Mit Graph Algorithmen & ML Vorhersagen treffen

Neo4j
Machine Learning (ML) und prädiktive Analytik wird zur wichtigen Waffe im Kampf gegen Finanzbetrug. Den meisten Modellen fehlt jedoch etwas Entscheidendes: Graph Algorithmen. Nur damit lassen sich versteckte Muster in Interaktion zwischen Teilnehmern aufdecken.
von Michael Hunger, Director Developer Relations bei Neo4j
Die (soziale) Netzwerkanalyse kann hier wichtige Impulse für die Betrugsaufdeckung liefern. Sie erfasst und untersucht die inhärenten Beziehungen zwischen einzelnen Datenelementen und stellt die Verbindungen und Interdependenzen in den Vordergrund.
Damit lassen sich Beziehungen zwischen Personen und Organisationen, aber auch Interaktionen mit Bankkonten, Kreditkarten oder Transaktionen systematisch und quantifizierend beschreiben und auswerten.“
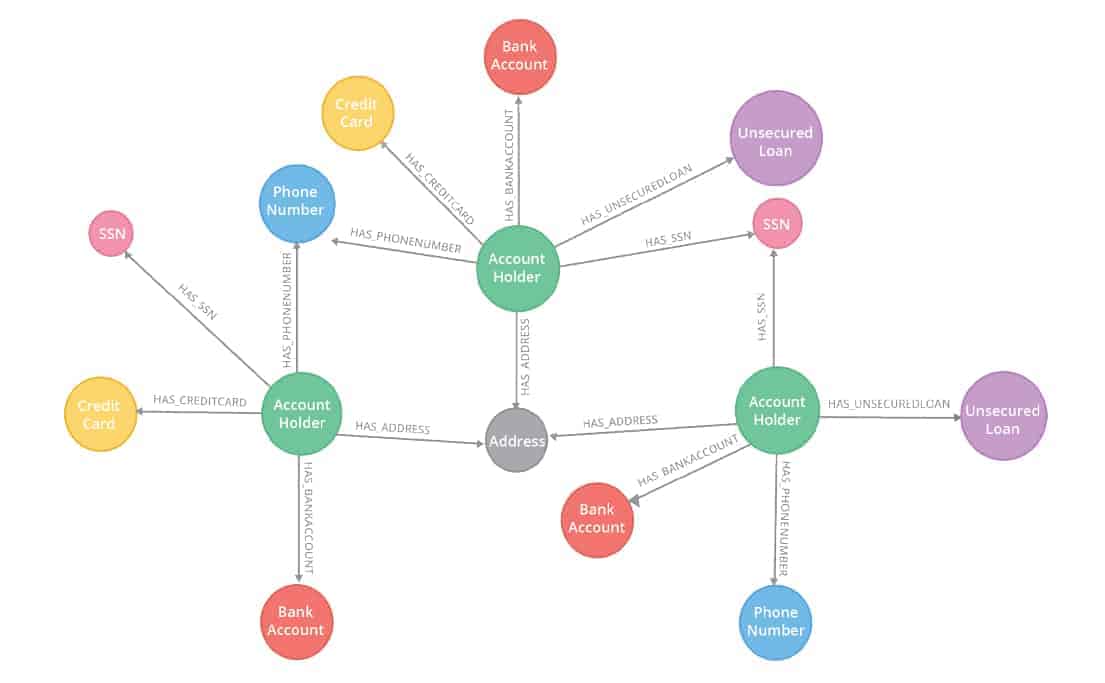
Sind zum Beispiel bei unterschiedlichen Kontoinhabern (keine Wohngemeinschaft) dieselbe Wohnadresse oder Telefonnummer hinterlegt, kann dies auf einen möglichen Identitätsbetrug hindeuten (siehe Abbildung 01).
Neo4j
Mit traditionellen Datenbank-Management-Systemen (z. B. relationalen Datenbanken) lässt sich die Analyse eines solchen komplexen Netzwerks mit Millionen von Datensätzen nicht mehr durchführen.“
Dafür ist die Workload schlichtweg zu komplex (wächst exponentiell). Um vernetzte Daten zu erfassen und abfragen zu können, kommt daher verstärkt Graph-Technologie zum Einsatz.
