Hadoop – ernstzunehmende Big-Data-Alternative für Banken und Versicherungen
Apache.org
Was hat ein kleiner gelber Elefant mit Banken und Versicherern zu tun? Sehr viel – denn es geht um professionelle Big-Data-Lösungen mit einem Open-Source-Framework. Hadoop ermöglicht neuartige und gleichzeitig kostengünstigere Optionen im Datenmanagement und hilft auch dabei, aus Compliance-Projekten Business-Mehrwerte zu generieren. Ein Plädoyer für den Einsatz der Open-Source Big-Data-Plattform bei Banken und Versicherern.
Die Autoren
Oliver Herzberg verantwortet in der metafinanz den Themenbereich Projekt Support und berät Kunden in Fragen zu IT-Management und IT-Strategie vor dem Hintergrund langjähriger operativer und strategischer Erfahrung für Datawarehouse und BI-Systeme im Umfeld Banksteuerung. Carsten Herbe, zuständig für Data Warehousing und Hadoop in der metafinanz, berät seine Kunden wie sie durch den Einsatz von Hadoop Kosten im DWH sparen und neue Analysen ermöglichen können.
von Oliver Herzberg und Carsten Herbe, metafinanz
Die Zeiten üppiger Technologiebudgets und aufwändiger Individualfertigung vorbei – und trotzdem: die IT bildet das Rückgrat des Geschäftsbetriebs. Die Unternehmen setzten heute auf mehr Effizienz durch Industrialisierung, und die IT muss sich unter diesen Voraussetzungen serviceorientierter aufzustellen und das Zusammenspiel mit den Geschäftsbereichen neu zu organisieren.
Regulatorik treibt die IT
Der wachsenden Bedeutung der IT tut das keinen Abbruch, denn die Einsatzszenarien weiten sich aus. Im Zentrum des Interesses steht hier vor allem das ungebremste Datenwachstum – als Technologie- und Kostentreiber. Im Assekuranzumfeld befeuern vor allem die regulatorischen Anforderungen wie Solvency II, Basel III, IFRS, EBA Reporting oder aktuell BCBS239 die Datenflut. Das bestätigt auch eine Untersuchung des Marktforschungsunternehmens Lünendonk, wonach allein Solvency II die Branche bis 2020 belasten wird.
Compliance-Projekte mit Geschäftsnutzen kombinieren
Solvency & Co. bereitet den Versicherern vor allem deshalb Kopfzerbrechen, weil hier aufwändige IT-Investitionen getätigt werden, die lediglich der Einhaltung von Richtlinien dienen. Dabei werden Ressourcen in der IT und den Fachbereichen gebunden, ohne dass das Geschäft verbessert oder die Produktivität gesteigert würde. Erschwerend kommt aufgrund enger Fristen der hohe Umsetzungsdruck hinzu. Somit konzentriert man sich derzeit oft auf Zwischenlösungen, um Zeit zu gewinnen. Für die finale Lösung kommen später noch einmal Projektkosten hinzu.
Das Datenwachstum ist auch Kontext des aktuellen Megatrends der „Digitalen Transformation“ zu betrachten. IT dringt in die letzten Winkel des Alltaglebens vor, und das bedeutet schlicht eine weitere starke Zunahme von datenliefernden Geräten – und daraus leitet sich wiederum ein steigender Bedarf an Datenmanagement und Analyse-Lösungen ab. Interessant ist in diesem Zusammenhang auch der Wandel von Geschäftsmodellen. Startups wie Uber oder Whatsapp fordern etablierte Branchen mit IT-zentrischen Geschäftsmodellen heraus. Um in diesem Umfeld zu bestehen und fit zu werden für neuartigen Wettbewerb, gewinnt das strategische Management interner und externer Daten enorm an Bedeutung.
Leistungsfähige, flexible und elastische DWH- und BI-Infrastrukturen wirken vor allem in künftigen Changekostenmetafinanz
Big Data ausgereizt?
