Wie maschinelles Lernen die BaFin-Compliance unterstützt – in der IT-Praxis

ForgeRock
Die sichere Ausgestaltung der IT-Systeme für Banken und Versicherungen wird seitens der BaFin detailliert in der BAIT bzw. VAIT beschrieben. Der Kriterienkatalog ist umfangreich und umfasst Bereiche von der IT-Strategie und Governance über das Risiko- und Sicherheitsmanagement bis hin zum Berechtigungsmanagement. Die bislang erfolgten Kontrollen dazu waren laut Aussage der BaFin wenig zufriedenstellend. Problematisch findet die BaFin es vor allem, dass man „keine internen Prozesse vorfand, die ausreichten, um Informationsrisiken zu erkennen und zu bewerten“ (ebda.).
von Dr. Steffo Weber, Director Customer Engineering ForgeRock
Nun setzt eine sinnvolle Risikobewertung – insbesondere bei quantitativ schwierig zu bewertenden Dingen wie „Information“ – eine Datenklassifizierung oder ähnliches voraus, um z. B. die Schadenshöhe zu bemessen. Basierend hierauf werden Zugriffsregeln, Berechtigungen etc. entworfen. Das ist ein langwieriger Prozess und es stellt sich die Frage, ob es nicht zusätzliche Möglichkeiten gibt, ein vorhandenes Berechtigungssystem aus Risikominimierungssicht zu bewerten.
Risikominimierung im Berechtigungsmanagement
Nehmen wir an, ein Unternehmen hat ein bestehendes Berechtigungssystem (Zuordnung von Berechtigungen zu Personen oder auch umgekehrt). Dann stellen sich im täglichen Betrieb u. a. folgende drei Fragen:
1. Role Mining: Welche Berechtigungen können in einer Rolle zusammengefasst werden?2. Risikoerkennung: Warum hat Fred die Rolle/Berechtigung X?
3. Decision Support: Sollte Freds Antrag auf Rolle/Berechtigung X genehmigt werden?
Klassisches Role Mining vs. Role Mining auf Basis assoziativer Regeln
Über ForgeRock & ARLForgeRock (Webseite) stelle mit seiner auf Association Rule Learning (ARL) basierenden Lösung Autonomous Identity (AutoID) das bisherige klassische Konzept von Role Based Access Control (RBAC) auf den Kopf und biete vollständige Transparenz über sämtliche Datenzugriffe im gesamten Unternehmen.
AutoID betrachtet bestehende Rollen- oder Berechtigungszuweisungen aus einem anderen Blickwinkel. Hierbei werden Begründungen für bestehende Berechtigungen ermittelt: Fred hat Zugriff auf Datensatz Y, weil Fred als Entwickler in X arbeitet und an Lisa berichtet. Der Grund leitet sich ausschließlich aus Attributen des HR-Systems ab. Innerhalb der AutoID werden jeder Begründung numerische Werte wie „Confidence“ zugewiesen, um verschiedene Begründungen quantitativ miteinander vergleichen zu können. Diesen assoziativen Regeln der Form HR-Attr1 & HR-Attr2 & (…) HR-Attrn – Entitlement helfen dabei, ein Rollenmodell zu finden bzw. ein bestehendes zu verifizieren oder zu falsifizieren. Darüber hinaus hilft die Entdeckung von Ausreißern, das Gesamtrisiko zu verringern.
AutoID betrachtet bestehende Rollen- oder Berechtigungszuweisungen aus einem anderen Blickwinkel. Hierbei werden Begründungen für bestehende Berechtigungen ermittelt: Fred hat Zugriff auf Datensatz Y, weil Fred als Entwickler in X arbeitet und an Lisa berichtet. Der Grund leitet sich ausschließlich aus Attributen des HR-Systems ab. Innerhalb der AutoID werden jeder Begründung numerische Werte wie „Confidence“ zugewiesen, um verschiedene Begründungen quantitativ miteinander vergleichen zu können. Diesen assoziativen Regeln der Form HR-Attr1 & HR-Attr2 & (…) HR-Attrn – Entitlement helfen dabei, ein Rollenmodell zu finden bzw. ein bestehendes zu verifizieren oder zu falsifizieren. Darüber hinaus hilft die Entdeckung von Ausreißern, das Gesamtrisiko zu verringern.
