
Sprachauthentifizierung: Jede Stimme zahlt

Triplesense Reply
„Kann ich mich mit einer Sprachschnittstelle authentifizieren?“ – die Frage stellt sich nicht nur in Banking-Szenarien, sondern schon bald bei allen Transaktionen. Denn mit wachsender Akzeptanz und Nutzung von Sprachschnittstellen steigt der Bedarf nach sicherer Sprachauthentifizierung – insbesondere im Finanz- und Banking-Sektor.
von Dan Fitzpatrick und Maria Müller, Triplesense Reply
Der Wert eines Fahrrads lässt sich schätzen, indem das Schloss überprüft wird, mit dem es am Zaun gesichert ist. Handelt es sich um ein teures, massives Schloss, ist das Fahrrad entsprechend wertvoll. Ein robustes Schloss hat auch Nachteile: In der Regel ist es schwer, unhandlich in der Bedienung und teuer in der Anschaffung.
In der Finanzwelt heißt das Pendant zur Schloss-Analogie Risikomanagement und meint die systematische Erfassung und Bewertung von Risiken für den Geschäftsbetrieb eines Unternehmens.“
Für Verbraucher stellt Risikomanagement vor allem ein Transaktionshindernis dar. Kurzum: Kauft ein Nutzer bargeldlos ein, muss er sich durch eine PIN-Eingabe oder Unterschrift legitimieren. Diese Sicherheitsmaßnahmen kosten Zeit und Nerven. Daher sind Technologien und Prozesse, die sowohl gute Bequemlichkeit als auch hohe Sicherheit anbieten, attraktiv für den Alltag. Zahlungs- und Authentifizierungssysteme, die sich ausschließlich mit der Stimme des Nutzers bedienen lassen, erfüllen beide Kriterien: die Bedienung ist hands-free und das Mittel der Authentifizierung hat man immer dabei.
Voiceprint als Authentifizierungsmerkmal
Autor Maria Müller, Triplesense Reply Als Voice UX-Spezialistin bei Triplesense Reply (Webseite) konzipiert Maria Müller Anwendungen für Sprachassistenten wie Amazon Alexa oder Google Assistant.
Als Voice UX-Spezialistin bei Triplesense Reply (Webseite) konzipiert Maria Müller Anwendungen für Sprachassistenten wie Amazon Alexa oder Google Assistant.
Als Voice UX-Spezialistin bei Triplesense Reply (Webseite) konzipiert Maria Müller Anwendungen für Sprachassistenten wie Amazon Alexa oder Google Assistant. Biometrische Authentifizierung mit der Stimme findet in einem noch relativ eingeschränkten Umfeld statt – meist für die Vorverifikation und -identifizierung von Bankkunden im Teleservice-Bereich. Dabei ist ein Stimmabdruck, Voiceprint, ein robustes Authentifizierungsmerkmal. Im Gegensatz zu einer Unterschrift, einem Passfoto, einem Daumenabdruck oder einem Iris-Scan – alles rein visuelle, statische Identifikationsmerkmale – wird ein Voiceprint über einen Zeitraum von mehreren Sekunden – gegebenenfalls mehrfach – verglichen. Bis zu 150 Charakteristika lassen sich dabei dynamisch vermessen, um eine Übereinstimmung zu finden.
Multi-Faktor-Authentifizierung für sichere Anmeldeverfahren
Derzeit stellen die Anforderungen des Risikomanagements an eine Multi-Faktor-Authentifizierung bei größeren Transaktionen eine Hürde für das Etablieren von Sprachauthentifizierung dar. Die Stimmprofilanalyse bietet heutzutage nur einen Faktor zur Legitimation, wobei meist – je nach Transaktionswert – mehrere Faktoren notwendig sind. So kann eine Bankkarte ohne weitere Maßnahmen zur Zahlung kleiner Beträge verwendet werden. Sobald die Summe einige Euro übersteigt, sind PIN, Unterschrift und ein Foto-Abgleich oder die Vorlage eines zusätzlichen Ausweisdokuments nötig, um eine Multi-Faktor-Authentifizierung zu gewährleisten.
