Monitoring: IT-bedingte Ausfälle vermeiden, zumindest deutlich reduzieren und schneller lösen

Datadog
Im Hinblick auf die zunehmende Verlagerung von Finanzdiensten in die Cloud ist es für Banken und Finanzinstitute essentiell, ein gutes Monitoring zu haben, dass auch über diverse (Cloud-)Systeme hinweg funktioniert. Es garantiert, dass Probleme und Risiken rechtzeitig identifiziert werden und Online-Dienste jederzeit reibungslos funktionieren. Das Ziel: „Nie wieder offline dank klugem Monitoring“.
von Stefan Marx, Director Product Management EMEA Datadog
Mehr Sicherheit, geringere Ausfallzeiten, einen höheren Bedienkomfort sowie Governance und Kontrollmöglichkeiten – diese Vorteile versprechen sich Unternehmen durch die Verlagerung unternehmenseigener IT-Komponenten in die Cloud. Ohne die passenden Maßnahmen und Instrumente bleiben diese Ziele allerdings Wunschdenken. Insbesondere in heterogenen, hybriden oder in Infrastructure-as-Code-(IaC) Umgebungen entstehen schnell blinde Flecken.
Finanzinstitute sollten – egal ob Bank oder FinTech – bei dem Umzug in die Cloud ein Monitoring etablieren, das auch in komplexen Umgebungen zuverlässige Einblicke in die Performance und Produktivität ihrer Anwendungen bietet.“
So bleiben groß angelegte Migrationsprojekte nicht hinter den Erwartungen zurück.
IaC für die Orchestrierung von Cloud-Umgebungen
Da Organisationen immer öfter mehr als nur einen Service von mehr als nur einem Public- oder Private-Cloud-Anbieter nutzen, entstehen verteilte Anwendungslandschaften, die in einer Vielzahl von Stacks und auf Hunderten von Maschinen laufen. Der Einsatz von Open-Source-basierten IaC-Umgebungen hilft dabei, die heterogenen Systeme und Anwendungen optimal zusammenarbeiten zu lassen. Die IaC-Umgebungen sorgen neben einer größeren Systemzuverlässigkeit und Sicherheit für agilere Prozesse bei der Entwicklung neuer Infrastrukturen, Produkte und Services.
Datadog
Die Lösung liegt dabei in der hohen Anpassungsfähigkeit von Code-gemanagten Umgebungen: Frameworks, die nach dem IaC-Prinzip arbeiten, rollen automatisiert Skripts oder Definitionsdateien zur Konfiguration einzelner Module und Maschinen aus. Dies erspart Entwicklern und Administratoren zeitraubende, manuelle Systemeinstellungen. Die programmierten Bereitstellungsprozesse spiegeln komplexe Abläufe wider und sind systemadaptiv. Für Multi-Clouds eignen sich IaC insbesondere deshalb, weil sich die Tools und Prozesse dieses Prinzips unabhängig von der Zusammensetzung eines Cloud-Stacks oder von Services unterschiedlicher Cloud-Anbieter an die Umgebung anpassen. Sie sind skalierbar, das heißt sie wachsen kontinuierlich mit der Infrastruktur und ihren einzelnen Modulen und schaffen damit große Flexibilität bei der Gestaltung der jeweiligen Cloud-Umgebungen. Wenig überraschend setzen inzwischen bereits einige Finanzunternehmen auf Open-Source-Werkzeuge wie Terraform, Puppet oder Ansible, um ihre komplizierten Cloud-Umgebungen zu orchestrieren. Das IaC-basierte Management von Multi-Cloud-Umgebungen und unterschiedlichen Services kann allerdings nur halten, was sich Finanzorganisationen versprechen, wenn IT-Verantwortliche ein übergreifendes Monitoring nutzen, um Zugriff auf erfolgsrelevante Kennzahlen zu bekommen.
