ist fehlerfrei. Daher gehört ein klar definierter Prozess für manuelle Entscheidungen bei unklaren Treffern genauso zur Architektur wie der Algorithmus selbst. Jede manuelle Entscheidung wird mit Benutzerkennung und Zeitstempel protokolliert, eine Anforderung, die in regulierten Umgebungen nicht verhandelbar ist.
Aufbau und Bestandteile des Golden Record
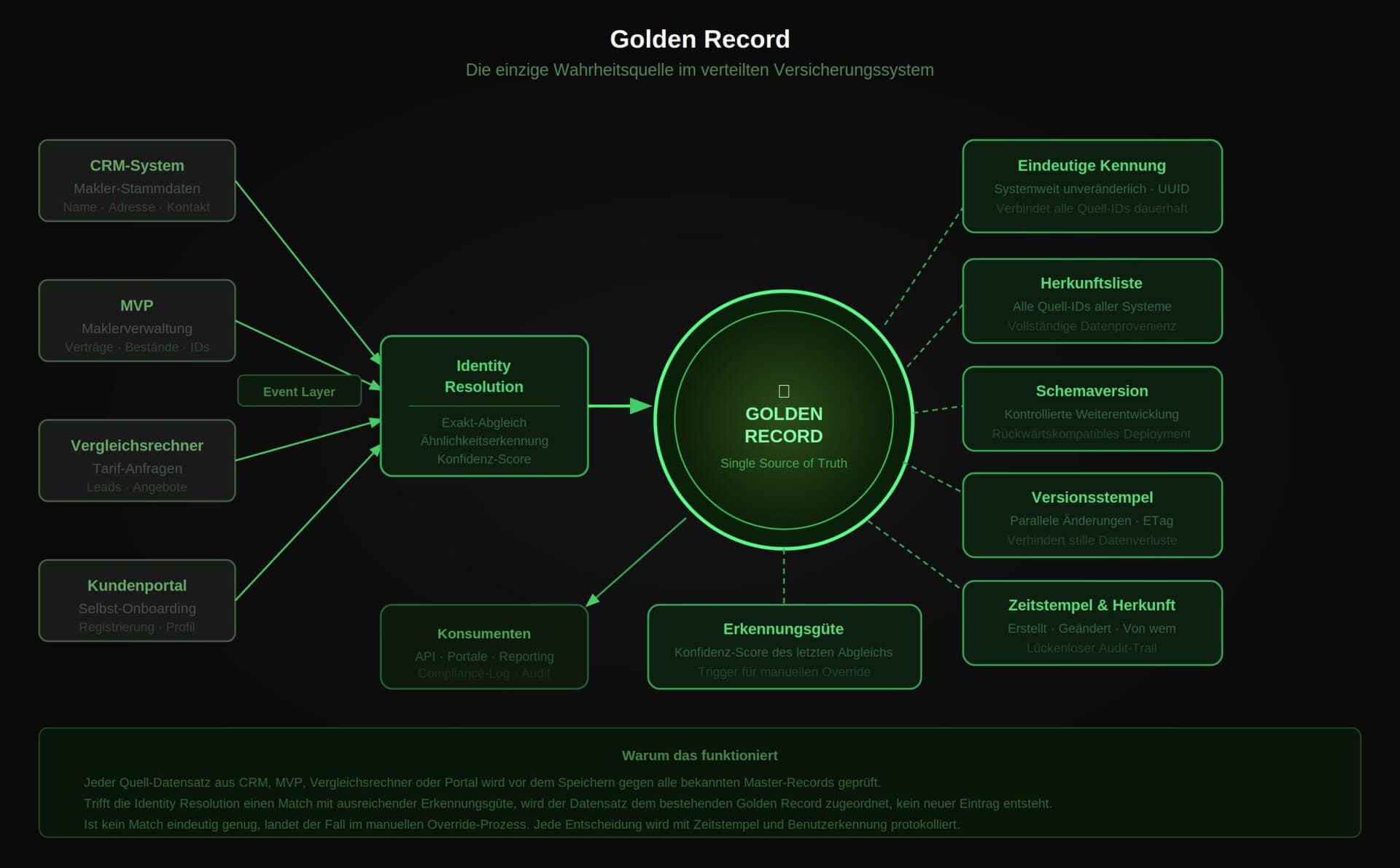
Vinlivt
Fazit: Die Technologieschuld ist architektonisch
REST-APIs sind nicht das Problem. Das Problem ist die Annahme, dass eine API alleine Datenkonsistenz in verteilten Systemen sicherstellen kann. Das kann sie nicht. In Systemen, in denen mehrere Quellen gleichzeitig schreiben, braucht es explizite Koordination auf Architekturebene, keine bessere Middleware.
Die Dubletten, Inkonsistenzen und Compliance-Risiken, die heute Entwicklungsteams beschäftigen, sind die Rechnung für Architekturentscheidungen, die vor Jahren nicht bewusst getroffen wurden.“
Die gute Nachricht: Diese Schuld ist tilgbar. Nicht mit einer vollständigen Neuimplementierung, sondern schrittweise, durch das gezielte Einziehen von Ereignisverarbeitung, Identitätsauflösung und klaren Dateneigentümerschaftsregeln als neue Architekturprimitive. Die Technologien sind verfügbar. Was fehlt, ist der organisatorische Konsens, dass Datenkonsistenz kein Feature ist, das man später nachrüstet. Dariusz Borowski, Vinlivt
Sie finden diesen Artikel im Internet auf der Website:
https://itfm.link/245575


Schreiben Sie einen Kommentar