BCBS 239: Worauf man technisch beim Aufbau eines granularen Datenhaushaltes achten muss
leowolfert/bigstock
Der Standard zur Risikodatenaggregation – BCBS 239 – stellt die großen Banken vor große Herausforderungen, insbesondere wenn es darum geht, die Anforderungen auch technisch zu lösen. Die eigentliche Aufgabe in der Gestaltung von BCBS 239-konformen Lösungen und Zielbildern besteht häufig darin, die einzelnen Anforderungen parallel/simultan erfüllen zu müssen, woraus sich Zielkonflikte ergeben können. Der Praxis-Ratgeber der KPMG.
Die Risikodatenaggregation nach BCBS 239 ist hinterhältig: Eine vermeintlich pragmatische und kostengünstige Lösung zur Erfüllung der einen Anforderung kann in der Umsetzung dazu führen, dass anderer Anforderungen deutlich aufwändiger zu realisieren sind. Als Beispiel sei hier Anforderung der Abstimmbarkeit von Daten genannt, die durch einen übergreifenden Datenhaushalt auf Basis eines vereinheitlichten Datenmodells inhärent gegeben ist, jedoch in einer Architektur mit mehreren parallelen Verarbeitungssträngen mit jeweils eigener Datenhaltung deutlich aufwändiger zu realisieren ist.
Die richtige Wahl der (Ziel-)Architektur
Eine zentrale Aufgabe zur Erfüllung von BCBS 239 liegt im Aufbau eines oder mehrerer granularer Datenhaushalte zur Erfüllung der Forderung nach einer Single Source (pro Risikoart) als Grundlage für das Risikomanagement. Diese Anforderung stellt in der Praxis jedoch oft