 Stefan Marx ist Director Product Management für die EMEA-Region beim Cloud-Monitoring-Anbieter Datadog (Website). Marx ist seit über 20 Jahren in der IT-Entwicklung und -Beratung tätig. In den vergangenen Jahren arbeitete er mit verschiedenen Architekturen und Techniken wie Java Enterprise Systemen und spezialisierten Webanwendungen. Seine Tätigkeitsschwerpunkte liegen in der Planung, dem Aufbau und dem Betrieb der Anwendungen mit Blick auf die Anforderungen und Problemstellungen hinter den konkreten IT-Projekten.
Stefan Marx ist Director Product Management für die EMEA-Region beim Cloud-Monitoring-Anbieter Datadog (Website). Marx ist seit über 20 Jahren in der IT-Entwicklung und -Beratung tätig. In den vergangenen Jahren arbeitete er mit verschiedenen Architekturen und Techniken wie Java Enterprise Systemen und spezialisierten Webanwendungen. Seine Tätigkeitsschwerpunkte liegen in der Planung, dem Aufbau und dem Betrieb der Anwendungen mit Blick auf die Anforderungen und Problemstellungen hinter den konkreten IT-Projekten.Erfolg hybrider Clouds hängt von Monitoring ab
Open Source-Tools helfen dabei, das Management komplexer Cloud-Gefüge vor allem im Hinblick auf Systemtransparenz, Nachvollziehbarkeit und Skalierbarkeit zu vereinfachen.“
Open Source-Tools helfen dabei, das Management komplexer Cloud-Gefüge vor allem im Hinblick auf Systemtransparenz, Nachvollziehbarkeit und Skalierbarkeit zu vereinfachen.“
Da sie plattformunabhängig funktionieren, sind die Interoperabilität der gesamten Cloud-Umgebung und die Portierbarkeit von Daten und Anwendungen gewährleistet. Sie helfen außerdem dabei, IT-Infrastrukturen auf Basis maschinenlesbarer Sprachen zu orchestrieren. IaC-Umgebungen werden deshalb auch als programmierbare Infrastrukturen bezeichnet. Eben weil sie über alle Plattformen hinweg kommunizieren und arbeiten können, ist es wichtig, schnell einen Überblick über heterogene, IaC-basierte Cloud-Umgebungen bekommen zu können. Denn sonst riskieren IT-Verantwortliche, die fehlerhafte Workflows oder akute Auslastungsprobleme nicht erkennen, im schlimmsten Fall ganze Systemausfälle. Dies würde wiederum dazu führen, dass das IT-Team von seiner eigentlichen Arbeit abgehalten und damit Ressourcen gebunden werden, die ursprünglich zum Beispiel in die Entwicklung neuer Services fließen sollten.
Hier kann die Kombination eines intelligenten Monitorings mit Infrastructure-as-Code-Lösungen viel dazu beitragen, unwirtschaftliche Performance-Hürden auszuschließen.
Standard-Lösungen decken nicht alles ab
Eine Monitoring-Lösung für heterogene und hybride Umgebungen, die alles abdecken soll, muss ebenso komplex, dynamisch und plattformunabhängig arbeiten wie das IaC-basierte Management der Cloud-Umgebung selbst. Sie muss breit aufgestellt sein und zahlreiche Cloud-Module integriert haben. Alternativ muss die Möglichkeit bestehen, die erforderlichen APIs bei Bedarf selbst bauen zu können. Die Auslastung aller Elemente – Apps und Anwendungen, unterschiedliche Cloud-Provider, Internet-of-Things-Umgebungen, wechselnde Container-Technologien, verschiedenste Endgeräte und Hardware – muss zu jeder Zeit erfasst und interpretiert werden können. Geschieht dies nicht, riskieren IT-Verantwortliche, Prozessfehler, Schnittstellenprobleme oder die Einbindung falscher Komponenten nicht schnell genug zu erkennen.