Die simple Antwort auf die geschilderte Entwicklung lautete in den letzten Jahren „Big Data“. Unter diesen Oberbegriff wurde alles subsummiert, was mit Speichern, Verwalten und Verarbeiten von umfangreichen Datenvolumina zu tun hat. Doch der Hype ist inzwischen etwas abgekühlt, was nicht zuletzt an der oft großspurigen Positionierung des Themas liegen dürfte. Im Vordergrund standen meist prestigeträchtige Megaprojekte, die sehr kostspielig sind und erst nach längerer Zeit geschäftlichen Nutzen versprechen. Das war den CIOs bisher meist zu abstrakt, denn sie stehen mehr auf pragmatische Herangehensweisen, wie eine Gartner-Studie ergab. Auf die Frage nach den größten Herausforderungen bei Big Data und Analytics schlossen sich die meisten Entscheider der Aussage an: „Wie man am schnellsten Mehrwerte aus großen Datenbeständen generieren kann.“
Hadoop – die universelle Alternative, auch für BI
Wenn also die Unternehmen nicht um eine Beschäftigung mit den wachsenden Datenmengen herumkommen, so stellen sie sich die Frage, welche Mittel sich dafür am besten eignen. Gesucht ist eine Plattform, die sich für aktuelle und zukünftige Herausforderungen eignet – und dabei die kritischen Punkte Kosten, Flexibilität und Innovation gleichermaßen adressiert. Als heißer Kandidat dafür bietet sich die noch junge Technologie Hadoop an. Der große Vorteil von Hadoop als Datenplattform liegt darin, dass Einführungen mit kleinen Projekten starten können, die zunächst einmal auf aktuelle und pragmatische Ziele wie Konsolidierung und Kostensenkung fokussiert sind.
Das Open-Source-Framework zeichnet sich vor allem durch folgende Eigenschaften aus: 1. Hadoop bietet neue, bisher nicht umsetzbare Analytics-Möglichkeiten 2. Hadoop ermöglicht konkrete Einsatzszenarien, um die Infrastruktur- und Speicherkosten zu senken
Hadoop punktet vor allem beim dezentralen Speichern und parallelen Verarbeiten von sehr großen Datenmengen. In Verbindung mit dem MapReduce-Framework ermöglicht es eine parallele Verarbeitung von strukturierten und unstrukturierten Daten. Hadoop-Cluster skalieren linear, was bedeutet, dass 10 Prozent mehr Knoten die Speicherkapazität um 10 Prozent erweitern und die Leistung um 10 Prozent steigt. Ein weiterer Vorteil von Hadoop ist das mittlerweile große Ökosystem an Tools, das vielfältige Erweiterungsmöglichkeiten wie beispielsweise Datenauswertungen mit SQL bietet.
Hadoop eignete sich auch von der Zielsetzung her für viele klassische BI-Szenarien, dabei kommen aber teilweise völlig andere Methodiken und Herangehensweisen zum Einsatz. So sind in der klassischen BI-Welt beispielsweise klar definierte Projektziele typisch – ob es sich dabei um den Aufbau eines Near-Time-Reportings, eines Management Cockpits oder eines Dashboards für das GuV-Stresstestings handelt. Hadoop-Projekte hingegen gestalten sich eher zumindest am Anfang oftmals als Forschungs- und Entwicklungsprojekte, beispielsweise wenn es um Themen wie Data Exploration geht. Die IT stellt hierbei eine Plattform zur Verfügung, auf der das Business herausfinden kann, welche Fragen gestellt werden können.
Einsatzszenarien mit Hadoop
Aktuell sind folgende drei grundlegenden Einsatzszenarien mit Hadoop interessant: 1. RDBMS Offload: Hadoop-Cluster ermöglichen die Optimierung von Speicherplatz, um etwa bestehende, komplexe ETL-Prozesse oder klassische Datenbanksysteme zu ersetzen. 2. DWH-Extension: Bestehende Datawarehouses lassen sich durch Hadoop funktional erweitern, indem vorgeschaltete ODS-Datensammler eingesetzt werden. 3. Big Data Exploration: Big Data-Anwendungen, die Daten unterschiedlichster Quellen sammeln sowie Data Mining und Machine Learning ermöglichen.