nur eine Nebenbedingung bei der Definition einer geeigneten IT Zielarchitektur dar. Grundsätzlich stellt sich hier die Frage nach der generellen Ausrichtung und damit des Zielbildes für die Unternehmenssteuerung, welche wiederum im Einklang mit den strategischen Zielen entschieden werden sollte, um eine grundsätzlich zukunftssichere Architektur umzusetzen.
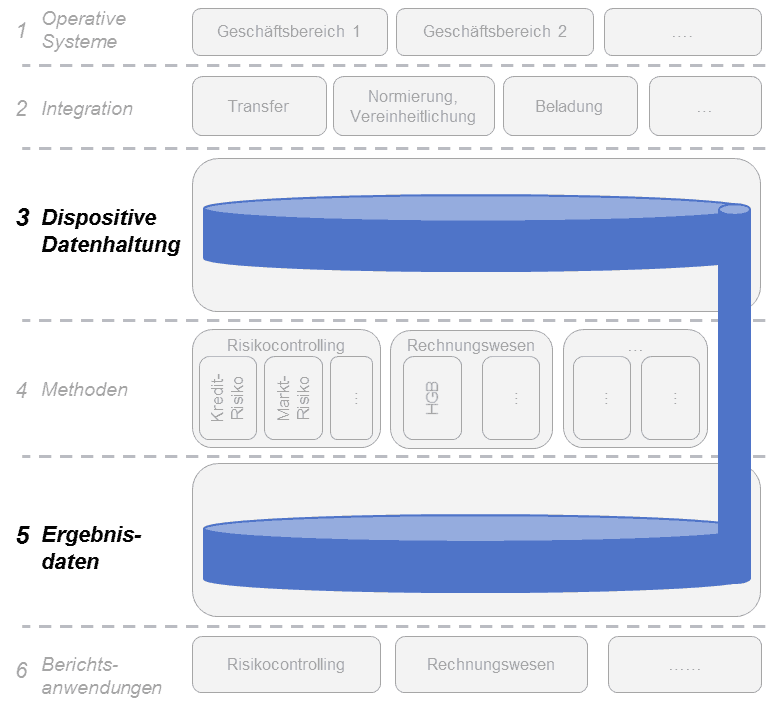
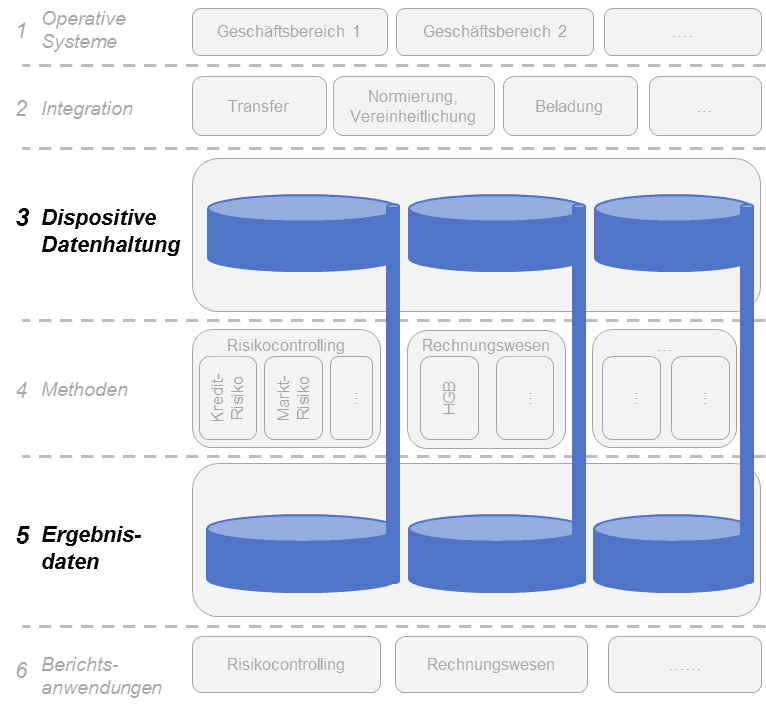
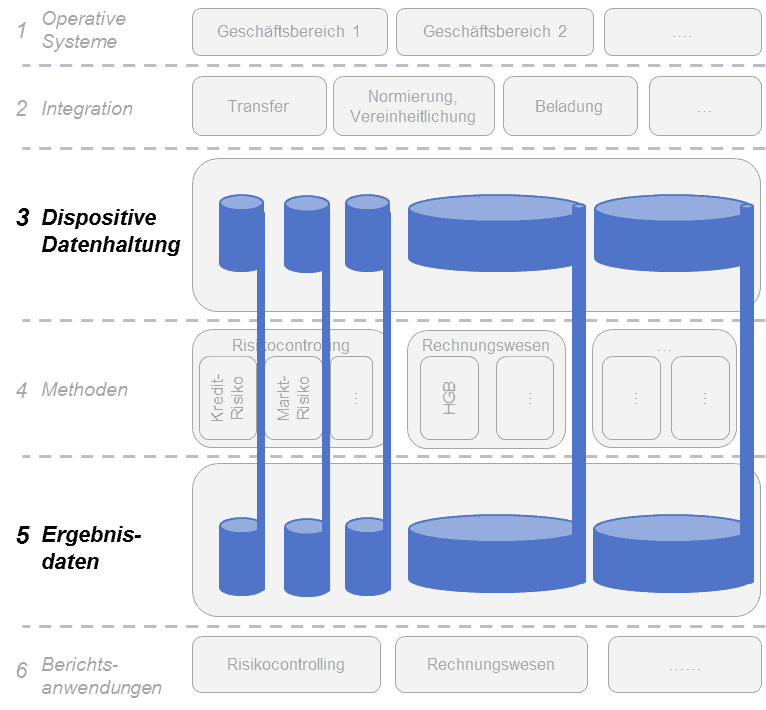
Die folgende Grafik zeigt anhand eines generischen 6-Schichten-Modells drei Umsetzungsalternativen für die Schichten der dispositiven Datenhaltung sowie der Ergebnisdaten:
Alternative 1: Zentraler Datenhaushalt über alle Steuerungssichten hinweg
Alternative 1: Zentraler Datenhaushalt über alle Steuerungssichten hinwegKPMG
Alternative 2: Zentraler Datenhaushalt pro Steuerungssicht
Alternative 2: Zentraler Datenhaushalt pro SteuerungssichtKPMG
Alternative 3: Datenhaushalt pro Risikoart (Mindestanforderung von BCBS 239)
Alternative 3: Datenhaushalt pro Risikoart (Mindestanforderung von BCBS 239)KPMG
Die drei Alternativen unterscheiden im prinzipiell in der Anzahl unterschiedlicher Datenhalte und deren Schnitt. Unabhängig davon ist jedoch allen Zielarchitekturen gemein, dass Ergebnisdaten aus den jeweiligen Rechenkernen (Methodenschicht) im jeweiligen Datenhaushalt mit den Roh-/Ursprungsdaten (soweit möglich auf granularer Ebene) verknüpft werden.