Somit stellt sich die Frage: Kann man über eine Sprachschnittstelle ebenso eine Multi-Faktor-Authentifizierung durchführen – beschränkt auf das Medium der menschlichen Stimme? Die maschinelle Erkennung von Stimmabdrücken gibt es immerhin seit über vierzig Jahren.
Dank moderner Technologien ist es nun möglich, aus Gesprochenem weit mehr als nur einen Authentifizierungsfaktor zu gewinnen.“
So garantieren Provider von Voiceprint-Recognition-Anwendungen eine Zuverlässigkeit von 99,99% bei der Identifikation des Sprechers anhand biometrischer Merkmale. Damit wäre eine belastbare Authentifizierung gesichert. Die Erfahrung zeigt, dass solche Systeme als sicher gelten, wenn mehrere Faktoren zusammenarbeiten.
 Dan Fitzpatrick ist Business Unit Director – Conversational Solutions bei Triplesense Reply (Webseite) und leitet als Head of Experience Technology das Technik-Team des Unternehmens. Er ist verantwortlich für die hohe Qualität der technischen Lösungen sowie die Entwicklungs- und Publikationsprozesse. Zudem ist er Practice Lead „Voice“ bei Reply.
Dan Fitzpatrick ist Business Unit Director – Conversational Solutions bei Triplesense Reply (Webseite) und leitet als Head of Experience Technology das Technik-Team des Unternehmens. Er ist verantwortlich für die hohe Qualität der technischen Lösungen sowie die Entwicklungs- und Publikationsprozesse. Zudem ist er Practice Lead „Voice“ bei Reply. Sollte wider Erwarten eine Sicherungsmethode überwunden werden, greifen weitere. Banken, die Voiceprint-Recognition-Anwendungen einsetzen, verzeichnen zunehmend Angriffs- und Betrugsversuche wie Imitationsattacken mittels Tonaufnahmen (replay attacks) oder White-Noise-Attacken, um Schadcode einzuschleusen. Die Stimme des Opfers könnte zusätzlich theoretisch analog oder digital nachgeahmt werden. Im schlimmsten Fall wäre auch Erpressung denkbar: Das Opfer wird unter Gewaltandrohung gezwungen, eine Transaktion mit der Stimme freizugeben. Zudem muss eine Sprachauthentifizierung den üblichen Hürden von Umgebungsgeräuschen oder mangelnder Privatsphäre im Kassenbereich standhalten.
Über den Voiceprint-Vergleich hinaus ist es denkbar, weitere Mechanismen anzuwenden, um eine sichere Authentifizierung über Sprache zu ermöglichen. Leicht lassen sich zusätzliche akustische Merkmale sowie inhaltliche prüfen, um das Gesprochene dem Verbraucher zuzuordnen. Für die Legitimierung anderer Aspekte einer verbalen Aussage werden verschiedene Technologien der Künstlichen Intelligenz ins Spiel gebracht.
Kontextueller Stresstest erkennt Zwang
Über Triplesense ReplyTriplesense Reply (Webseite) entwickelt technologische Anwendungen, die „zu den Menschen passen und dazu beitragen, das Leben zu erleichtern“. Im Zentrum der digitalen Lösungen und Services stehe dabei die perfekte User Experience für den Konsumenten. Das Leistungsspektrum reiche von der Marketing- und Strategie-Beratung über Digital Business Consulting sowie Konzeption und Kreation bis hin zur technischen Realisierung und Betriebsführung. Das Unternehmen betreut unter anderem Vorwerk, Brose, Vodafone, Fresenius Medical Care, GfK, eprimo oder BMW.Mittels leistungsstarker Machine-Learning-Analyse der Modulation des Gesprochenen ist es möglich, kontextuelle Information zu gewinnen. So kann geprüft werden, ob der Sprecher unter Zwang steht. Ein weiterer Bereich der Künstlichen Intelligenz, sogenannte Emotion AI, kommt zum Einsatz, um für den Sprecher unbewusste Nuancen der Stimmlage zu identifizieren. Hierbei werden über 50 Parameter des Gesprochenen in Echtzeit analysiert. Die wichtigsten unterteilen sich in drei Kategorien: Frequenzeigenschaften (u.a. durchschnittliche Stimmhöhe, Höhenwechsel über Zeit, Schließhöhe, Höhenwechselrate, Spanne der Stimmhöhe), zeitliche Eigenschaften (Kadenz der Worte und Silben, Höhenspitzenfrequenz) und Sprachparameter (Aspirationsstärke, Lautstärke, Klarheit).