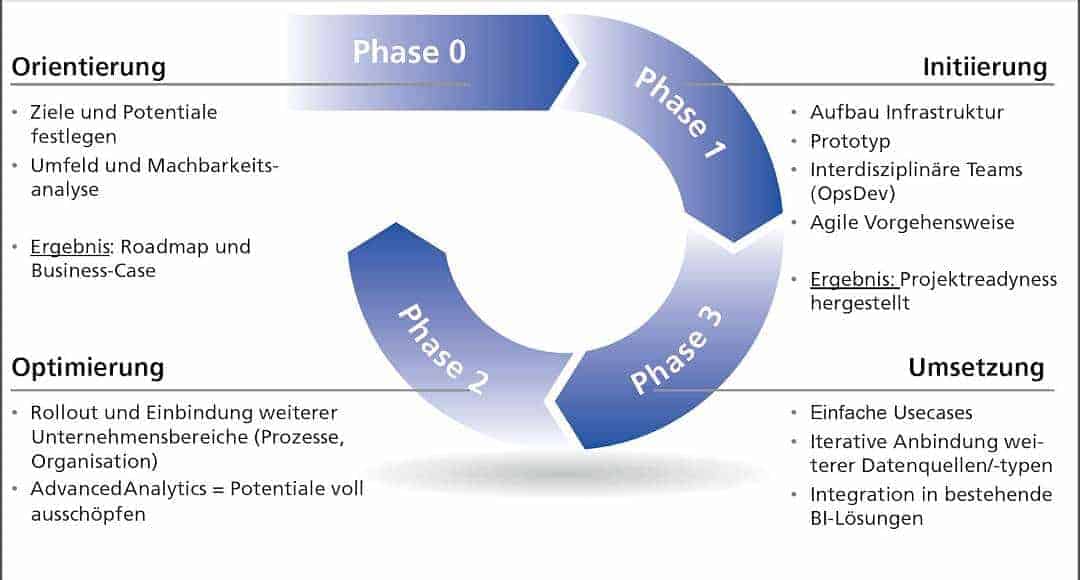
Vorgehensmodell
Iteratives Vorgehensmodell zur Einführung von Hadoop umfasst vier Kernphasenmetafinanz
Um Hadoop erfolgreich als Big-Data-Lösung einzuführen, empfiehlt sich ein iteratives Vorgehensmodell, das aus folgenden vier Phasen besteht: 1. Orientierungsphase: Strategieentwicklung, Ermittlung des Business-Value und Beispiele für Use-Case 2. Aufbau der Infrastruktur, Prototyp, Durchstich front to back 3. Umsetzung mit einfachen Use-Cases für einen Quick-Win, Stufenweiser Ausbau (Daten) und Integration (Prozesse und Organisation) 4. Optimierung: Unternehmensweite Integration von Big Data und Advanced Analytics
Use-Cases für die erfolgreiche Einführung von Hadoop
Folgender Beispielszenarien stellen einige Möglichkeiten von Hadoop dar und sowie deren konkreter geschäftlicher Nutzwert anschaulich machen.
Beispiel 1: „Strategische Personalentwicklung auf Basis von Datenanalyse“
Bei der personellen Besetzung von IT-Projekten muss eine HR-Abteilung schnell auf Kundenanfragen reagieren können und dabei einen schnellen Überblick über vorhandenen Kompetenzen im Unternehmen verschaffen. Wenn es um die Entwicklung des eigenen Personals geht, müssen die Skills der Mitarbeiter ständig mit den Marktbedürfnissen verglichen und daran ausgerichtet werden. Das Problem: Die Informationen über Skills liegen strukturiert wie unstrukturiert in Projekthistorien, Schulungsplänen, Gehaltsspiegeln der Branche und internen wie externen Stellenausschreibungen vor. Zu Projektbeginn ist unklar, ob die Daten sich in Beziehung setzen lassen.
