IDV – Intelligente Dokumentenverarbeitung: Einstieg in die Hyperautomatisierung
Dr. Dennis Imer, Global Head of Advanced Analytics & Data Management bei Synpulse Management ConsultingSynpulse
Banken und Versicherungen verfolgen seit einigen Jahren mehr oder weniger zielstrebig die Digitalisierung und Automatisierung ihrer Wertschöpfungskette. In vielen Fällen wurden Initiativen und Projekte allerdings vorrangig auf die kundenseitigen Schnittstellen und Prozesse angewendet (E-Banking, Schadensfallmeldung). In den letzten zwei bis drei Jahren jedoch haben insbesondere Banken, aber auch Versicherer in einem ersten Schritt angefangen, immer mehr ihrer repetitiven Kerngeschäftsprozesse auf der nicht kundenbezogenen Seite ihrer Wertschöpfungskette zu automatisieren.
von Dr. Dennis Imer und Frederike Sturm, Synpulse
Die Grenze der einfachen und schnellen Automatisierung repetitiver Kerngeschäftsprozesse, z.B. durch Robotic Process Automation (RPA), ist häufig dann erreicht, wenn für eine vollständige Automatisierung des Prozesses Komponenten künstlicher Intelligenz (KI) vonnöten sind. Dies ist häufig dann der Fall, wenn unstrukturierte Daten als Input für eine automatisierte Weiterverarbeitung vorliegen. Hier trägt intelligente Dokumentenverarbeitung (IDV) als wichtiges Element der hyperautomatisierten Wertschöpfungskette dazu bei, das Anwendungsspektrum für die Automatisierung zu erweitern.
Frederike Sturm, Associate Partner bei Synpulse Management Consulting Synpulse
Was ist intelligente Dokumentenverarbeitung und wie hilft sie?
Intelligente Dokumentenverarbeitung befähigt Banken und Versicherer, ihre Formulare, Briefe, E-Mails, Verträge und andere schriftliche Korrespondenz kontrolliert und automatisiert zu verarbeiten und somit den manuellen Aufwand in den betroffenen Bereichen zu minimieren.
IDV-Lösungen erkennen definierte und antrainierte Dokumenten- und Formularkategorien und extrahieren relevante Informationen aus diesen unstrukturierten und strukturierten Formaten, um sie für die weitere Verarbeitung im gewünschten Format bereitzustellen.“
Wie arbeitet eine IDV-Lösung?
IDV-Lösungen erledigen ihre Arbeit im Wesentlichen durch vier ansonsten aufwändige Arbeitsschritte.
Schrifterkennung: Im ersten Schritt werden gescannte PDF-Dokumente und Formulare maschinenlesbar gemacht – also in Textdateien umgewandelt, um sie in den darauffolgenden Schritten weiterverarbeiten zu können. Dieser Schritt nennt sich Optical Character Recognition (OCR) und funktioniert – wie der Name suggeriert – über die optische Analyse und Erkennung der Schriftzeichen.
Kategorisierung: Im nächsten Schritt werden die Inhalte der erstellten Textdateien geladen, um diese zu kategorisieren. Je nach IDV-Lösung werden die Dokumente von einer KI „gelesen“ oder via optischer Merkmale kategorisiert. Eine Kombination aus beiden Ansätzen kann das Ergebnis nochmals verbessern.
Datenextraktion: Im dritten Schritt werden die für die Weiterverarbeitung relevanten Informationen aus den kategorisierten Dokumenten extrahiert. Hierfür kommen ebenfalls entweder KI, strukturelle oder eine Kombination beider Komponenten zum Einsatz.
Weiterverarbeitung: Im letzten Schritt werden die extrahierten Informationen für die Weiterverarbeitung in einer Datenbank oder auf einem Netzlaufwerk gespeichert oder direkt über Schnittstellen an ein anderes System (bspw. das Bestandssystem einer Versicherung) übergeben.
Sollten während der intelligenten Dokumentenverarbeitung Fehler auftauchen, muss sichergestellt sein, dass sich diese nicht durch den kompletten Prozess ziehen und am Ende fehlerhafte Daten in ein Zielsystem übertragen werden.
Um dies zu verhindern, sind IDV-Lösungen mit Mechanismen ausgestattet, um Fehler zu erkennen und auszusteuern. Die ausgesteuerten Fälle werden von Menschen überprüft, die Daten ergänzt oder korrigiert und mit wenigen Klicks zurück in die automatisierte Weiterverarbeitung geschickt.“
Aussteuerungsgründe können beispielsweise ein unsicheres Ergebnis in der Schrifterkennung aufgrund schlechter Scanqualität sein, eine Unsicherheit der KI bei der Zuteilung eines Dokuments zu einer bestimmten Kategorie oder eine Unsicherheit über die Zugehörigkeit eines extrahierten Wertes zu einer bestimmten Informationsart (z.B. Versicherungsnummer).
