
Deep-Learning-Technologie in der Praxis: Effizienzsteigerung durch KI

Barmenia Versicherungen
Dunkelverarbeitung: Rechnungen im Posteingang enthalten neben Beträgen und Gebührenziffern auch Texte, beispielsweise Leistungsbeschreibungen in Arztrechnungen, die bei der Rechnungsprüfung zu berücksichtigen sind. Deep-Learning und andere Technologien aus der künstlichen Intelligenz erweisen sich als geeignete Werkzeuge, manuelle Prozesse in der Leistungssachbearbeitung zu unterstützen oder vollständig zu automatisieren. Ein interessanter Anwendungsfall ist das maschinelle Verarbeiten von Informationen, die in Form von Texten vorliegen.
von Gerhard Hausmann, Entwickler von Expertensystemen der Barmenia Versicherungen
Texte werden von Informatikern als „unstrukturierte“ Daten bezeichnet, sie stellen eine große Hürde bei der Automation dar. Liegen erst einmal strukturierte Daten wie Gebührenziffern, Diagnosecodes, Behandlungsdaten, Steigerungsfaktoren oder Beträge vor, kann mit bewährten Techniken der künstlichen Intelligenz effizient automatisiert werden. Geeignet sind regelbasierte Systeme, ihre modernen Varianten werden als Business Rules Management Systeme bezeichnet und ermöglichen das Abbilden und Verarbeiten von Bedingungen der Versicherungstarife oder von Regelungen der Gebührenordnungen in Form von „Wenn … dann …“-Regeln oder Entscheidungstabellen. Selbst umfangreiche, komplexe Entscheidungen treffen sie in Bruchteilen von Sekunden; Begründungen liefern sie gleich mit.
Regelbasierte Systeme haben aber zwei Schwächen: Sie lernen nicht von selbst, und Lesen können sie auch nicht.“

Die IT-Systeme der Versicherer sind regelmäßig dem Vorwurf ausgesetzt, als „Flaschenhals der Digitalisierung“ nicht schnell genug notwendige Innovationen in die Umsetzung bringen zu können. Von Regulierung, Geschäftsführung und Fachabteilungen werden stetig neue Anforderungen und Ziele formuliert. Konkrete Lösungsansätze sind gefragt. Mehr zur Konferenz finden Sie hier.
Arzt- oder Zahnarztrechnungen enthalten neben Positionen, die nach Gebührenordnungen abgerechnet werden und mit Gebührenziffern versehen sind, auch Positionen mit frei formulierten Texten, dabei handelt es sich beispielsweise um sogenannte Analogberechnungen oder um Materialkosten. Zahnlabore sind anders als Ärzte nicht verpflichtet, nach einer Gebührentabelle abzurechnen und verwenden bei der Rechnungsstellung nicht immer Ziffern aus gängigen Tabellen. Die Texte spielen bei der Prüfung von Rechnungen also eine wichtige Rolle. Kann maschinell erkannt werden, worum es sich bei diesen Positionen handelt, so dass auch über ihre Erstattung maschinell entschieden werden kann?
Künstliche Intelligenz und Natural Language Processing
Das maschinelle Verarbeiten von Sprache und Texten, das sogenannte Natural Language Processing (NLP) ist ein Teilgebiet der künstlichen Intelligenz, in dem Deep-Learning eine zunehmende Rolle spielt. Zum Natural Language Processing gehören z.B. das Klassifizieren von Texten, Sentiment Analysis oder auch maschinelles Übersetzen.
Ein bekanntes Anwendungsgebiet für das Klassifizieren von Texten sind Spam-Filter in E-Mail-Servern, die erwünschte von unerwünschter elektronischer Post trennen. NLP-Klassifizierer eignen sich genauso für das Identifizieren von Texten, die zahnärztliche oder ärztliche Leistungen beschreiben. Klassifikationsaufgaben gibt es im Gesundheitswesen viele: Das Zuordnen von Gebührenziffern zu Leistungsbeschreibungen aus Rechnungen von Zahnlaboren ist eine Klassifikationsaufgabe. Die Gebührenziffer ist ein Symbol für eine Klasse, der die Rechnungsposition zugeordnet wird. Eine andere Klassifikationsaufgabe ist das Bewerten von Hinweisen, die Kunden den Leistungsanträgen bei Einreichung über eine Rechnungs-APP mitgeben.
Sollte wegen des schriftlich formulierten Hinweises „hell“ verarbeitet werden? Oft handelt es sich um einen Hinweis, der eine „dunkle“ Verarbeitung nicht verhindert? Möglicherweise hat der Kunde schlichtweg einen freundlichen Gruß übermittelt.