Bei der Wahl der geeigneten Zielarchitektur gibt es Reihe von Kriterien, die Berücksichtigung finden sollten.
Zukunftssicherheit:Die Antizipation zukünftiger, aufsichtsrechtlicher aber auch interner Anforderungen bzw. die Flexibilität sich auf diese einstellen zu können, ist entscheidend. Als aktuelle Beispiele seien AnaCredit bzw. die Veränderung der Aufsichtspraxis der EZB im Zuge des SSM genannt, die zur vermehrten Abfrage granularer Datenwürfel und der Notwendigkeit zur Kombination von Daten aus unterschiedlichen Fachbereichen führen.
Scope des Datenhaushaltes:Die Integration von Daten aus anderen Bereichen der Unternehmenssteuerung wie Accounting, Meldewesen oder Controlling wird immer wichtiger, sodass der primäre Fokus von BCBS 239 – also die Verbesserung des Risikomanagements – lediglich eine Nebenbedingung sein kann.
Granularität der Datenanlieferung: Grundsätzlich lässt sich hier in der Praxis klar eine Tendenz zu granularen Daten auf Einzelgeschäftsebene feststellen. Im Rahmen der Konzeption stellen sich dann jedoch Detailfragen wie beispielsweise nach der Abbildung von granularen Cashflows, nach der Abbildung auf Bestand- oder Trade-Ebene oder der Modellierung sämtlicher (ggf. nicht materieller) Töchter oder Beteiligungen, die unter Umständen die Komplexität des Datenmodells auf Grund spezifischer Produkte erhöhen können.
Frequenz der Datenanlieferung: Abhängig von der Wahl des Scopes und der Granularität muss auch technisch sichergestellt sein, Daten zu unterschiedlichen Frequenzen für unterschiedliche Zwecke verarbeiten und vorhalten zu können. Hier sollten auch bereits zukünftige Entwicklungen berücksichtigt werden wie eine mögliche untertägige Berechnung von Liquiditätskennzahlen oder Marktrisiken.
Simulations- und Stresstestfähigkeit: Neben den Standardprozessen sollte bereits bei der Festlegung der Ziel-Architektur bedacht werden, an welcher Stelle sowohl Bestände als auch Parameter für die Berechnung von Stresstests oder anderer Szenarien erfolgen soll.
Grundsätzlich gilt: Je integrierter der Datenhaushalt ist, der die einzelnen Rechenkerne wie die Risikodisziplinen, das Accounting oder das Meldewesen beliefert, umso einfacher lassen sich Bestände für Stress- oder Simulationsszenarien abbilden, da diese im Idealfall nur an einer Stelle – auf Ebene des dispositiven Datenhaushaltes – vorgenommen werden müssen. In den einzelnen Fachbereichen sind dann lediglich modellspezifische Parameter pro Rechenkern für den jeweiligen Stress-/Simulationslauf anzupassen. Ist dies architektonisch nicht gegeben, müssen die Bestände entweder auf Ebene der juristischen Bestandssysteme oder der jeweiligen Rechenkerne mehrfach generiert und vorgehalten werden.
