Finanzrisiko Systemausfälle: BC/DR-Strategien reichen nicht, aber Hypervisor-basiertes CDP

Zerto
Systemausfälle stellen für Unternehmen ein hohes Risiko dar. Normale BC/DR-Strategien decken diese Risiken nicht mehr ab. Es ist an der Zeit, sie zu erneuern oder ihre Bedrohung neu zu bewerten.
von Johan van den Boogaart, Zerto
Banken und Versicherungen wissen es besser als jeder andere: Kritische IT-Systeme müssen rund um die Uhr arbeiten, um in der modernen Welt erfolgreich zu sein. Die Bedeutung der IT hat in jeder Branche erheblich zugenommen, ebenso wie die Risiken, die mit den Gefahren von Systemausfällen, Ransomware-Attacken, Naturkatastrophen oder anderen Gründen für den Ausfall von Systemen verbunden sind. Je abhängiger ein Unternehmen von seinen Systemen ist, desto höher ist das Risiko für das Unternehmen an sich.
Um das Risiko entsprechend einschätzen zu können, müssen Versicherer, Kreditgeber und andere Finanzinstitute den Stand der aktuellen BC/DR-Strategien kennen, die Unternehmen online halten sollen. Nur dann können sie das Risiko für ein korrektes Scheitern eines Unternehmens aufgrund unzureichender Systemsicherheit einschätzen.
Systemausfälle passieren – und stellen ein enormes Risiko für Unternehmen dar
British Airways, Azure oder AWS – Systemausfälle kommen aus verschiedensten Gründen häufig vor. Wenn das Geschäft betroffen ist, sorgen sie für unschöne Schlagzeilen und hohe Summen an verlorenen Einnahmen. Die Luftfahrtindustrie ist ein gutes Beispiel dafür. Mehrere große Fluggesellschaften erlitten im vergangenen Jahr folgenschwere Systemausfälle, die ihren Betrieb schwer beeinträchtigten. British Airways war gar mehrere Tage nicht in der Lage, ihre ausgefallenen Systeme wieder zum Laufen zu bringen. Der Ausfall hielt nicht nur einen Großteil der Flotte am Boden, sondern auch Zehntausende Passagiere. In diesem Fall war die Tatsache, dass der Flugbetrieb ausgesetzt war, für BA schon schlimm genug. Peinlich wurde es erst, als bekannt wurde warum: Ein Mitarbeiter hatte in einem arglosen Moment ein System abgeschaltet, das sich partout nicht mehr einschalten ließ. Menschliches Versagen sollte jede Organisation beunruhigen, die dasselbe Schicksal erleiden könnte. BA als prominente Marke ist aber nur ein Beispiel für Tausende von ähnlichen Fällen, in denen Unternehmen große Verluste durch Systemausfälle erlitten haben, ohne öffentlich abgestraft zu werden.