Klassifikation von Texten
Unter Deep-Learning werden Techniken verstanden, die es ermöglichen, neuronale Netze mit vielen Schichten bzw. „tiefen“ Architekturen und vielen Neuronen in den einzelnen Schichten effizient zu trainieren. 2015/16 haben KI-Forscher der Universität New York um Yann LeCun ein Verfahren erprobt, das es erlaubt, erfolgreiche Deep-Learning Verfahren aus der digitalen Bildverarbeitung auch für die Klassifikation von Texten zu nutzen.
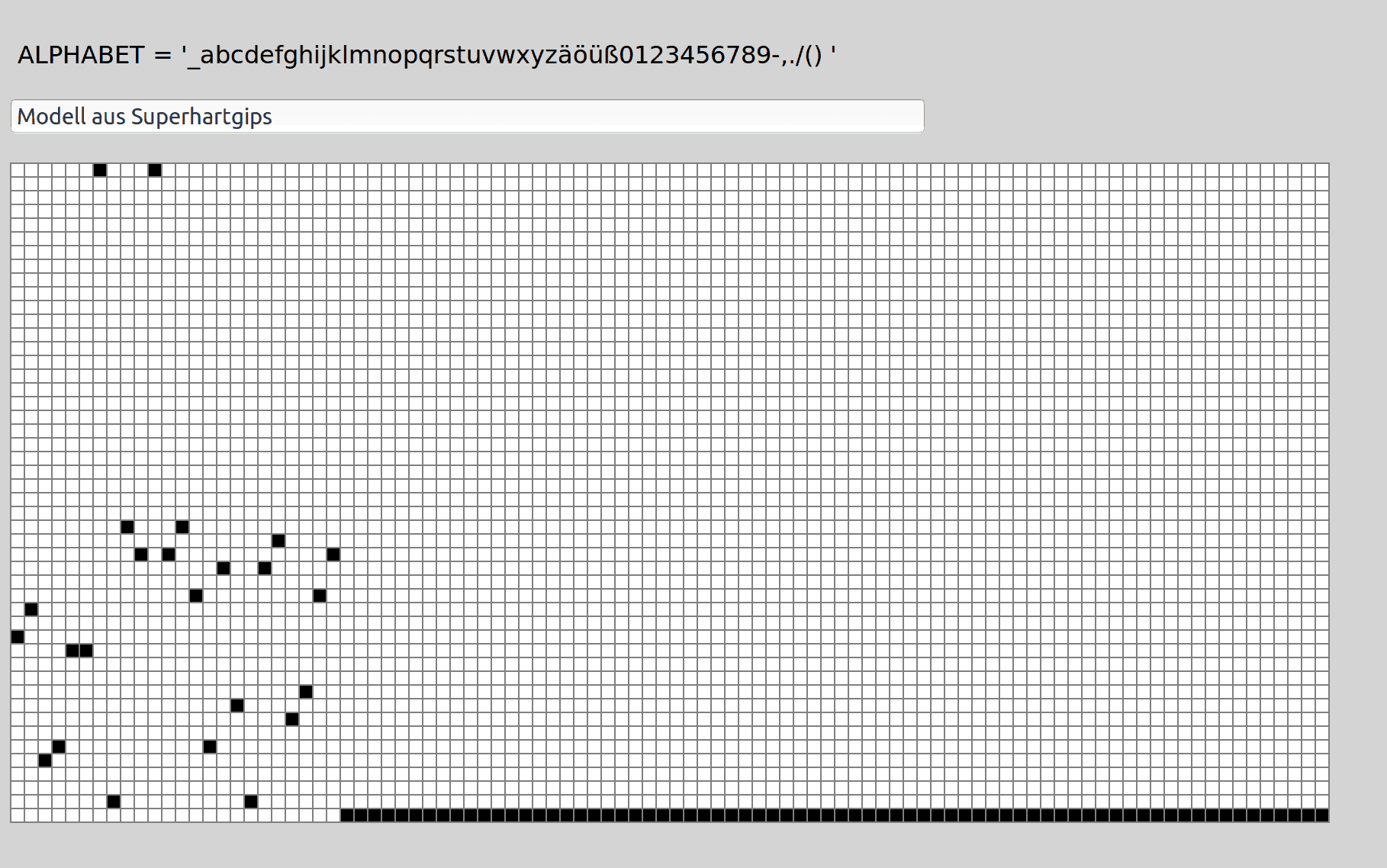
Barmenia Versicherungen
Die Idee ist bestechend einfach: Texte werden in Grafiken aus weißen und schwarzen Bildpunkten konvertiert. Für jedes Zeichen im Text wird ein schwarzer Punkt in einer überwiegend weißen Fläche erzeugt. Die Position in der ersten Dimension entspricht dabei der Position des Zeichens im Text, die Position in der zweiten Dimension der Grafik entspricht der Position des Zeichens in einem Zeichensatz. Diese Grafiken, die an Blindenschrift erinnern, können dann mit bewährten Verfahren für das Klassifizieren von Objekten auf Bildern weiter verarbeitet werden.