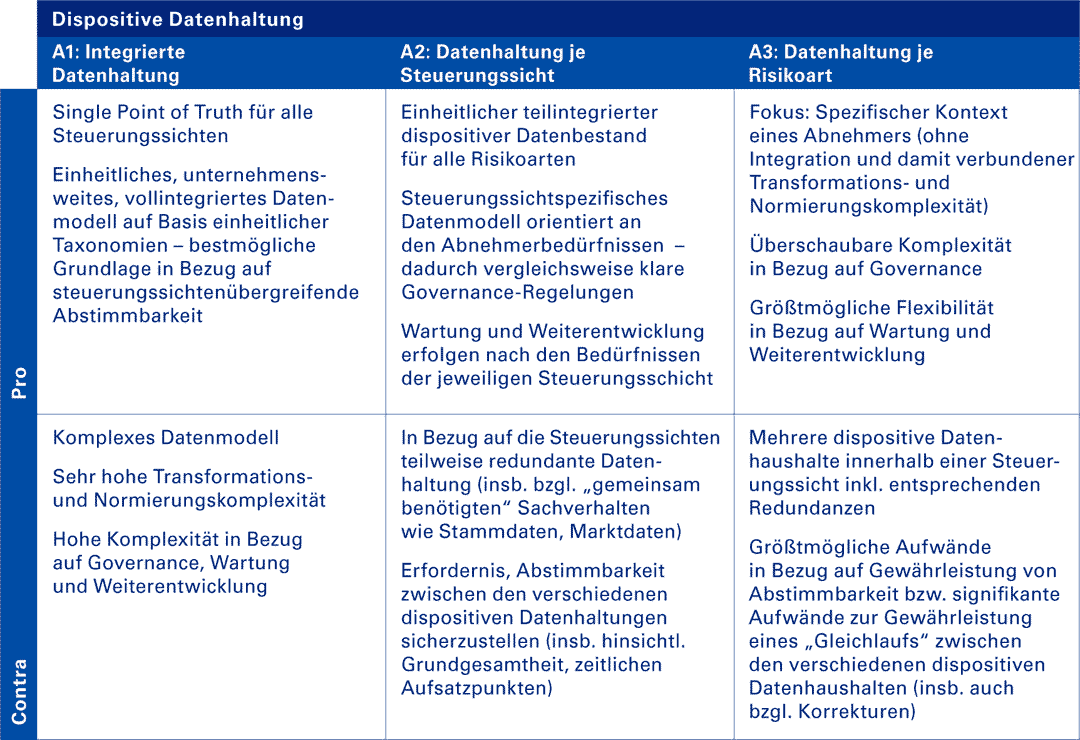
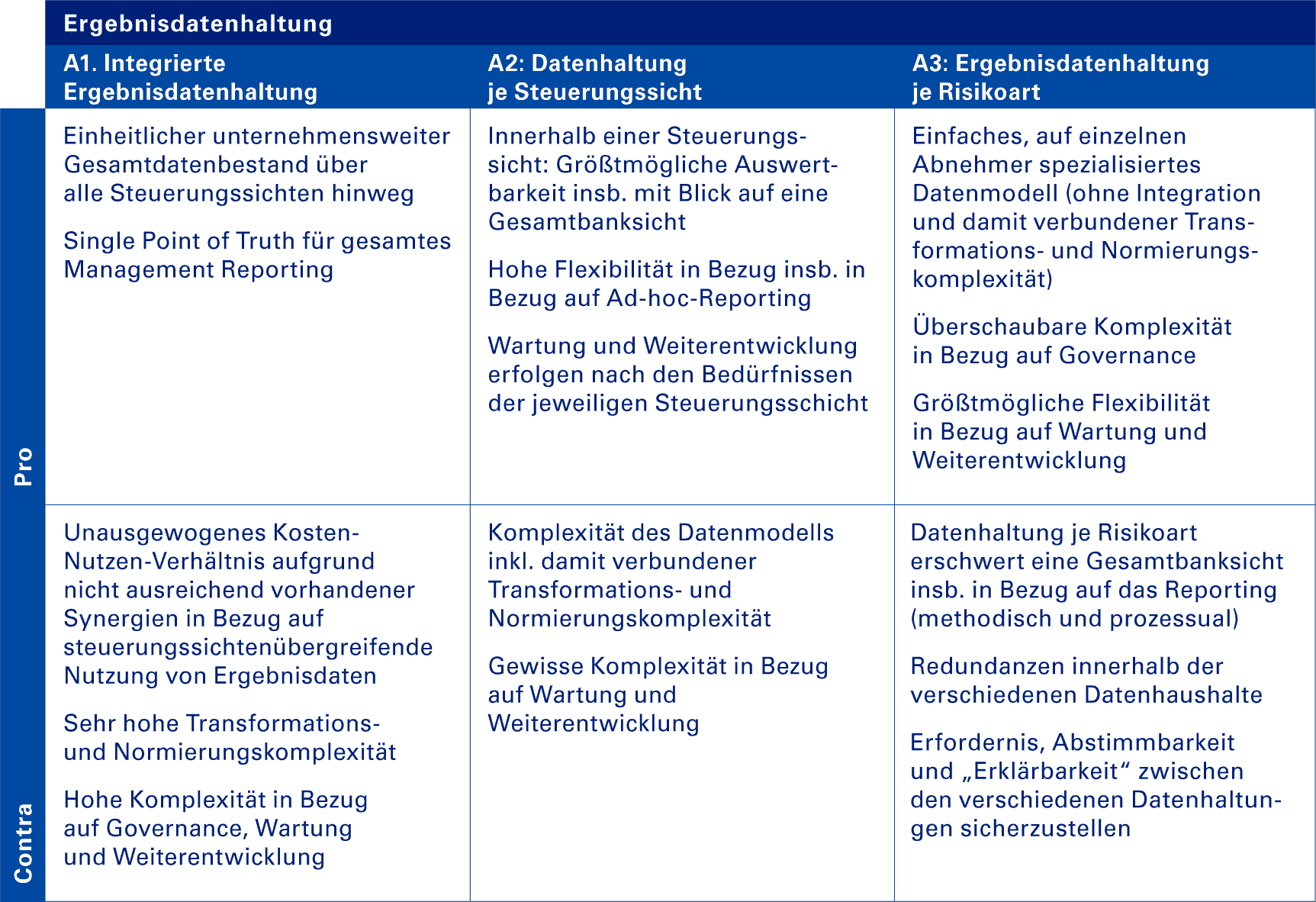
Betrachtet man dem oben beschriebenen Alternativen gemäß der erläuterte Kriterien, ergibt sich folgendes Bild, das helfen kann, die geeignete und passende Zielarchitektur festzulegen.
Vor- und Nachteile für die dispositive Datenhaltung
KPMG
Vor- und Nachteile für die Ergebnisdatenhaltung
KPMG
Die richtige Umsetzung der (Ziel-)Architektur
Nachdem die Entscheidung für die Zielarchitektur gefallen ist, ergeben sich im konkreten Design der technischen Lösung sowie der Realisierung ebenfalls diverse Fragestellungen deren Beantwortung sowohl für die Erfüllung von BCBS 239 sowie für die zukünftige Verwendung der Lösung wichtige Implikationen haben. Im Folgenden sollen zwei dieser Aspekte exemplarisch erläutert werden.
Verarbeitungsstrategie: Ziel ist es, alle Daten in der notwendigen Qualität, zum richtigen Zeitpunkt bzw. in der richtigen Frequenz verarbeiten zu können. Entscheidungen sind aber für den Fall zu treffen, dass beispielsweise einzelne Datensätze Mängel aufweisen, diese also nicht der geforderten Datenqualität entsprechen. Grundsätzlich gibt es in diesem Fall drei Alternativen:
1. Abbruch der Verarbeitung 2. Weiterverarbeitung ohne die betroffenen Datensätze 3. Weiterverarbeitung mit den betroffenen Datensätzen