Nachfolgend eine Auflistung verschiedener Anwendungsfälle, bei denen IDV-Lösungen für eine end-to-end Automatisierung sorgen:
Posteingangssortierung und Datenextraktion für die manuelle Weiterverarbeitung
Extraktion von Ausweisdaten
Auslesen von Formularen (z.B. SEPA Lastschriftmandat, Adressänderung)
Auslesen von Rechnungen
Datenextraktion aus Versicherungsverträgen
Auslesen von Inhalten aus Freitext-E-Mails
Datenextraktion aus Pfändungs- und Überweisungsbeschlüssen
Abbildung 1: Die drei Arbeitsschritte einer IDV-Lösung. Synpulse.
Die Vorteile von Intelligenter Dokumentenverarbeitung
Der Einsatz einer IDV-Lösung hat mehrere direkte und indirekte Vorteile.
Verkürzte Bearbeitungsdauer
Durch IDV können Banken und Versicherer den Einstieg ihrer teils aufwändigen und manuellen Prozesse – wie beispielsweise Posteingangsverarbeitung – automatisieren. So können fortlaufend eintreffende Dokumente, Formulare und Kundenanfragen auf postalischem oder digitalem Weg in Echtzeit entgegengenommen und zur Weiterverarbeitung aufbereitet werden. In einem weiteren Ausbauschritt lassen sich IDV-Lösungen sehr gut mit RPA verbinden.
So müssen Mitarbeitende nur noch in Einzelfällen einschreiten und Ergebnisse verifizieren oder abfangen. Dies wiederum führt dazu, dass die Prozesse schneller und zeitgleich auch weniger fehleranfällig werden.“
Als Nebeneffekt werden interne Kapazitäten frei, die anderweitig gewinnbringend eingesetzt werden können, beispielsweise zur Abarbeitung komplexerer Anwendungsfälle.
Insbesondere während Stoßzeiten ist die IDV-Lösung klar im Vorteil, da sie rund um die Uhr im Betrieb ist. Für den Fall der dauerhaften Erhöhung des zu bearbeitenden Volumens (neue Anwendungsfälle, Wachstum, o.ä.) ist die Skalierung der implementierten Lösung möglich. Dies führt wiederum dazu, dass Mitarbeitende entlastet werden und weniger manuelle Bearbeitungsfehler auftreten.
Künstliche Intelligenz schafft Vorsprung
Je nach Anwendungsfall lassen sich mit dem Einsatz von künstlicher Intelligenz bei der Kategorisierung und Extraktion bessere Ergebnisse erzielen als durch den Einsatz von strukturellen oder regelbasierten Lösungen. So kann eine regelbasierte Lösung bei der Identifikation des Wortes Nachlass das Dokument als Sonderkonditionsdokument kategorisieren, da das Tool einen Rabatt assoziiert. Die KI jedoch kann durch Training identifizieren, dass es sich um die Bearbeitung eines Erbfalls handelt. Die KI erlernt die Kategorisierung und Extraktion von relevanten Daten auf der Basis hauseigener Dokumente und Formulare und ist so ideal auf die individuellen Anforderungen abgestimmt. Dies führt dazu, dass verlässlichere Ergebnisse erzielt werden, welche auch bei Hinzunahme von neuen Formularen oder Dokumententypen durch Anpassung der Trainingsmenge Bestand haben. Somit entfallen aufwändige Anpassungen von Regelwerken und die Dokumentation dieser.
Niedrige Umsetzungshürde
Die Umsetzung von IDV-Lösungen ist in der Regel ein relativ schnelles und kostengünstiges Unterfangen. Die typischen Anwendungsfälle können unter sämtlichen infrastrukturellen Voraussetzungen innerhalb weniger Monate umgesetzt werden. In Verbindung mit den typischen Projekt-, Lizenz- und Betriebskosten kommen sehr schnell rentable Business Cases zustande.
Abbildung 2: Die Vorteile einer IDV-Lösung. Synpulse.