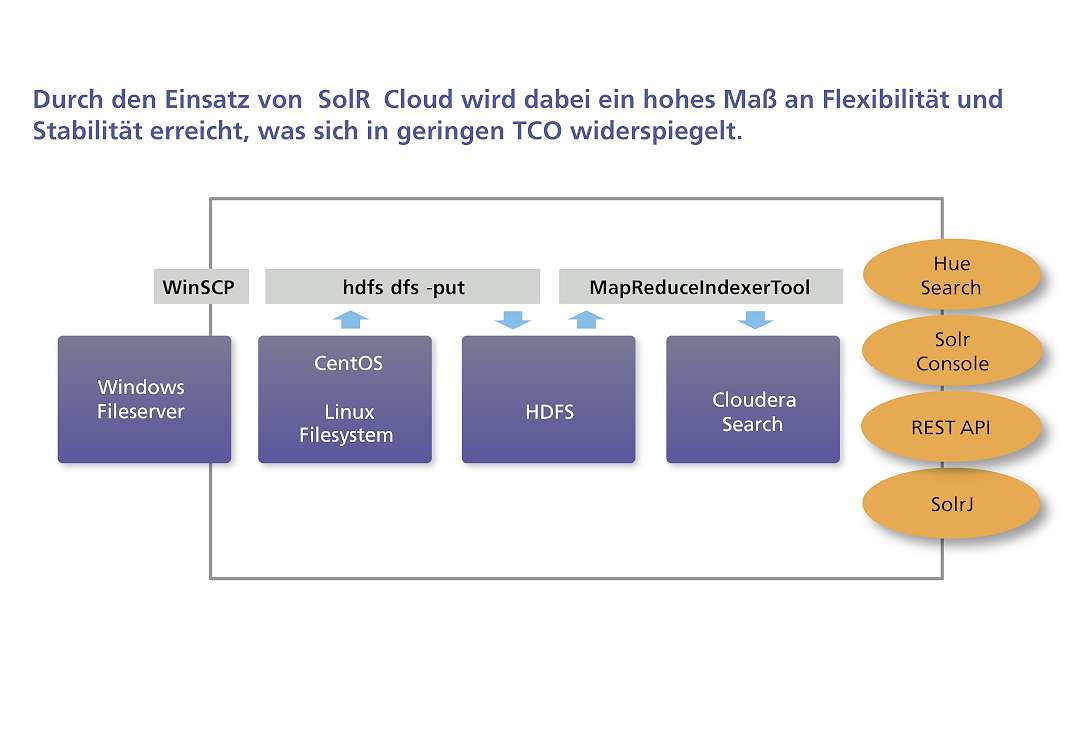
Herangehensweise mit Hadoop: Mitarbeiterprofile werden nach HDFS geladen und mit MapReduce indiziert. Auswertungen sind über Velocity, Solr Console, REST API und SorJ auf den Originaldaten möglich. Durch den Einsatz von SolR Cloud wird ein hohes Maß an Flexibilität und Systemstabilität erreicht. Bereits in dieser Phase kann das Unternehmen bei Kundenanfragen feststellen, ob das Knowhow vorhanden ist.
Im zweiten Schritt werden die ERP-Daten integriert, um Mitarbeiter mit Projekt und Laufzeit zu ermitteln. Im dritten Schritt folgen Daten aus öffentlichen Quellen wie Stellenbörsen. Das Unternehmen kann dann schnell auf Anfragen reagieren und Skills strategisch und an den Kundenbedürfnissen orientiert weiterentwickeln.