Die Autoren
Marco Lenhardt ist global verantwortlicher Partner für das Thema BCBS 239 – Principles for Risk Data Aggregation & Reporting“ und leitet den Bereich Regulatorik für Financial Services innerhalb von KPMG Deutschland. Daneben hat er diverse Umsetzungsprojekte der Anforderungen aus „Basel III/CRD IV“ und externen Reportinganforderungen aus FINREP und COREP betreut.
Dirk Kayser ist Senior Manager bei KPMG und seit mehr als 11 Jahren Unternehmensberater für Banken und Versicherungen. Dabei spezialisierte er sich auf die Umsetzung von regulatorischen Anforderungen in Bezug auf technische und prozessuale Lösungen. Aktuell leitet er mehrere BCBS 239 Umsetzungsprojekte und koordiniert Produktentwicklungen in diesem Umfeld.
Um die angestrebten und sich deutlich verringernden Verarbeitungszeiten einhalten zu können, wird in vielen Banken von Alternative 1 Abstand genommen, da in diesem Fall eine Verarbeitung nur dann stattfinden kann, wenn die Datenqualität 100% beträgt was insbesondere bei Massendaten unrealistisch erscheint. Außerdem wird es durch die Umsetzung immer umfangreicherer und automatisierter Datenqualitätsprüfungen auch immer vermeintliche Fehler geben, die sich erst durch eine anschließende Analyse als wirkliche Fehler oder nur als Auffälligkeiten klassifizieren lassen.