Projektbeispiel: Postrückläufer
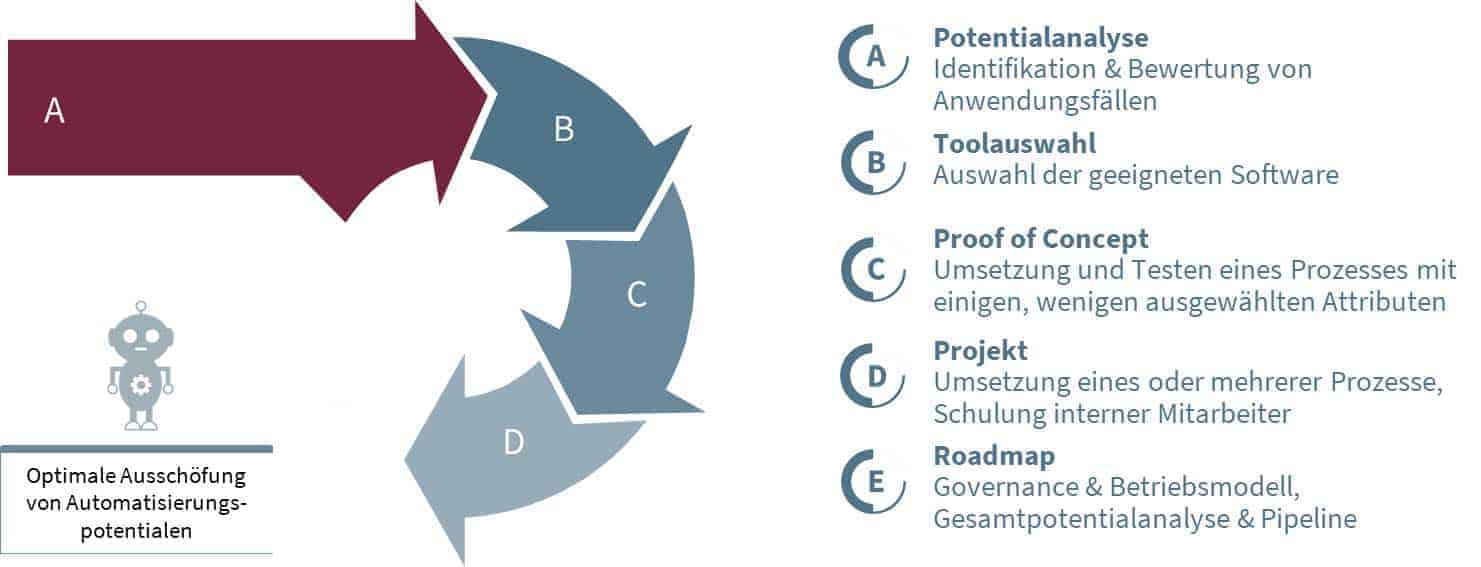
Abbildung 3: Der Synpulse Projektansatz für IDV-Lösungen. Synpulse.
Im Folgenden zeigen wir anhand eines Projektbeispiels auf, wie eine IDV-Tool Einführung funktioniert.
Ausgangssituation:
Bei einer deutschen Retail Bank galt es, Postretouren, also zurückgesendete Bankformulare sowie Standardbriefe, zunächst über einen hausinternen Scanvorgang zu digitalisieren und im Anschluss relevante Informationen für die Weiterverarbeitung aus den Dokumenten zu extrahieren. Da die Weiterverarbeitung automatisiert mithilfe von Robotic Process Automation erfolgt und pro Dokumentenart unterschiedliche Daten für die Weiterverarbeitung extrahiert werden mussten, wurden die Dokumente zunächst in verschiedene Kategorien unterteilt (für eine Übersicht der einzelnen Kategorien siehe Tabelle 1). Das IDV-Tool sollte hierbei möglichst nahtlos in den bestehenden Prozess, vom Scanning bis hin zur Dokumentenarchivierung, integriert werden.
Autor Dr. Dennis Imer, Synpulse
Dr. Dennis Imer ist bei Synpulse Global Head (Webseite) of Advanced Analytics & Data Management. In dieser Rolle entwickelt er Themen rund um die Intelligente Dokumentenverarbeitung sowie Data Management Strategien und betreut Projekte in diesen Bereichen. Zuvor prägte Dr. Imer bei der Schweizer Privatbank Bank J. Safra Sarasin als Group Data Governance Manager und Group Data Protection Officer die dortige Datenverarbeitung nachhaltig. Während seines Doktorats in Biogeochemie an der ETH Zürich beschäftigte sich Imer mit der Modellierung von Treibhausemissionen.