Yann LeCun-Verfahren ist der OCR überlegen
Die KI-Experten aus New York haben dies ausgiebig untersucht und Ergebnisse aus Testläufen mit Ergebnissen verglichen, die mit älteren Techniken des Natural Language Processing erzielt wurden. Sie haben unter anderem herausgefunden, dass dieses Verfahren besonders geeignet ist, wenn fehlerbehaftete Texte verarbeitet werden. In der privaten Krankenversicherung werden Rechnungen meist in Form von Briefen oder Fotos an die Versicherung übermittelt. Texte werden daraus mit optischer Texterkennung (OCR) gewonnen und weisen sogenannte OCR-Fehler auf.

Barmenia Versicherungen
Das Verfahren der New Yorker KI-Experten hat sich im praktischen Einsatz bei der Barmenia Krankenversicherung als leistungsfähig erwiesen. Die Barmenia setzt einen auf Deep-Learning basierenden Klassifizierer bei der Prüfung von Rechnungen von Zahnlaboren ein. Der Klassifizierer ist darauf trainiert, Leistungen von Zahnlaboren eine jeweils passende Ziffer aus Gebührentabellen zuzuordnen. Ist die Zuordnung der Ziffern erfolgt, kann beispielsweise durch einen einfachen Vergleich mit Richtwerten überprüft werden, ob die Höhe der berechneten Beträge im angemessen Rahmen ist. Ein Regelwerk, das ergänzend zum Einsatz kommt, bestimmt nach der Zuordnung der Ziffern automatisch Kostenanteile für Zahnbehandlung bzw. Zahnersatz, die von der Barmenia zu unterschiedlichen Prozentsätzen erstattet werden. Die Mitarbeiter werden auf diese Weise bei der Rechnungsprüfung und bei der Leistungserstattung unterstützt, Routine-Aufgaben konnten automatisiert werden.
 Gerhard Hausmann arbeitet nach dem Studium der Mathematik zunächst als Lehrer im Bereich der beruflichen Bildung. Ab 2000 entwickelte er Software für die Barmenia Versicherungen in Wuppertal, wo er heute als Architekt für wissensbasierte Systeme tätig ist. Sein Arbeitsschwerpunkt ist die Prozessautomation, insbesondere die Entwicklung von Expertensystemen für die Prüfung von Rechnungen und von Automaten für die Dunkelverarbeitung.
Gerhard Hausmann arbeitet nach dem Studium der Mathematik zunächst als Lehrer im Bereich der beruflichen Bildung. Ab 2000 entwickelte er Software für die Barmenia Versicherungen in Wuppertal, wo er heute als Architekt für wissensbasierte Systeme tätig ist. Sein Arbeitsschwerpunkt ist die Prozessautomation, insbesondere die Entwicklung von Expertensystemen für die Prüfung von Rechnungen und von Automaten für die Dunkelverarbeitung.Die Investitionen in Deep-Learning sind gering
Die Barmenia nutzt das freie und quelloffene Machine-Learning Framework Tensorflow, das von Google stammt. Die digitale Verarbeitung von Texten ist deutlich weniger rechenintensiv als die digitale Bildverarbeitung, die Anforderungen an die Hardware sind entsprechend geringer. Die Einarbeitungszeit ist aber nicht zu unterschätzen. Hinzu kommt, dass die Architektur der neuronalen Netze an die jeweilige Aufgabenstellung angepasst werden muss, um wirklich gute Ergebnisse zu erzielen. Auch nicht zu unterschätzen sind Aufwände für das Vorbereiten von Trainings- und Testdaten, die für überwachtes Lernen im ungünstigen Fall manuell mit Labeln für die erwarteten Ergebnisse versehen werden müssen. Aber es lohnt sich.
„Erstaunlich gut!“ lautet das Feedback aus der Gruppe der Pilotanwender bei der Barmenia, die in den ersten Wochen nach Produktionsstart besonders kritisch auf die Ergebnisse der maschinellen Zuordnungen von Gebührenziffern geachtet haben. Der Mensch wird nicht überflüssig, aber von Routineaufgaben entlastet. Weitere Klassifizierer für Texte, die spezielle Aufgaben in der Dunkelverarbeitung oder unterstützende Aufgaben bei der Prüfung von Rechnungen und Kostenvoranschlägen übernehmen werden, hat die Barmenia bereits im Test.Gerhard Hausmann
Sie finden diesen Artikel im Internet auf der Website:
https://itfm.link/77680


Schreiben Sie einen Kommentar