Werden diese Charakteristika als Features mit einem Machine-Learning-Modell analysiert, lassen sich bis zu sechzehn Emotionen erkennen. Somit lässt sich klären, dass der Nutzer der Richtige ist, aber gerade nicht in der Lage, eine Transaktion freizugeben.“
Werden diese Charakteristika als Features mit einem Machine-Learning-Modell analysiert, lassen sich bis zu sechzehn Emotionen erkennen. Somit lässt sich klären, dass der Nutzer der Richtige ist, aber gerade nicht in der Lage, eine Transaktion freizugeben.“
Wird eine Stresssituation festgestellt, erfolgt eine erneute Abfrage. Hinzu kommen zwei weitere Absicherungsmechanismen. Ein „Alarmwort“ in der Aussage des Nutzers kann eine Transaktionssperre oder einen Notruf auslösen. Zudem könnte eine Plausibilitätsprüfung anhand von Umgebungsgeräuschen erfolgen. Geht eine Anfrage angeblich aus dem Hauptbahnhof beim Zahlungsanbieter ein, im Hintergrund sind jedoch Möwengeschrei und Brandung zu hören, sollten die Alarmglocken klingeln.
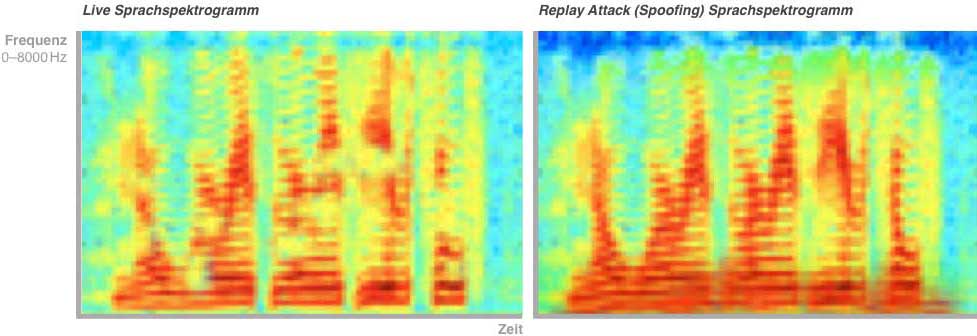
Liveness-Check für eine konforme Identifikation per Sprachauthentifizierung
Eine weitere Methode, akustische Attribute als Sicherheitsmerkmal zu verwenden, ist ein Liveness-Check. Identitätsdiebstahl ist ein häufiges Delikt, die Fallzahlen steigen. Banken sehen sich damit konfrontiert, dass Stimmen bei der Legitimierung gefälscht werden. Es gab Fälle, in denen vermeintliche Vorgesetzte – auch mit künstlich imitierten Stimmen – ihre Firmenangestellten telefonisch auffordern, Gelder zu überweisen.