Zerto
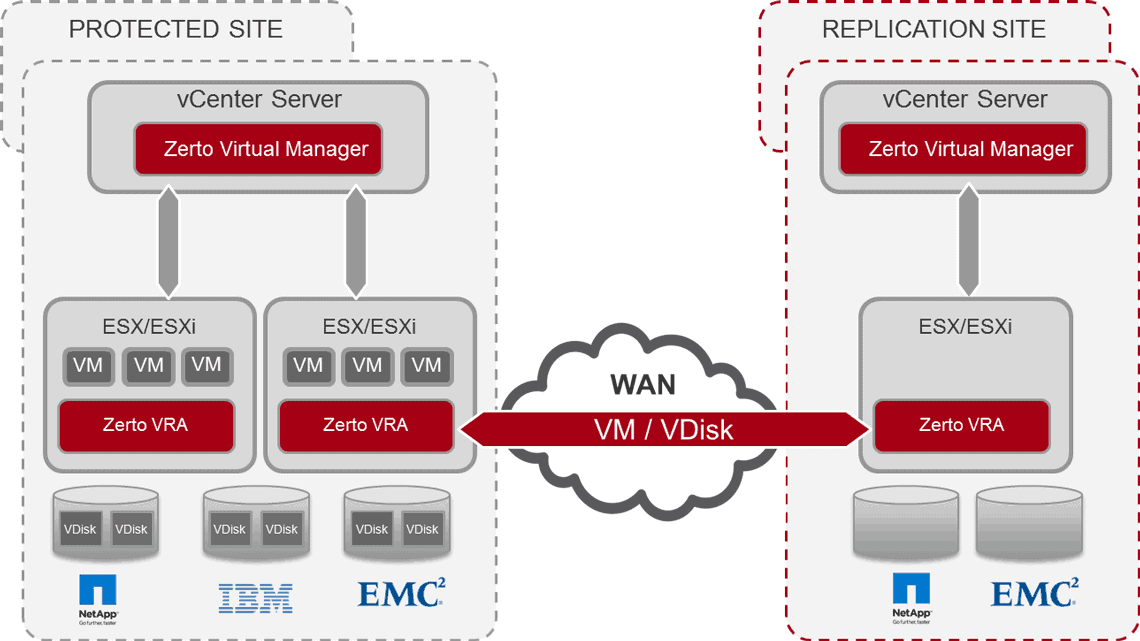
Auf technischer Ebene verfügen Organisationen bereits über Strategien, um Systemausfälle theoretisch zu verhindern: Stretched Cluster sollen die Verfügbarkeit gemeinsam mit Snapshots und Backups gewährleisten. Angesichts erfolgreicher Ransomware-Angriffe und Systemausfällen, die theoretisch nicht hätten passieren dürfen, beginnen Unternehmen zu erkennen, dass Investitionen in Disaster-Recovery-Technologien sie nur vor Hardware-Ausfällen und nicht vor logischen Fehlern schützen, wie eben Ransomware oder menschliches Versagen.
Der aktuelle Standard bei der Notfallwiderherstellung: Der Stretched Cluster
Um zu verstehen, warum es regelmäßig zu Ausfällen kommt, ist es notwendig, sich anzusehen, welchen aktuellen BC/DR-Strategien die IT folgt. Um die höchstmögliche Verfügbarkeit zu erreichen, haben Unternehmen auf der Hardwareseite in Stretched Cluster investiert. Snapshots und regelmäßige Backups auf der Softwareseite komplementieren diese und sollen RPOs und RTOs auf ein Minimum reduzieren. Der Stretched Cluster bietet im Idealfall ein transparentes Failover im Falle eines Hardwareausfalls oder gar eines kompletten Desasters, das einen ganzen Standort betrifft. Die Nachteile eines ‚gestreckten Clusters’ sind seine hohen Kosten und Komplexität und die oft übersehene Tatsache, dass er nicht vor logischen Fehlern oder verlorenen Daten von Anwendungen schützt.
 Johan van den Boogaart (Zerto) blickt auf fast zwei Jahrzehnte Erfahrung in der IT-Branche zurück. Seine Themen sind Storage, Disaster Recovery und Virtualisierung. Vor Zerto verantwortete Boogaart den Vertrieb von Nexenta und Open-E in der deutschsprachigen Region als Sales Manager. Bei Acronis bekleidete er davor den Posten des OEM/ Corporate Account Managers. Boogaart ist Diplom-Kaufmann und Absolvent der Universität Groningen.
Johan van den Boogaart (Zerto) blickt auf fast zwei Jahrzehnte Erfahrung in der IT-Branche zurück. Seine Themen sind Storage, Disaster Recovery und Virtualisierung. Vor Zerto verantwortete Boogaart den Vertrieb von Nexenta und Open-E in der deutschsprachigen Region als Sales Manager. Bei Acronis bekleidete er davor den Posten des OEM/ Corporate Account Managers. Boogaart ist Diplom-Kaufmann und Absolvent der Universität Groningen.Was hat der RTO mit Zinssätzen zu tun?