Drei Verfahrensweisen von Graph Analytics
Ein Graph setzt sich aus sogenannten Knoten (Nodes) und Kanten (Edges) zusammen, denen jeweils unterschiedliche Eigenschaften (Properties) zugewiesen sind. Im Folgenden werden drei Herangehensweisen für die Betrugsaufdeckung mit Hilfe von Graph-Datenbanken beschrieben:
- Gezielte Suchabfragen (Data Exploration)
Um vorhandene Beziehungen zwischen einzelnen Datenpunkten im Graphen zu ermitteln, gilt es zunächst Abfragen zu starten und die Daten zu „erkunden“. So erhalten Data Scientists und Ermittler schnell einen Überblick und können erste Schlussfolgerungen ziehen. Die deklarative Abfragesprache für Graphen, Cypher, ist dabei sehr intuitiv und erlaubt es, selbst komplizierte Abfragen schnell und einfach zu formulieren. Über die Abfrage in Abbildung 02 lässt sich so die kürzeste Verbindung (Shortest Path) zwischen einem Startknoten und den damit verbundenen E-Mail-Adressen und/oder Telefonnummern bestimmen.

Neo4j
Diese relativ einfachen Queries stellen den Ausgangspunkt für nachfolgende Analysen dar. Finden sich beim Startknoten Hinweise auf betrügerische Aktivitäten, lohnt sich ein Blick auf die benachbarten Knoten und Beziehungen. Eine wichtige Rolle bei diesem Analyseschritt spielt die anschauliche Visualisierung der Daten. Explorative Abfrage- und Visualisierungstools wie Neo4j Bloom ermöglichen interaktive Suche und Exploration des Netzwerks vom Detailausschnitt bis zu zehntausenden von Datenpunkten auf einmal. Darüber hinaus können Data Scientists und Investigatoren Knoten auswählen, fixieren und editieren sowie codefreie, vorkonfigurierte Suchvorgänge starten. Visualisierungsattribute können von Eigenschaften der Daten abhängig gemacht werden.
- Neue Erkenntnisse durch Algorithmen (Data Discovery)
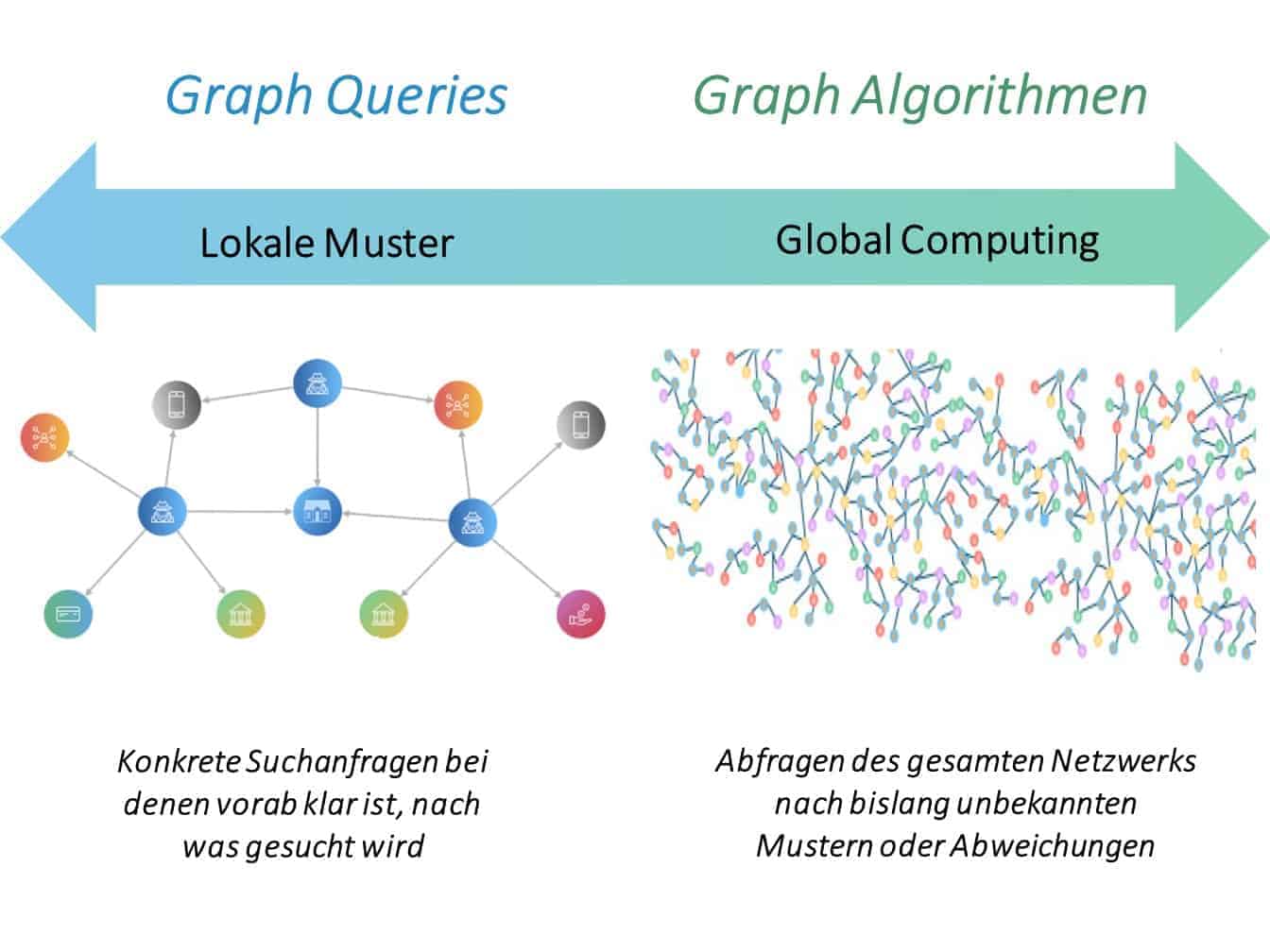