In der Diskussion der verbleibenden Alternativen setzt sich häufig eine Argumentationskette durch, die für die Verarbeitung mit den mangelhaften Datensätzen spricht (Alternative 3), um zumindest das Kriterium der Vollständigkeit der Grundgesamtheit aller Datensätze bestmöglich erfüllen zu können. Grund hierfür ist, dass sich die datenverwendenden Fachbereiche (Risikomanagement, Meldewesen etc.) regulatorisch nicht dadurch besser stellen wollen, dass Datensätze gar nicht verarbeitet werden, da dies in einer Unterschätzung des Risikos oder der Eigenkapitalanforderungen resultieren könnte. Man muss die Datenqualitätsmängel also in zwei Kategorien unterteilen.
Zum einen gibt es die Datensätze, die auf Grund von Mängeln technisch nicht weiterverarbeitet werden können, zum Beispiel weil diese auf Grund von Formatverletzungen nicht in den Datenhaushalt geladen werden können oder weil Regeln zur referentiellen Integrität verletzt werden. Zum anderen existieren Datensätze, die zwar technisch verarbeitbar sind, aber dennoch einen Mangel aufweisen, wie beispielsweise fehlende Einträge in fachlichen Pflichtfeldern, Wertbereichsverletzungen oder Inkonsistenzen von Inhalten verschiedener Felder. Erstere müssen über einen möglichen Korrekturprozess oder erneute Verarbeitungen berücksichtigt werden, letztere können in der Verarbeitung berücksichtigt werden, mögliche Auswirkungen des Mangels sind jedoch zu analysieren.
In jedem Fall sind die identifizierten Mängel einem geordneten Regelprozess zur nachhaltigen Verbesserung der Datenqualität zuzuführen.
Korrekturen: In der Praxis ergibt sich zusätzlich die zeitliche Herausforderung, dass die Fristen für die Erstellung von Reports oder einer Meldung so knapp bemessen sind, dass ggf. nicht ausreichend Zeit bleibt, Datenqualitätsmängel innerhalb dieser Fristen an der Quelle nachhaltig zu bereinigen und die gesamte Verarbeitung mit den verbesserten Daten vollständig neu zu durchlaufen. An dieser Stelle ist zu diskutieren, wo in der Architektur, zu welchem Zeitpunkt und durch wen ein Eingriff in die Daten in Form einer (manuellen) Korrektur zulässig ist.
Neben diesen Fragen erhöht sich die Komplexität bei der Konzeption von Korrekturprozessen dadurch, dass jede Korrektur zu Inkonsistenzen zwischen der Einheit führt, die mit den korrigierten Daten weiterarbeitet und allen anderen Einheiten, die auf den unkorrigierten Rohdaten arbeitet oder bereits gearbeitet haben. Es gilt daher zu analysieren, wer über durchgeführte Korrekturen informiert werden muss, um diese Veränderung ggf. ebenfalls umsetzen zu können, und wer evtl. bereits mit den unkorrigierten Daten Reports erzeugt oder Meldungen erstellt hat, um mögliche Inkonsistenzen erklären zu können. Rein technisch stellt sich zusätzlich die Frage, wie auf Ebene des dispositiven Datenhalts umgegangen werden soll und ob nachgelagerte Korrekturen dort nachzuziehen sind. Dies kann sogar Daten und Zeitscheiben der Vergangenheit betreffen, sofern der korrigierte Fehler bereits länger besteht.
In jedem Fall ist jede Form der Korrektur revisionssicher durchzuführen was die Dokumentation und Freigabe der Änderungen angeht. Zusätzlich sollte immer eine nachhaltige Bereinigung der Ursprungsdaten initiiert werden, um die Korrektur nicht mehrfach durchführen zu müssen.
BCBS 239 breiter denken
Neben den hier angesprochenen Beispielen gibt es bei der sukzessiven Umsetzung einer BCBS 239 Zielarchitektur eine große Anzahl zu konzipierender Aspekte, die sowohl fachliche als auch technische Auswirkungen haben. Deswegen ist es für Banken von entscheidender Bedeutung, das notwendige fachliche und technische Know-How in den Umsetzungsprojekten sinnvoll zu kombinieren. Nur so ist es möglich, Lösungen zu entwickeln, die auf der einen Seite BCBS 239 erfüllen, die aber auf der anderen Seite auch zukunftssicher, flexibel weiterzuentwickeln und kosteneffizient sind.aj
Sie finden diesen Artikel im Internet auf der Website: https://itfm.link/35011



Schreiben Sie einen Kommentar