Viele Unternehmen setzen bereits Rollen ein, um – je nach erlaubter regulatorischer Unschärfe – Zugriffsregeln leichter managen zu können. Aus organisatorischer Sicht haben Rollen nur dann einen Vorteil gegenüber Einzelberechtigungen, wenn sie in einem gewissen Verhältnis zur Anzahl der Nutzer/Mitarbeitenden stehen. So strebten in der Vergangenheit Unternehmen aus dem Versicherungsumfeld im Schnitt ein 1:10 Verhältnis an. D. h. auf 100 Mitarbeitende kommen zehn Rollen (unternehmensweit). Werden es deutlich mehr Rollen, ist die Gruppierung der Nutzer in Rollen aus organisatorischer Sicht deutlich weniger effektiv. Ein solches Rollenverständnis widerspricht damit inhärent dem Least-Privilege-Prinzip. Wie so oft in Sicherheitsthemen geht es aber um die richtige Balance zwischen Managebarkeit und Risiko.
Beim klassischen Rollenmodellieren werden Mitarbeitende, die ähnliche Berechtigungen benötigen, in einer Rolle zusammengefasst. Die exakte Definition, was ein Role Mining Prozess liefern soll (Role Mining Problem, RMP), variiert in der Literatur. So ist auch die Frage: „Wie komplex – im Sinne von Computational Complexitity – ist denn klassisches Role Mining?“ nicht klar zu beantworten. Nur so viel: für die verschiedenen in [Vaidya et al, 2007] angegebenen Definitionen des Role Mining Problems, stellt sich heraus, dass RMP NP-vollständig [Hopcroft und Ullman, 2013] ist. Mit anderen Worten:
Role Mining ist ein komplexer und zeitaufwändiger Prozess.“
Sind die Rollen (z. B. nach dem Mining) einmal gefunden, bleibt die Frage: „Habe ich jetzt gegenüber der Vergabe von Einzelberechtigungen ein geringeres Risiko?“ Genau diese Frage wird beim klassischen Role Mining nicht wirklich beantwortet. Frage: „Warum haben die Mitarbeitenden Paul und Fred dieselbe Rolle?” Die Antwort im klassischen Role Mining würde lauten „weil Paul und Fred ähnliche/identische Einzelberechtigungen haben/benötigen“. Aber wie wäre es mit einer Antwort wie „Weil sie beide DevOps Engineers sind, die am Standort Buxtehude arbeiten“? Genau hier setzt das (maschinelle) Lernen von assoziativen Regeln (engl. Association Rule Learning, ARL) an.
 Dr. Steffo Weber ist Director Customer Engineering bei ForgeRock (Website). Er studierte Informatik in Bonn mit Schwerpunkt ‚Theoretische Informatik‘ und arbeitete in Bereichen wie Sicherheitsanalyse/Penetrationstests und hochverfügbare und skalierbare Internetarchitekturen (Finger im Schweröl). Seit 2015 ist er bei ForgeRock und begleitet dort mit seinem Team Kunden bei der Umsetzung ihrer CIAM Anforderungen (Finger im Leichtöl).
Dr. Steffo Weber ist Director Customer Engineering bei ForgeRock (Website). Er studierte Informatik in Bonn mit Schwerpunkt ‚Theoretische Informatik‘ und arbeitete in Bereichen wie Sicherheitsanalyse/Penetrationstests und hochverfügbare und skalierbare Internetarchitekturen (Finger im Schweröl). Seit 2015 ist er bei ForgeRock und begleitet dort mit seinem Team Kunden bei der Umsetzung ihrer CIAM Anforderungen (Finger im Leichtöl).Gegeben sei eine Menge I von Identity-/HR-Attributen wie Stellenbeschreibung, Standort etc. sowie eine Menge P von Privilegien (das können Einzelberechtigungen oder auch Rollen sein. Für das Verfahren macht das keinen Unterschied. Als Eingabe erhält ARL für jeden Nutzer/Identität ein Tupel (I,P) der Form
(i1, i2,…in, p1… pm)
Die i-Werte repräsentieren Identity-/HR-Attribute wie Stellenbeschreibung, Standort etc. Die p-Werte entsprechen Privilegien (das können Einzelberechtigungen oder auch Rollen sein. Für das Verfahren macht das keinen Unterschied). Gesucht werden Regeln der Form
i1 & i2, & … & in→ pj
Diese Regeln (der Begriff „Hypothese“ wäre eigentlich besser) repräsentieren Aussagen wie:
1. DevOps-Engineer & Buxtehude → Darf-Stash-Nutzen2. DevOps-Engineer & Buxtehude → Darf-den-Chef-feuern
3. DevOps-Engineer & Buxtehude → Hat-Root-Rechte-auf-allen-Servern
(ich verzichte aus Lesbarkeitsgründen auf eine exakte Behandlung der Indizes).