Mit der Hadoop Search API kann der Personalstamm performant analysiert werdenmetafinanz
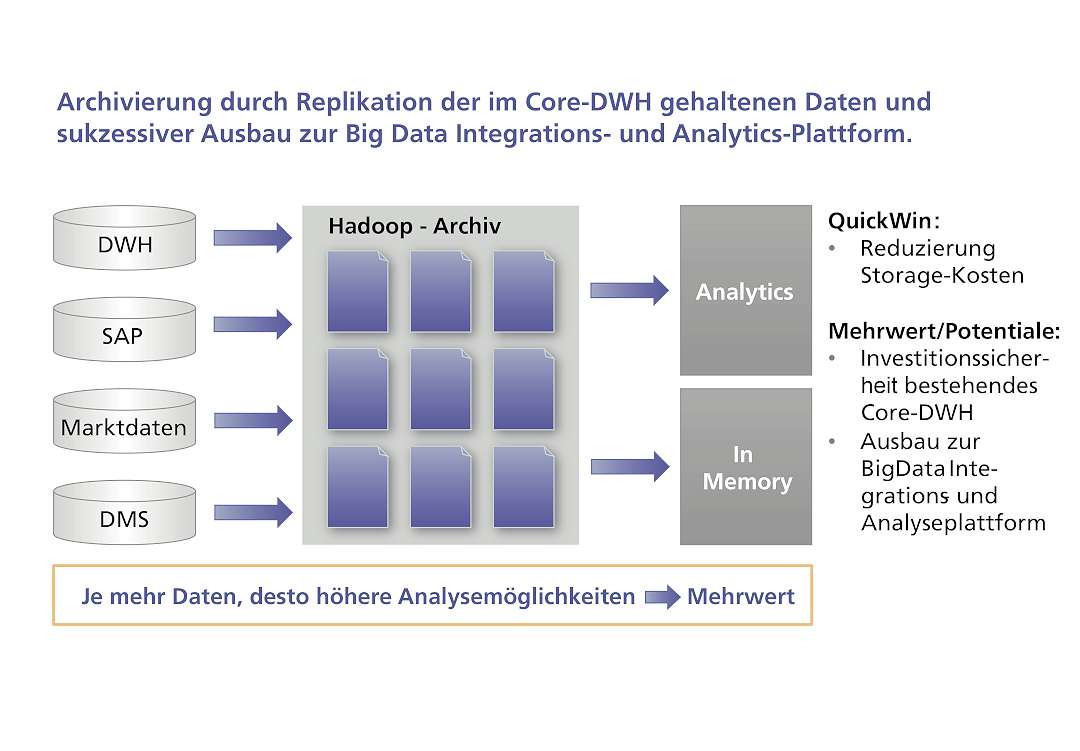
Beispiel 2: Effizientere Datenarchivierung
Zur Erfüllung der GOBS (Grundsätze ordnungsgemäßer Buchführungssysteme) oder der GdPdU (Grundsätze zum Datenzugriff und zur Prüfbarkeit digitaler Unterlagen) müssen geschäftsrelevante Daten zehn Jahre archiviert werden. Die Archivierung von Daten erfolgt oft im Datawarehouse oder in speziellen Archivierungs-Marts und verursacht so hohe Kosten. Durch Weiterentwicklung von Software und Dateiformaten steigt der Aufwand, gespeicherte Daten erneut zu laden und zu verarbeiten.
Lösungsansatz mit Hadoop: Die in Data-Marts gehaltenen Daten werden in den Hadoop-Cluster repliziert. Der Quickwin besteht darin, dass sich die Speicherkosten reduzieren, da alle älteren Daten aus dem Data Mart gelöscht werden.
Im nächsten Schritt werden die Archivdaten, die in unterschiedlichsten Formaten vorliegen, in das Hadoop-Cluster geladen, wo sie analysiert und verarbeitet werden können. Und dies in der Regel mit den gleichen BI Tools und Reports, mit denen auch schon die Daten in der relationalen Datenbank ausgewertet werden. Möglich machen dies Technologien wie Hive, für welches viele Tool-Hersteller schon eine Schnittstelle anbieten.
Zentrale Archivierung mit Hadoopmetafinanz
Hapoop bringt neue Konzepte des Datenmanagements
Die Beschäftigung mit Hadoop setzt die Bereitschaft voraus, neue Themenfelder zu betreten und sich mit neuen Konzepten des Datenmanagements zu befassen. Noch sind Best Practices dünn gesät und müssen sich erst etablieren. Generell empfiehlt es sich, mit kleinen Projekten anzufangen, ein Gefühl für die Technologien und ihre Möglichkeiten zu entwickeln und darauf aufbauend eine dem Unternehmen adäquate Strategie zu erarbeiten.