Für konkrete Suchanfragen – z. B. das Aufspüren von Personen im erweiterten Netzwerk eines bekannten Betrügers – ist diese Form der Analyse völlig ausreichend. Um jedoch die Datensätze auf bislang unbekannte Muster oder Abweichungen hin zu untersuchen, sind Graph-Algorithmen nötig. Sie sind in der Lage, automatisch Strukturen und Zusammenhänge aufzudecken, die bei normalen Abfragen weitgehend ungenutzt bzw. unentdeckt bleiben.
Graph-Algorithmen erfüllen unterschiedliche Aufgaben und lassen sich in verschiedene Kategorien unterteilen. Algorithmen in der Kategorie Community Detection identifizieren beispielsweise auffällige Cluster, die von Betrugsanalysten weiter untersucht und auf kriminelle Merkmale überprüft werden können. Gibt es für die starke Verflechtung zwischen zwei Kontoinhabern eine logische Erklärung? Oder verbirgt sich dahinter ein Netzwerk an Betrügern? Zentralitätsbewertungen liefern Hinweise auf zentrale Elemente eines Clusters oder Verbindungsgliede verschiedener Cluster.
Neo4j
Graph-Algorithmen liefern zuverlässige Erkenntnisse, wenn sie sich einfach und schnell innerhalb eines Graphen ausführen lassen.“
Daher empfiehlt es sich, globale und optimierte Algorithmen-Implementierungen einzusetzen, die integriert in der Graph-Datenbank reproduzierbare Ergebnisse liefern und sich entsprechend skalieren lassen. In der Graph Data Science Library von Neo4j stehen eine ganze Reihe an unterschiedlichen Graph-Algorithmen zur Verfügung, die Anwender ohne großen Aufwand für ihre Analysen heranziehen können.
- Graph-Features & Machine Learning-Modelle
Durch Graph-Algorithmen lassen sich nicht nur neue Erkenntnisse gewinnen, sondern auch prädiktive Parameter ermitteln.“
Identifiziert beispielsweise ein Community-Detection-Algorithmus ein für einen Betrugsfall charakteristisches Merkmal, kann dieses Graph Feature als Knoten, Kante oder im Graphen gespeichert, oder direkt in ein Klassifizierungsmodell überführt werden. Graph Features sind dabei sehr vielfältig: Sie bezeichnen den Cluster, oder das Zentralitätsattribut eines Knotens, beschreiben komplexe Berechnungen, wie die Nähe zu bekannten betrügerischen Konten, oder stufen die Ähnlichkeit mit bereits bekannten Betrugsfällen ein.