Während Hypothese 1 halbwegs plausibel erscheint, werden Hypothese 2 und 3 hoffentlich als unsinnig erkannt. Hierzu wird versucht zu ermitteln, wie gut sich eine Hypothese mittels der Eingabematrix (Tupel für alle Nutzer) stützen lässt. Das Ganze setzt eine brauchbare Eingabe voraus (Achtung! Garbage In, Garbage Out), damit Hypothesen wie (3) nicht statistisch gestützt werden können.
ForgeRock
ARL ist bewährt, sehr einfach und effektiv und vor allem im Gegensatz zu Verfahren aus dem Bereich Deep Learning nachvollziehbar und fällt somit in die Kategorie Explainable AI (XAI) (s. Wikipedia Explainable AI). ARL im Identity Umfeld sucht nach Begründungen, die auf Attributen des Personalsystems (HR) basieren (Standort, Job Title, Vorgesetzter etc).
Mittels ARL lassen sich Ausreißer (engl. Outlier) gut identifizieren: wenn jemand eine Berechtigung hat (wie Paul und Fred und viele ihrer Kollegen und Kolleginnen sie haben), aber nicht DevOps Engineer am Standort Buxtehude ist, so ist es sinnvoll zu prüfen, ob das eine Berechtigung ist, die fälschlicherweise (z. B. über eine ungünstig geschnittene Rolle) vergeben wurde, oder ob die gefundene Begründung eben etwas unscharf ist. Diese Ausreißer zu erkennen und gesondert zu prüfen, reduziert das Risiko erheblich.
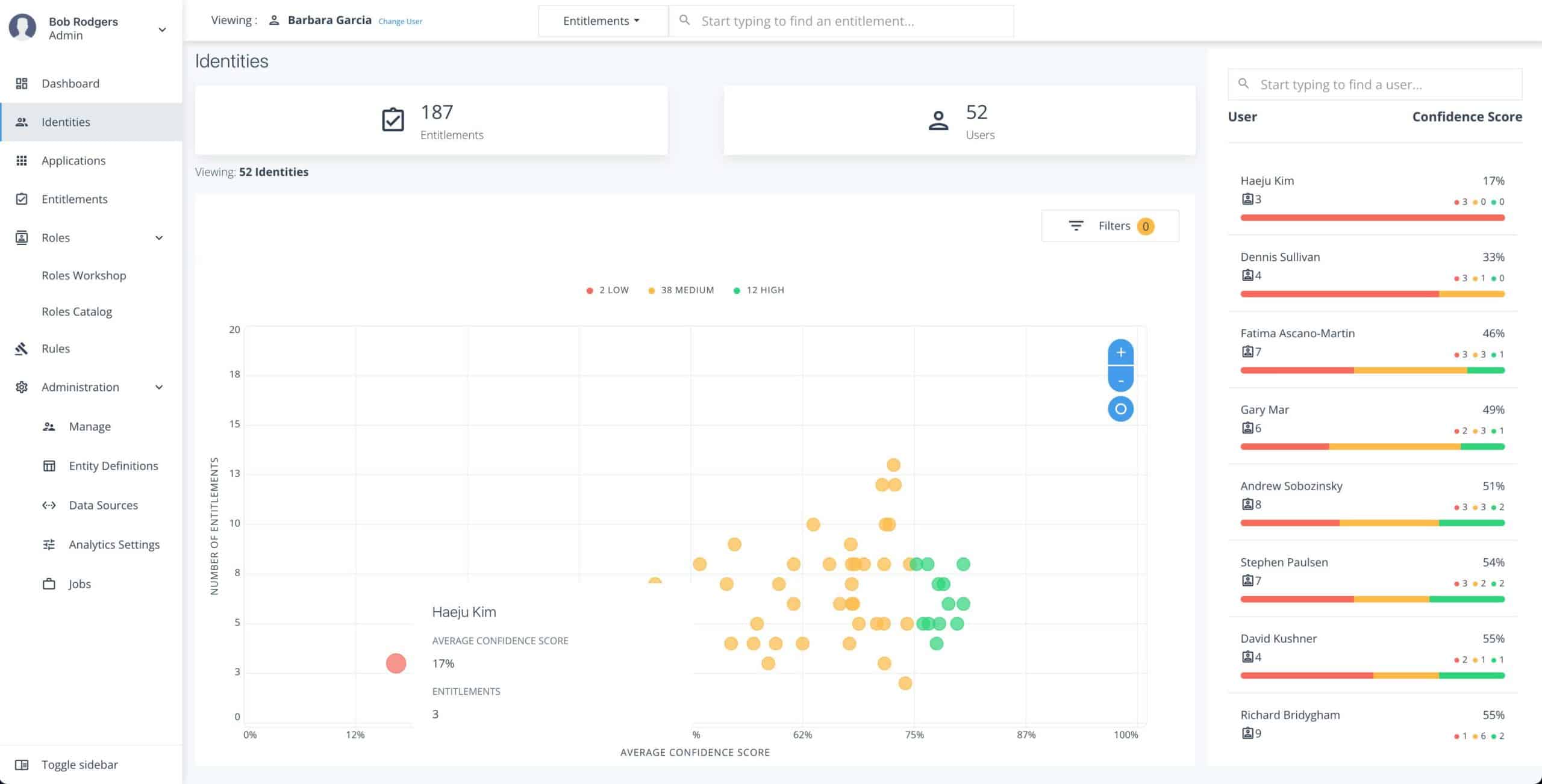
ForgeRock
Was ist nun besser: ARL oder klassisches Role Mining?