Die alles entscheidende Frage, wie sicher ein System ist und wie hoch die Risiken für einen Kreditgeber sind, sein Geld zu verlieren, läuft im Grunde genommen auf Folgendes hinaus: Was ist der RTO? Der RTO beschreibt die Länge der Zeit, in der ein Unternehmen einen Systemausfall überwinden kann. Ein CEO weiß vielleicht nicht einmal, was eine RTO ist und dass sich dieser auf die Zinssätze der Darlehen seines Unternehmens auswirken kann. Aber je mehr eine Organisation von ihrer IT abhängig ist, desto eher werden sich Banken dafür interessieren, wie hoch das Risiko eines Kreditausfalls tatsächlich ist.
Irgendwann wird die Frage, wie hoch oder niedrig der RTO einer Organisation ist, zwangsläufig an einen IT-Manager gehen, der für die BC/DR-Strategie eines Unternehmens verantwortlich ist. Obwohl es die Aufgabe dieses IT-Managers ist, die Verfügbarkeit jederzeit und um jeden Preis zu gewährleisten, ist es in der Realität oft nicht so einfach, die genaue Antwort zu geben. Selbst mit den fortschrittlichsten und teuersten Speichersystemen, die auf Stretched-Cluster-Technologie basieren, können die meisten IT-Administratoren den RTO ihres Systems nicht benennen. Natürlich könnte der genaue RTO durch einen DR-Test ermittelt werden, der auch regelmäßig durchgeführt werden sollte, um zu zeigen, dass das System funktioniert und für eine mögliche Katastrophe in der realen Welt gerüstet ist.
DR-Tests sind in der Theorie einfach und in der Praxis oft unmöglich.
Um zu prüfen, ob ein System einer Katastrophe standhalten kann, muss eine Organisation einen DR-Test durchführen. So lässt sich feststellen, ob die BC/DR-Strategie generell funktioniert und wie schnell alles wieder normal läuft. DR-Tests sind in der Theorie sehr einfach – man zieht den Stecker und startet die Stoppuhr. Das Vertrauen der meisten IT-Manager in ihr DR-Setup scheint jedoch nicht sehr hoch zu sein – trotz der hohen Summen, die dafür bezahlt wurden. Kein IT-Manager, der bei klarem Verstand ist, würde jemals einfach nur den Stecker eines funktionierenden Systems ziehen, obwohl er viel Geld bezahlt hat, dass er es könnte. Gerade in großen Organisationen mit vielen Daten können selbst geplante DR-Tests nahezu unmöglich werden. Die einzige Zeit des Jahres, in der diese großen Unternehmen ihre DR-Tests tatsächlich durchführen können, ist zwischen Weihnachten und Neujahr. Es ist nicht ungewöhnlich, dass große Unternehmen ein erfolgreiches Disaster-Recovery-Failback nicht innerhalb von acht Tagen oder mehr abschließen, da die zu verschiebenden Datenmengen einfach zu groß sind. Was jedoch sagt das über die Compliance und die Fähigkeit dieser Organisationen aus, Katastrophen zu vermeiden, wenn sie in Wirklichkeit nicht in der Lage sind, DR-Tests durchzuführen?