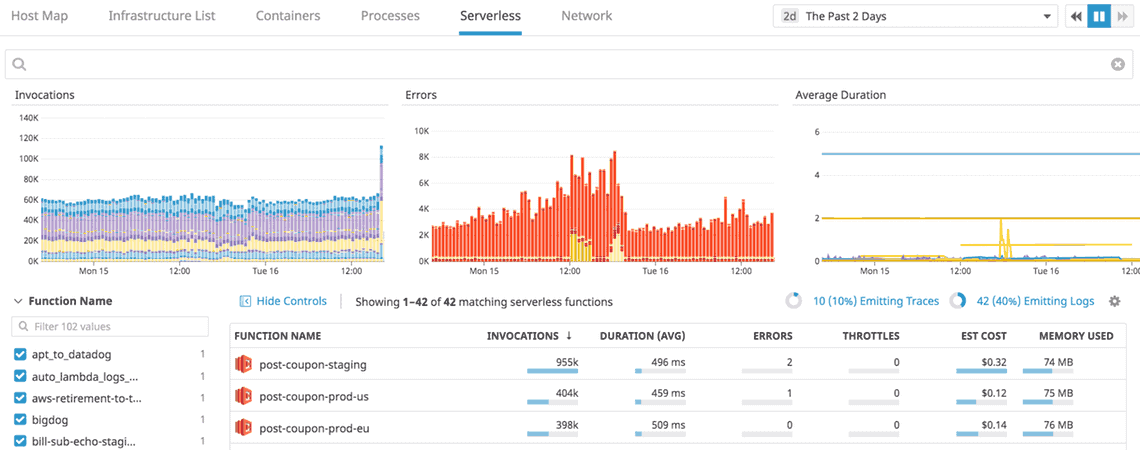
Alle Work und Resource Metrics im Blick
Ein kluges Monitoring sollte beides können: sowohl ad hoc Probleme erkennen als auch stichhaltige Vorhersagen treffen.“
Ein kluges Monitoring sollte beides können: sowohl ad hoc Probleme erkennen als auch stichhaltige Vorhersagen treffen.“
Um diese breite Funktionsspanne abzudecken, ist die systematische Erfassung einer Reihe von Kennzahlen gefragt, die sich grob in operative Kennzahlen, den „Work Metrics“, und Ressourcenkennzahlen, den sogenannten „Resource Metrics“, unterteilen lassen. Ein erfolgreiches Monitoringkonzept sollte allen am Prozess beteiligten Mitarbeitern jederzeit den Zugriff auf all diese Metriken ermöglichen.
Work Metrics können in vier weitere Unterkategorien ausdifferenziert werden: Sie erfassen den Durchsatz („throughput“), den ein System über eine festgelegte Zeitspanne hinweg ausweist; sie zeigen den prozentualen Anteil der erfolgreichen Operationen („success“) an; sie ermitteln die Anzahl fehlerhafter Operationen („error“) und sie quantifizieren die Performance („performance“) der einzelnen Komponenten, beispielsweise durch die Ermittlung der Latenz- und Antwortzeiten.
Die Ressourcenkennzahlen betrachten wiederum die unterschiedlichen Bestandteile der Systeminfrastruktur und ihre Nutzung, („utilization“), Sättigung („saturation“), Verfügbarkeit („Availability“) sowie Fehler („Errors“).