Das lässt sich leider so einfach nicht beantworten. Was ist besser Röntgen oder MRT? Antigentest oder PCR-Test? Beide verfügen über ähnliche Einsatzgebiete. Oftmals spielt aber der zeitliche Aufwand bei Risikoerkennung auch eine Rolle: es zählt nicht, dass ein Risiko erkannt wird, sondern auch wie schnell es erkannt wird.
ARL liefert neben der reinen Risikoerkennung aber auch einen substantiellen Beitrag zur Rollenmodellierung: wenn für unterschiedliche Berechtigungen dieselbe Hypothese akzeptiert wurde, dann können diese Berechtigungen in einer (sogar BaFin-kompatiblen) Rolle zusammengefasst werden. Akzeptiert man folgende Hypothesen
1. DevOps-Engineer & Buxtehude → Darf-Stash-Nutzen2. DevOps-Engineer & Buxtehude → Darf-Restore-einspielen
3. DevOps-Engineer & Buxtehude → Darf-VPCs-anlegen
können wir eine Rolle R mit den Berechtigungen {Darf-Stash-Nutzen, Darf-Restore-einspielen, Darf-VPCs-anlegen} aufsetzen. Dieser Ansatz entspricht nicht dem in der Literatur üblichem RMP, ist dafür aber auch weniger komplex und liefert kontinuierlich und schnell eine Lösung.
ARL kann somit problemlos zur Rollenmodellierung verwendet werden. Darüber hinaus ist es hinsichtlich des Erklärungspotenzials deutlich informativer als Role Mining.
Für Unternehmen, die bereits ein klassisches Role Mining Tool erfolgreich im Einsatz haben, kann ARL eine wertvoller Baustein zu einem diversifizierten Rollenmodellierungsprozess sein und eine zweite, unabhängige Sicht liefern.“
ARL kann täglich/kontinuierlich laufen (dank Apache SPARK und Scale-Out Architektur), um das aktuelle Risiko zu ermitteln. Damit können die Erklärungen von ARL in Governance-Prozessen (z. B. Fred beantragt Rolle/Recht X) direkt von Genehmiger/Zertifizierer als Entscheidungsgrundlage (Decision Support) verwendet werden. Dies kann mittels Anwendungsintegration via REST soweit gehen, dass bei geringem Risiko die Rolle/Recht automatisch genehmigt/zertifiziert wird.
[Hopcroft and Ullman, 2013] Introduction to Automata Theory, Languages, and Computation (3rd ed.), Hopcroft, John E.; Motwani, Rajeev; Ullman, Jeffrey D, Pearson, 2013.
[Vaidya et al, 2007] The Role Mining Problem: Finding a Minimal Descriptive Set of Roles, Jaideep Vaidya, Vijayalakshmi Atluri and Qi Guo. In SACMAT’07, PROCEEDINGS OF THE 12TH ACM SYMPOSIUM ON ACCESS CONTROL MODELS AND TECHNOLOGIES, Association for Computing Machinery, New York, 2007.
Fazit
Versicherer müssen sich auf zunehmend strengere VAIT-Prüfungen durch die BaFin einstellen. Im Bereich des Berechtigungsmanagement gibt es die Möglichkeit, ARL-basierte Lösungen für
- Risikominimierung
- Decision Support
- Role Mining
einzusetzen. Das ist nicht nur sinnvoll für Unternehmen, die zurzeit über gar keine technische Lösung verfügen, sondern auch für solche, die die Ergebnisse einer existierenden Role-Mining-Lösung überprüfen wollen (als zweite Meinung sozusagen).Dr. Steffo Weber, ForgeRock
Sie finden diesen Artikel im Internet auf der Website:
https://itfm.link/133360


Schreiben Sie einen Kommentar