Der Liveness-Check überprüft, ob man mit einem Menschen aus Fleisch und Blut spricht. Hierzu werden die Frequenzbereiche des Audiostreams spektrographisch analysiert: Im Falle einer Aufnahme oder einer Stimmenmanipulation sind andere Muster erkennbar – besonders im Niederfrequenzbereich – als wenn „live“ gesprochen wird. Unter anderem werden Intensität und Frequenz der Atemgeräusche und tiefere Töne gemessen, weil in Aufnahmen diese vergleichsweise schwach sind oder herausgefiltert werden, damit die Aufnahmen an Klangklarheit gewinnen. Somit lassen sich Betrugsversuche erkennen und abwehren. Zusätzlich kann das abfragende System dem Gespräch akustische Merkmale hinzufügen, aus denen es eine Art Rückkoppelung oder Echo erwartet. Fehlen diese, handelt es sich um ein Playback. Über die Stimme hinaus werden beim Sprechen Luftströmungsgeräusche erzeugt, wenn der Sprecher in Richtung Mikrofon ausatmet. Diese sogenannten „Pops“ und „Plosives“ sind messbar und werden als Liveness-Indikator gewertet. In einer Aufnahme würden auch diese fehlen.
Triplesense Reply
Codierte Passwörter im öffentlichen Raum
Doch wie funktioniert eine verbale Passwortübermittlung in einer Supermarkt-Kassenschlange? Verbraucher sind es gewohnt, einen gewissen Diskretionsabstand einzuhalten und die PIN-Eingabe mit Sichtschutz einzugeben.
Keiner wird sein Passwort vor versammeltem Publikum ins Mikrofon sprechen.“
Am sichersten ist eine Einmalverschlüsselung oder one-time-pad, in der die Chiffre zur Entschlüsselung nur dem Sender und Empfänger bekannt ist. Für den Passwortschutz werden Natural Language Understanding-Technologien in Form von semantischen Netzwerken und Ontologien (knowledge graphs) verwendet. Basierend auf Platons Ideenlehre und der Hierarchie der intelligiblen Entitäten, können digitale, semantische Netzwerke aus den Begriffen der menschlichen Sprache Milliarden von logischen Zusammenhängen zwischen Begriffsattributen speichern und die Bedeutung menschlicher Sprache algorithmisch erfassen und verarbeiten. In der Praxis hinterlegt der Nutzer wie bei der Erstellung eines Passworts beim Finanzinstitut ein geheimes Objekt wie „Piratenschiff“. Daraufhin erstellt die Passwortverwaltungsanwendung ontologisch eine Vielzahl von Quizfragen zum Objekt: „Ist dein geheimes Objekt aus Stein gebaut?“ „Nenn mir bitte einen Buchstaben, der im Namen deines Objekts vorkommt und einen, der nicht vorkommt.“ An der Kasse oder im Call-Center und bei der Sprachauthentifizierung werden die Fragen über eine Sprachschnittstelle gestellt. Sind die Antworten richtig, findet die Transaktion statt.

Fuzheado, CC BY-SA 4.0 <https://creativecommons.org/licenses/by-sa/4.0>, via Wikimedia Commons
Vorteile und Vision
Sowohl für Finanzinstitute als auch für Verbraucher bietet Sprachauthentifizierung viele Vorteile: Einerseits mehr Sicherheit als herkömmliche Bankkarten oder TAN-Verfahren und andererseits die Bequemlichkeit, ohne Bargeld, Handy oder Brieftasche Transaktionen durchführen zu können. Wird eine Bankkarte, die mit Unterschrift und PIN vordergründig eine leicht fälschbare oder in Erfahrung zu bringende Zweifaktorauthentifizierung bietet, mit einer Sprachlegitimierung verglichen, so ermöglicht diese gleich vierfachen Schutz mit Voiceprint, Stress-Test, Liveness-Check sowie Einmalpasswort.
Zudem wären Funktionen und Dienste verfügbar, die bislang aufgrund höherer Sicherheitsanforderung nur Sachbearbeiter aussteuern dürfen – wie die Freigabe von Zahlungsmitteln für eine Baufinanzierung. Der Bauherr müsste nicht mehr während der Öffnungszeiten zur Bank, sondern könnte fristgerecht die Transaktionen von zuhause aus erledigen.Dan Fitzpatrick und Maria Müller, Triplesense Reply
Sie finden diesen Artikel im Internet auf der Website:
https://itfm.link/124394


Schreiben Sie einen Kommentar