Phase A und B: Potenzialanalyse und Toolauswahl
IDV-Lösungen können bei nahezu allen Prozessen, in denen schriftliche Korrespondenz kategorisiert und/oder Inhalte aus Dokumenten extrahiert werden müssen, eingesetzt werden. Vor der Entscheidung für eine IDV-Lösung sollte jedoch im ersten Schritt immer eine Potenzialanalyse durchgeführt werden.“
Hier werden mehrere Anwendungsfälle betrachtet und auf die Relevanz für eine Automatisierung untersucht. Das Prozessvolumen und die eingesparte manuelle Bearbeitungszeit sind wichtige Faktoren für eine Entscheidung. Anhand der Anwendungsfälle wird ebenfalls bewertet, mit welcher IDV-Lösung das größte Spektrum an vorhandenen Dokumententypen umgesetzt werden kann. Um ein möglichst umfassendes Bild zu erlangen, werden unter anderem die folgenden Fragen geklärt:
Welche Prozesse sollen mit einer IDV-Lösung automatisiert werden?
Welche Dokumententypen sind zu bearbeiten (Post, E-Mails, Verträge, Formulare, Rechnungen, Ausweise)?
Wie hoch sind zu bearbeitende Volumen pro Prozess (generell gilt: je höher das Volumen, desto schneller lohnt sich der Einsatz einer IDV-Lösung)?
In welchem Zeitrahmen müssen die Dokumente prozessiert werden?
Über die Beantwortung dieser Fragen lässt sich generell schnell ermitteln, ob sich eine IDV-Lösung rechnet und falls ja, welche konkrete IDV-Lösung zum Einsatz kommen soll. Während ein Tool beispielsweise Stärken bei der Kategorisierung von Formularen und Ausweisen hat, ist ein anderes Tool besser für Freitextdokumente geeignet.
Da die zu erwartende Menge an Postretouren einen signifikanten Anteil an semi- und unstrukturierten Dokumenten enthält, wurde als IDV-Lösung die AI Plattform der Firma ITyX ausgewählt. Hier sind durch den Einsatz von KI bessere Ergebnisse im Bereich der Kategorisierung und der Datenextraktion zu erzielen als mit einer Lösung, die struktur- oder regelbasiert arbeitet. Darüber hinaus ist eine KI-Lösung bei der Hinzunahme weiterer Anwendungsfälle generell flexibler, weil Trainingsmengen schnell angepasst werden können.
Autor Frederike Sturm, Synpulse
Frederike Sturm ist Associate Partner von Synpulse (Webseite). Die gelernte Bankkauffrau berät mit ihrem Team bei Synpulse Deutschland Finanzdienstleister und Versicherungen bei der Einführung von Robotic Process Automation (RPA) und dessen Ausbaustufe Intelligent Automation – von der Auswahl geeigneter Tools, über Schulungen bis hin zur Implementierung automatisierter Prozesse. Darüber hinaus betreut Frau Sturm die Technologiepartner von Synpulse in diesem Themenbereich.
Phase C: Proof of Concept:
Im Proof of Concept wurde der Prozess erfolgreich (gute Erkennungs- und Extraktionsquote) automatisiert. Hierzu wurde in der IDV-Lösung zunächst ein Workflow aufgesetzt. Dieser Workflow stellt sicher, dass die gescannten Dokumente aus einem Inputordner zur Schrifterkennung geschickt, dann kategorisiert, im Anschluss die relevanten Daten extrahiert und am Ende die eingelesenen PDF- und XML-Dateien mit den extrahierten Daten in die gewünschten Outputordner geschrieben werden. Von dort aus werden die Daten dann von Robotern für die Weiterverarbeitung abgeholt.
Für das Training der Kategorisierungs- und Extraktionsmodelle wurden jeweils zwischen 100 und 200 Dokumente verwendet. Bei der Extraktionsautomatisierung wurde eine Kombination aus Modellen und regulären Ausdrücken (RegEx) – also eine Kombination aus KI und bestehenden Regelwerken – verwendet, um die Extraktionsquote aus den antrainierten Dokumenten mithilfe von Regeln noch zusätzlich anzuheben.
Phase D: Projekt
Nach dem Proof of Concept erfolgt die Umsetzung weiterer Prozesse. Parallel hierzu werden in der Regel interne Mitarbeitende in der Anwendung des Tools geschult. So kann ein möglichst umfassender Wissenstransfer stattfinden.
Einfache Anwendungsfälle können so häufig selbstständig durch interne Mitarbeitende umgesetzt werden. Über die Projektlaufzeit werden Anwender somit befähigt, immer mehr Tätigkeiten innerhalb der IDV-Lösung selbst zu übernehmen.“
Ein weiteres wichtiges Projektziel ist die Einbettung der IDV-Lösung in ein entsprechendes Betriebsmodell, um den Anforderungen externer Prüfer und interner Revision an Dokumentation, IT-Sicherheit und klarer Aufbau- und Ablauforganisation gerecht zu werden.