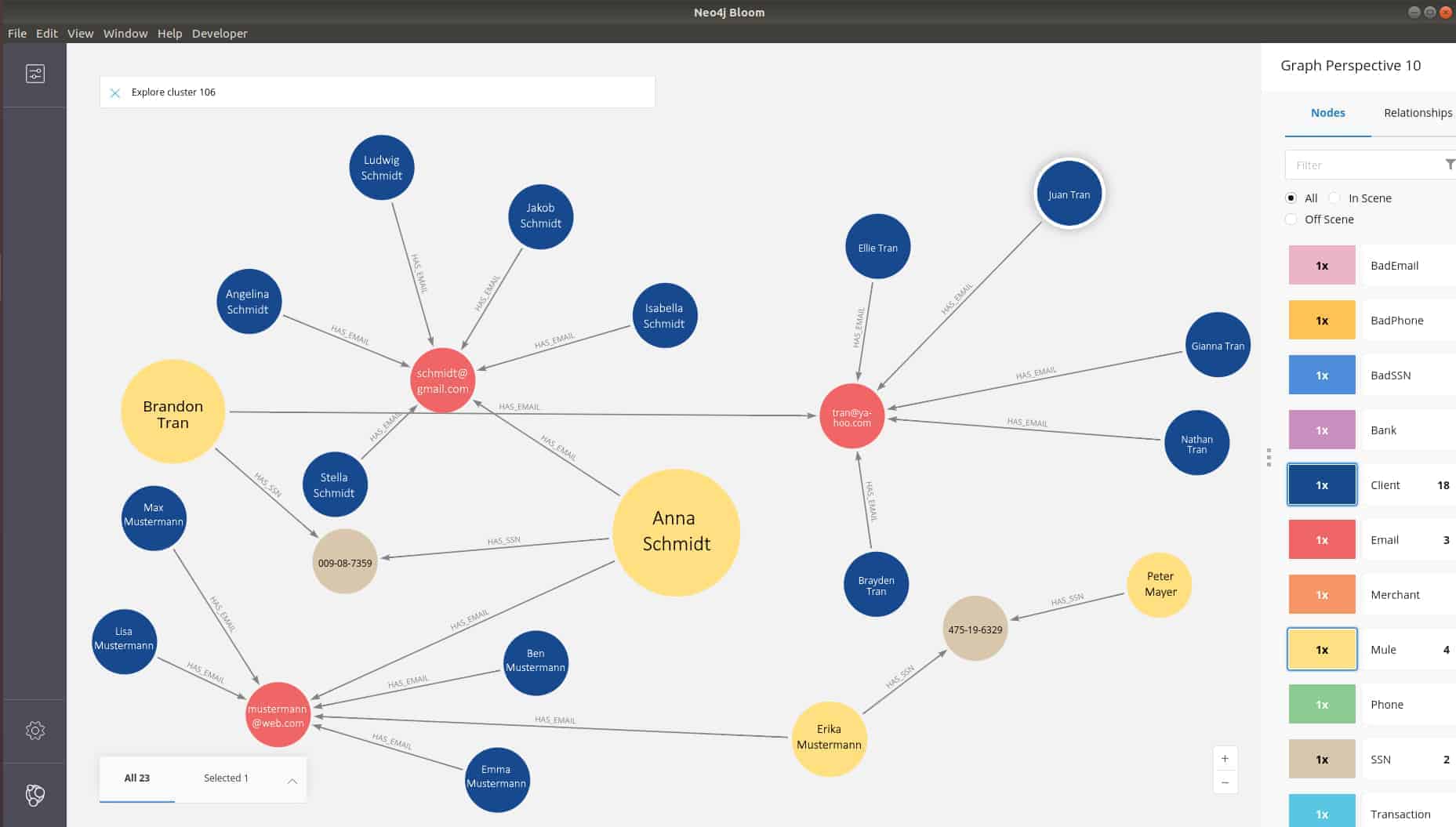
Im Graphen in Abbildung 04 wurden dazu zwei Abfragen durchgeführt: Der Community-Detection-Algorithmus spürt zunächst verdächtige Aktivitäten auf. Der Betweenness-Centrality-Algorithmus bewertet anschließend den Einfluss eines jeden Knotens bei der Verbindung von Clustern. Je höher der Wichtigkeit des Knotens, desto größer wird der Knoten dargestellt. Das Ergebnis zeigt ein verdächtiges Cluster von Personen, die gemeinsame Merkmale (z. B. E-Mail-Adresse und Telefonnummer) teilen. Die Größe der gelben Knoten weisen darauf hin, dass es sich bei diesen Personen mit großer Wahrscheinlichkeit um Strohmänner handelt.