Datadog
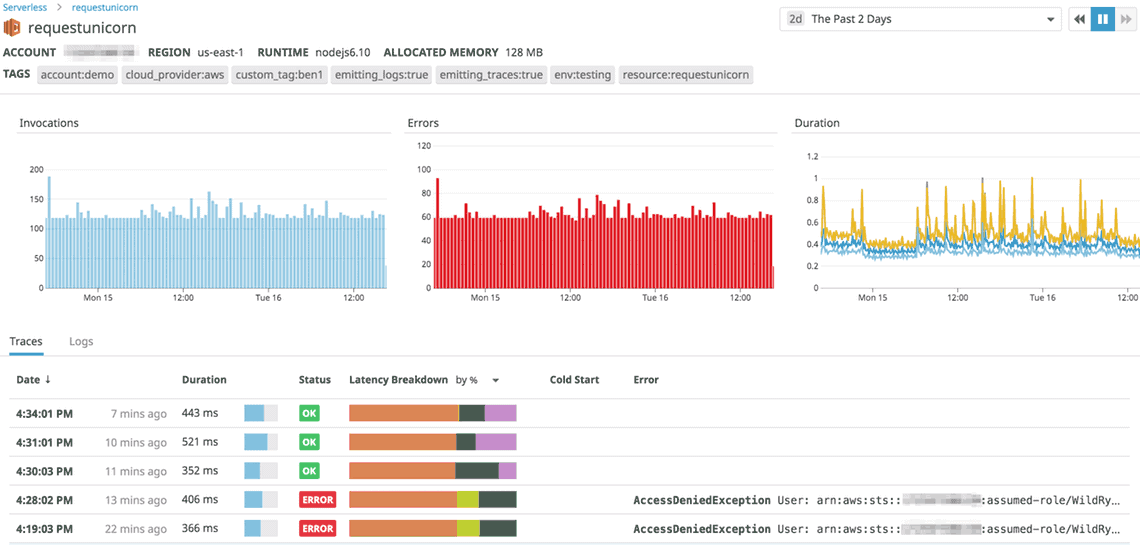
Unabhängig von den Kennzahlkategorien sollten Cloud-Nutzer darauf achten, mit der passenden Granularität zu arbeiten: Durchschnittswerte über lange Messzeiträume mindern die Aussagekraft von Monitoring-Maßnahmen ebenso wie zu selten oder unregelmäßig erhobene Kennzahlen. Ebenso wichtig ist es, dass erfasste Rohdaten möglichst lange vorgehalten unverändert werden. Um monatliche, saisonale oder jährliche Abweichungen klar herausarbeiten zu können, sollten Finanzorganisationen die Daten mindestens ein Jahr lang speichern. Intelligente, selbstlernende Monitoring-Lösungen entwickeln diese Kennzahlen unter Einbindung von Machine-Learning-Technologien regelmäßig weiter, was die Genauigkeit der Kennzahlenauswertung weiter erhöht.
Reporting als Basis für strategische Entscheidungen
IT-Teams sollten außerdem Wert auf ein gutes Reporting legen, damit sie nicht wertvolle Zeit mit manuellen Datenbank-Suchen, aufwändigen Analysen oder gar der Formatierung von Excel-Sheets verbringen. Damit dies nicht geschieht, braucht es kluge Visualisierungs-Funktionen. Ein gutes Monitoring ist erst dann wirklich hilfreich, wenn bedeutsame Erkenntnisse ohne Umschweife und auf einen Blick erkannt werden. Wird das Monitoring-Tool der Komplexität seines Wirkungsbereichs gerecht und bereitet die Erkenntnisse in gut sichtbaren Daten auf, können IT-Entscheider schnell und zielgerichtet sowohl operative als auch strategische Weichen stellen. Alarme und Statusindikatoren müssen auf Basis von Schwellwerten aber auch unter Berücksichtigung des erwarteten Verlaufs automatisch erstellt werden. Automatische und Intelligente Algorithmen machen die Messwerte dabei auch in komplexen modernen Umgebungen beherrschbar und stellen sicher, dass abnormales Verhalten sicher erkannt wird.
Der Schlüssel für erfolgreiche Cloud-Konzepte wird künftig mehr denn je darin liegen, den Überblick zu behalten.
Mit den Möglichkeiten der dezentralen Vorhaltung und Virtualisierung von IT-Ressourcen steigt jedoch auch die Komplexität der Infrastrukturen.“
Deshalb werden sich die Erwartungen der Finanzunternehmen an das Potenzial von vielschichtigen Multi-Cloud und IaC-Umgebungen nur dann erfüllen, wenn sie sämtliche Komponenten zu jeder Zeit im Blick haben.Stefan Marx, Datadog
Sie finden diesen Artikel im Internet auf der Website:
https://itfm.link/95942


Schreiben Sie einen Kommentar