Kategorie
Extrahierte Daten
Anzahl Trainingsdokumente
STP Rate
Möglich: Dokumente / h
Tatsächlich: Dokumente / Woche
Bankkarten
Datum
Adresse
Kontonummer (aus IBAN)
Kartennummer
Kategorisierung:
200
Extraktion:
100
90%
15
100
Online Banking
Datum
Adresse
Online Banking Key
Kategorisierung:
200
Extraktion:
100
95%
20
100
Kredite
Datum
Adresse
Kontonummer
Kundennummer
Kategorisierung:
200
Extraktion:
200
90%
15
60
Wertpapiere
Datum
Adresse
Kontonummer
Kategorisierung:
200
Extraktion:
100
95%
20
100
Restliche Dokumente
Datum
Adresse
Kundennummer
Kontonummer
(Kredit-)Kartennummer
Online Banking Key
Name
Über alle Kategorien hinweg konnten gute bis sehr gut Dunkelverarbeitungsraten (STP: Straight Through Processing) erzielt werden. Während im komplexesten Fall eine Rate von 80% erreicht wurde, konnten in den weniger komplexen Fällen bis zu 95% erreicht werden.
Bei dem aktuellen Aufkommen an zu verarbeitenden Dokumenten pro Woche (circa 400 / Woche) hat die Bank sogar noch Skalierungsmöglichkeiten, da je nach Kategorie zwischen 12 und 20 Dokumente pro Stunde verarbeitet werden können.
Es zeigt sich, dass IDV-Lösungen ein wichtiger Schritt hin zur Digitalisierung und Automatisierung der kunden- und nicht kundenbezogenen Seite der Wertschöpfungskette sind, da sie Effizienzsteigerungen bei geringem Umsetzungsaufwand bieten.“
Dr. Dennis Imer und Frederike Sturm, Synpulse
Sie finden diesen Artikel im Internet auf der Website: https://itfm.link/117453




 Dr. Dennis Imer ist bei Synpulse Global Head (Webseite) of Advanced Analytics & Data Management. In dieser Rolle entwickelt er Themen rund um die Intelligente Dokumentenverarbeitung sowie Data Management Strategien und betreut Projekte in diesen Bereichen. Zuvor prägte Dr. Imer bei der Schweizer Privatbank Bank J. Safra Sarasin als Group Data Governance Manager und Group Data Protection Officer die dortige Datenverarbeitung nachhaltig. Während seines Doktorats in Biogeochemie an der ETH Zürich beschäftigte sich Imer mit der Modellierung von Treibhausemissionen.
Dr. Dennis Imer ist bei Synpulse Global Head (Webseite) of Advanced Analytics & Data Management. In dieser Rolle entwickelt er Themen rund um die Intelligente Dokumentenverarbeitung sowie Data Management Strategien und betreut Projekte in diesen Bereichen. Zuvor prägte Dr. Imer bei der Schweizer Privatbank Bank J. Safra Sarasin als Group Data Governance Manager und Group Data Protection Officer die dortige Datenverarbeitung nachhaltig. Während seines Doktorats in Biogeochemie an der ETH Zürich beschäftigte sich Imer mit der Modellierung von Treibhausemissionen.  Frederike Sturm ist Associate Partner von Synpulse (Webseite). Die gelernte Bankkauffrau berät mit ihrem Team bei Synpulse Deutschland Finanzdienstleister und Versicherungen bei der Einführung von Robotic Process Automation (RPA) und dessen Ausbaustufe Intelligent Automation – von der Auswahl geeigneter Tools, über Schulungen bis hin zur Implementierung automatisierter Prozesse. Darüber hinaus betreut Frau Sturm die Technologiepartner von Synpulse in diesem Themenbereich.
Frederike Sturm ist Associate Partner von Synpulse (Webseite). Die gelernte Bankkauffrau berät mit ihrem Team bei Synpulse Deutschland Finanzdienstleister und Versicherungen bei der Einführung von Robotic Process Automation (RPA) und dessen Ausbaustufe Intelligent Automation – von der Auswahl geeigneter Tools, über Schulungen bis hin zur Implementierung automatisierter Prozesse. Darüber hinaus betreut Frau Sturm die Technologiepartner von Synpulse in diesem Themenbereich. 

Schreiben Sie einen Kommentar