Neo4j
Einmal validiert können die prädiktiven Merkmale in Machine Learning-Modelle integriert werden, um so die Genauigkeit zukünftiger Vorhersagen zu optimieren.“
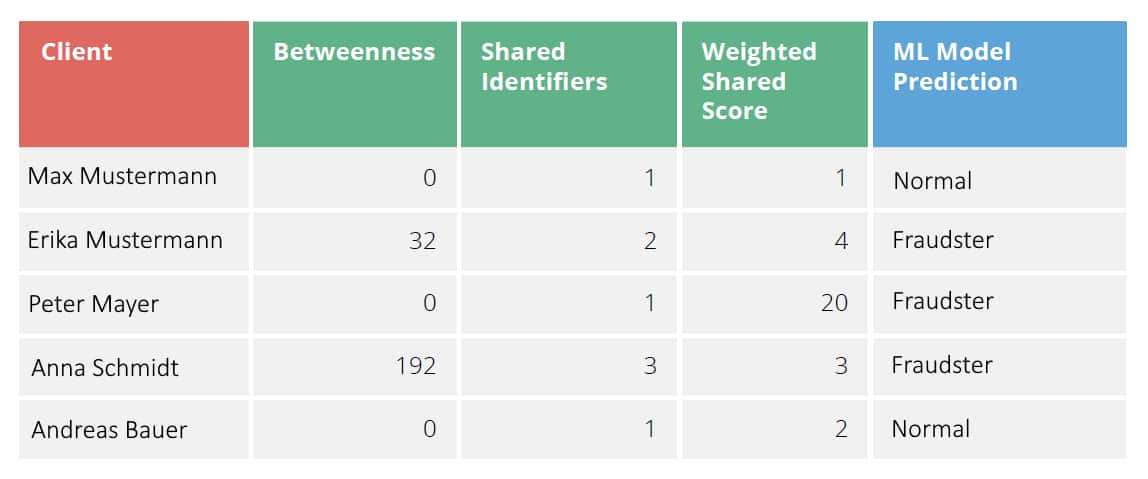
Die in der Analyse gewonnen Informationen dienen dazu als Grundlage. Die Beispieltabelle (Abbildung 05) zeigt, wie die einzelnen Daten zusammengeführt und in ein prädiktives ML-Modell überführt werden.
Neo4j
Aufgelistet sind die bereits bekannten Personen bzw. Kunden aus dem oben angeführten Graphen einschließlich: Betweenness-Centrality-Wert, die Anzahl der Identitäten, die sie mit anderen Personen teilen (Shared Identifiers), und die Gewichtung dieser Merkmale (Weighted Shared Score). Max Mustermann teilt seine E-Mail-Adresse scheinbar mit mehreren Familienmitgliedern und wird daher als unverdächtig („normal“) eingestuft. Erika Mustermann und Anna Schmidt sind wiederum stark vernetzt, teilen mehrere Merkmale mit anderen und müssen daher als potenzielle Betrügerinnen angesehen werden. Peter Mayer teilt zwar nur ein Merkmal mit einer anderen Person. Da es sich dabei jedoch um die Sozialversicherungsnummer und damit um eine einmalig zugeordnete Personenkennzahl handelt, fällt diese Gemeinsamkeit stärker ins Gewicht und macht ihn automatisch verdächtig.
8 Schritte zur Aufdeckung von Betrugsringen
Autor Michael Hunger, Neo4j Michael Hunger arbeitet seit 2010 bei Neo4j (Webseite) in den verschiedensten Funktionen an der Weiterentwicklung der Graph-Datenbank mit. Als erster Ansprechpartner für die Neo4j Community unterstützt er Anwender bei der Realisierung graphbasierter Anwendungen aller Art. Als Entwickler stürzt er sich mit Begeisterung auf neue Facetten der Programmiersprachen, beteiligt sich an ambitionierten Open-Source-Projekten und schreibt in Büchern, Blogs und Fachartikeln über Software.