Zerto
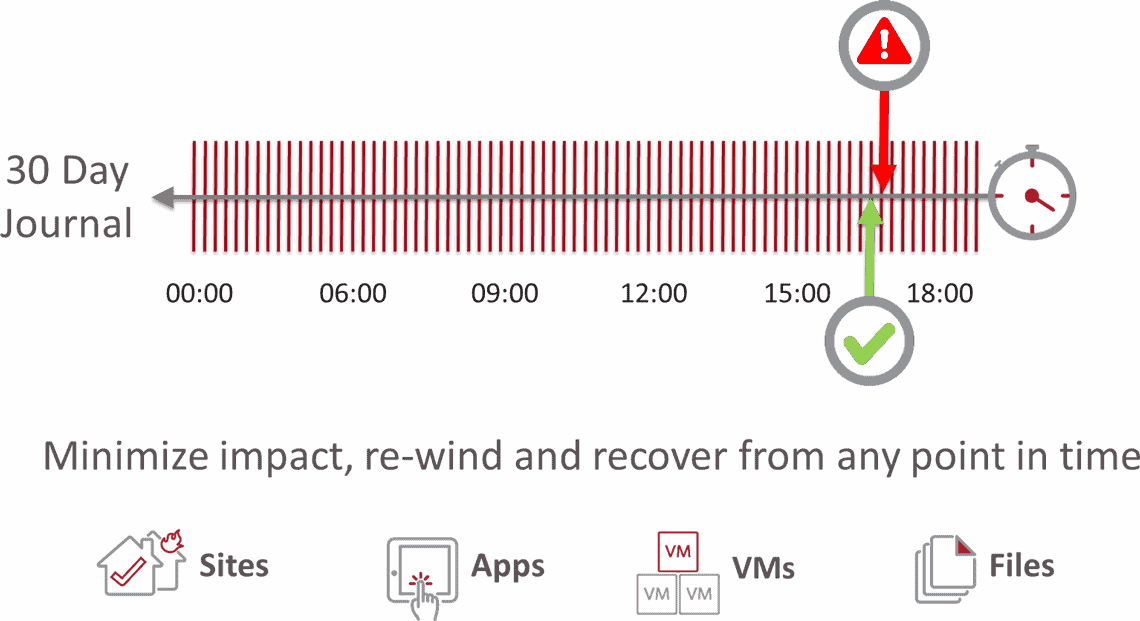
Der aktuelle Stand der Technik für BC/DR: Hypervisor-basiertes CDP
Finanzinstitute betreiben in Bezug auf die Verfügbarkeit sehr aufwändige IT-Systeme. Diese sind notwendig, da die Finanzindustrie sehr stark von diesen Systemen abhängig ist. Sie kennen das Risiko noch so kleinerer Systemausfälle, geschweige denn größerer Ausfallzeiten, die nicht nur Milliarden an Umsatzeinbußen verursachen würden, sondern auch einen immenser Vertrauensverlust ihrer Kunden und Partner bedeuten würden. Um Ausfallzeiten zu vermeiden, haben die meisten großen Finanzinstitute bereits in Lösungen investiert, die zusätzlich zu ihren hardwarezentrierten Lösungen, die auf der Stretched-Cluster-Technologie basieren, auch vor logischen Fehlern schützen. Hypervisor-basierte Continuous Data Protection (CDP) ist der Stand der Technik, wenn es um BC/DR-Strategien geht. Hypervisor-basiertes CDP erweitert die Funktionalität der Stretched-Cluster-Technologie, indem es Unternehmen in die Lage versetzt, sich auch von menschlichem Versagen oder anderen logischen Fehlern zu erholen. Es bietet auch die Möglichkeit, DR-Tests mit einem Mausklick in Sekundenschnelle durchzuführen, um zu beweisen, dass ein System in der Lage ist, jeglichen Ausfällen standzuhalten.
Um die Risiken der Unternehmen einzuschätzen, mit denen Finanzinstitute Geschäfte tätigen oder Geld verleihen, ist es nur eine Frage der Zeit, wann Banken die Sicherheit von IT-Systemen, die sie bereits selbst nutzen, in ihre Risikobewertung einbeziehen. Finanzinstitute müssen die Unzulänglichkeiten der derzeit weit verbreiteten BC/DR-Strategien auch auf der Geschäftsseite verstehen, um das Risiko richtig bewerten zu können. Gleichzeitig müssen sich alle Unternehmen darauf vorbereiten, nicht nur vor Hardwareausfällen, sondern auch vor logischen Fehlern abzusichern. Dieses Vorgehen könnte eines Tages nicht nur das Unternehmen selber retten, sondern kann vielleicht ein paar Prozentpunkte des Zinssatzes für die Darlehen ihrer Unternehmen sparen.aj
Sie finden diesen Artikel im Internet auf der Website:
https://itfm.link/66160


Schreiben Sie einen Kommentar