Hadoop macht keinesfalls klassische Datawarehouses oder relationale Datenbaken überflüssig, sondern ergänzt und erweitert diese. Damit sind die Investitionen in bestehende DWH-, BI- und Reporting-Infrastrukturen gesichert. Gleichzeitig eröffnet Hadoop neue Potenziale für Analytics auf der einen und Kosteneinsparungen auf der anderen Seite. Vor dem Hintergrund steigender Ansprüche im Bereich Datenmanagement empfiehlt es sich damit als ideale Plattform für Konsolidierungen, innovative Lösungen und Geschäftsmodelle der Zukunft.aj
Sie finden diesen Artikel im Internet auf der Website: https://itfm.link/14800


 Oliver Herzberg verantwortet in der metafinanz den Themenbereich Projekt Support und berät Kunden in Fragen zu IT-Management und IT-Strategie vor dem Hintergrund langjähriger operativer und strategischer Erfahrung für Datawarehouse und BI-Systeme im Umfeld Banksteuerung.
Oliver Herzberg verantwortet in der metafinanz den Themenbereich Projekt Support und berät Kunden in Fragen zu IT-Management und IT-Strategie vor dem Hintergrund langjähriger operativer und strategischer Erfahrung für Datawarehouse und BI-Systeme im Umfeld Banksteuerung. Carsten Herbe, zuständig für Data Warehousing und Hadoop in der metafinanz, berät seine Kunden wie sie durch den Einsatz von Hadoop Kosten im DWH sparen und neue Analysen ermöglichen können.
Carsten Herbe, zuständig für Data Warehousing und Hadoop in der metafinanz, berät seine Kunden wie sie durch den Einsatz von Hadoop Kosten im DWH sparen und neue Analysen ermöglichen können.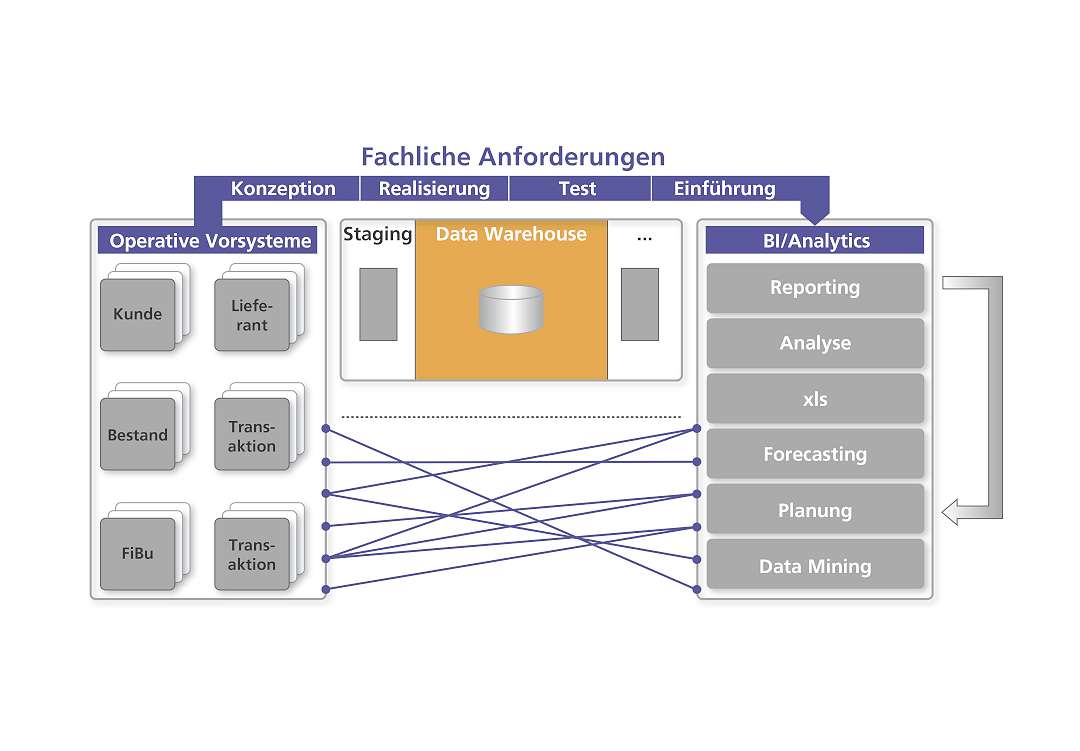


Schreiben Sie einen Kommentar