Michael Hunger arbeitet seit 2010 bei Neo4j (Webseite) in den verschiedensten Funktionen an der Weiterentwicklung der Graph-Datenbank mit. Als erster Ansprechpartner für die Neo4j Community unterstützt er Anwender bei der Realisierung graphbasierter Anwendungen aller Art. Als Entwickler stürzt er sich mit Begeisterung auf neue Facetten der Programmiersprachen, beteiligt sich an ambitionierten Open-Source-Projekten und schreibt in Büchern, Blogs und Fachartikeln über Software.
Michael Hunger arbeitet seit 2010 bei Neo4j (Webseite) in den verschiedensten Funktionen an der Weiterentwicklung der Graph-Datenbank mit. Als erster Ansprechpartner für die Neo4j Community unterstützt er Anwender bei der Realisierung graphbasierter Anwendungen aller Art. Als Entwickler stürzt er sich mit Begeisterung auf neue Facetten der Programmiersprachen, beteiligt sich an ambitionierten Open-Source-Projekten und schreibt in Büchern, Blogs und Fachartikeln über Software.Welche Art der Analyse am effektivsten ist, welche Algorithmen zum Einsatz kommen und welche Merkmale ausgewählt werden, hängt immer auch vom Anwendungsfall ab. Exemplarisch sind hier die wichtigsten Schritte für die Aufdeckung von Betrugsringen mittels geteilter Identitäten noch einmal zusammengefasst:
- Der Aufbau eines Graphmodells, bestehend aus Personen und den mit ihnen verbundenen Entitäten (z. B. Konto, Kundenummer, IP-Adresse, E-Mail-Adresse, Telefonnummer, Personalausweis, Wohnadresse).
- Suchkriterien definieren, um Auffälligkeiten und Hinweise auf betrügerische Aktivitäten richtig einordnen und identifizieren zu können. Dazu zählen u. a.:
- Gemeinsame Merkmale/Identifier (Wohnadresse, Sozialversicherungsnummer)
- Nutzung eines Kontos durch mehrere Personen
- Barabhebungen von erst kürzlich getätigten Überweisungen
- Auffällig hohe Transaktionssummen
- Um verdächtige Muster aufzudecken, sollten im Graphen erste einfache Abfragen gestartet werden, z. B. die gemeinsame Nutzung derselben E-Mail-Adresse von mehreren Personen. Diese Queries stellen den Ausgangspunkt weiterer Untersuchungen dar.
- Ausführen einer Reihe von Graph-Algorithmen für die Aufdeckung von betrügerischen Netzwerken.
- Community-Detection-Algorithmen erfassen Gruppen von Personen, die über verschiedene Benutzerkonten hinweg an bekannten Betrugsfällen beteiligt sind
- Über den Louvain-Modularity-Algorithmus lassen sich Hierarchien zwischen den Gruppen identifizieren. Vorher festgelegte Schwellenwerte trennen Kleinkriminelle von organisierten, großangelegten Betrugsringen und erlauben eine Priorisierung der weiteren Untersuchungen.
- Der PageRank-Algorithmus misst die Wichtigkeit jedes Knotens innerhalb eines Graphen und identifiziert/unterscheidet einflussreiche Personen, Drahtzieher, Hintermänner und Mitläufer.
- Wurde ein Betrugsring erfolgreich aufgedeckt, können Ermittler mit Hilfe von Ähnlichkeits(Similarity)- Algorithmen (z. B. Jaccard) nach weiteren potenziellen Betrügern innerhalb der Daten suchen.
- Nach ausreichender Validierung wird die Abfolge der ausgeführten Algorithmen und Analyseschritte sowie die neu gewonnenen Informationen und Ergebnisse als Parameter oder Graph Features gespeichert. Die Vorgehensweise kann dann in der Praxis eingesetzt werden.
- Für zukünftige Analysen lassen sich die Graph Features in ein Machine-Learning-Modell überführen und mit anderen relevanten Daten anreichern. Damit können Vorhersagen über betrügerische Aktivitäten getroffen werden (Prädiktive Analyse).
- Neue Daten sowie relevante Ergebnisse und Prognosen werden im Graphen abgelegt und fließen kontinuierlich in den Analyseprozess ein, um so die Genauigkeit und Schnelligkeit der Betrugsaufdeckung weiter zu verbessern.Michael Hunger, Neo4j
Sie finden diesen Artikel im Internet auf der Website:
https://itfm.link/115477


Schreiben Sie einen Kommentar