
Demokratisierung von KI, NLP und Text Analytics: eine Chance für kleine und mittelgroße Finanzinstitute

Die Demokratisierung der Künstlichen Intelligenz hat gezeigt, dass die Herausforderung für Finanzdienstleister nicht in der technologischen Fähigkeit liegt, sondern vielmehr in der Identifizierung von wertschöpfenden Anwendungsfällen.
von George Karapetyan, Data Science & Machine Learning, LPA Gruppe
NLP-Bibliotheken wie Spacy, Hugging Face und Modelle wie der Googles Switch Transformer oder GPT-3 von Open AI ermöglichen es technologisch versierten Teams in Banken, diese Innovation zu nutzen. Die Anwendung von Transfer Learning senkt die Einstiegshürden wie Datenverfügbarkeit und Rechenleistung für das Training erheblich, und somit wird kleineren Finanzinstituten die Implementierung anspruchsvoller Anwendungsfälle ermöglicht. Auf der anderen Seite bringt die Verbreitung von No-Code- oder Low-Code-Plattformen für Machine Learning & KI die Technologie zu den Fachbereichen. Kleine und mittelgroße Finanzinstitute können somit einen Wettbewerbsvorteil generieren, anstatt dem Markt zu folgen. Mit diesem Artikel zeige ich mehrere Anwendungsfälle aus der Branche auf, die für kleine und mittelgroße Finanzdienstleister als Idee für diesen Mindset-Wechsel dienen können.Folgende Techniken können bei den Finanzinstituten benutzt werden, um unstrukturierte Textdaten zu verarbeiten:
1. Schlüsselsätze: Extrahieren von Schlüsselsätzen aus einem umfangreichen Text, um einen effizienten Überblick zu generieren
2. Sentiment Analyse: Analyse der einem Text zugrundeliegenden Stimmung auf Basis von Themen, Einheiten oder zeitlicher Richtung von Aussagen, um granulare Erkenntnisse zu generieren
3. Identifizierung der temporalen Richtung: Identifizierung der temporalen Richtung der Aussagen zwecks Relevanzbewertung
4. Topic Extraction: Extrahierung von Aussagen in Bezug auf relevante Themen für Ihre Analyse
5. Q&A – semantische Suche: Suche basierend auf der semantischen Ähnlichkeit, um die relevantesten Aussagen zu den Suchbegriffen anzeigen zu können, anstatt nach exakten Stichwortübereinstimmungen zu suchen.
Anwendungsfälle in der Due Diligence
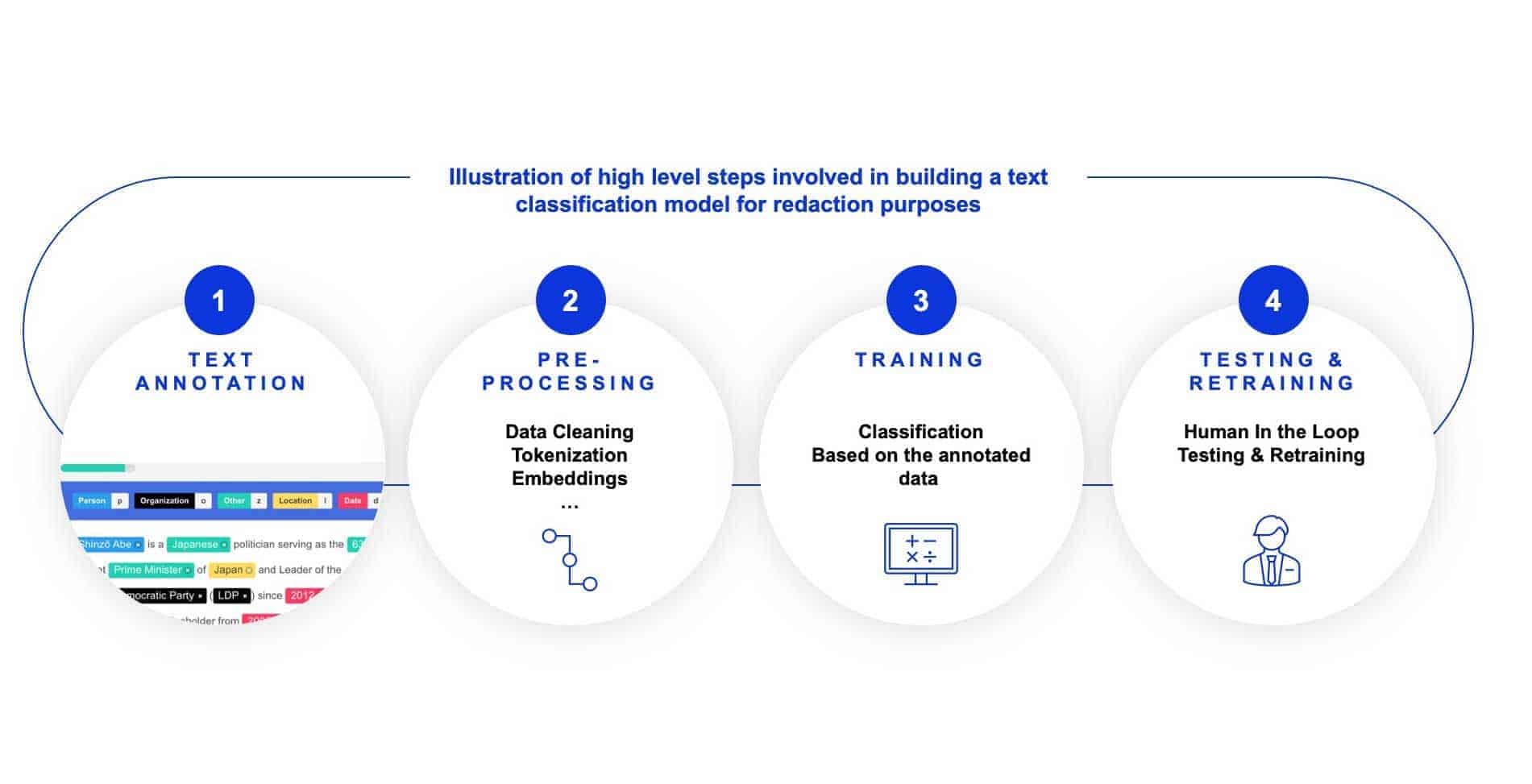
Ob Fusionen, Übernahmen oder Private-Equity-Transaktionen, die Due Diligence ist ein komplexer Prozess, der stundenlange professionelle Arbeit von verschiedenen Parteien erfordert. Eine der Tätigkeiten dabei ist die Schwärzung vertraulicher Informationen aus bestimmten Dokumenten, was mitunter eine kostenintensive, aufwändige Handarbeit sein kann. NLP- und Text-Analytics-Techniken wie Named Entity Recognition, semantische Ähnlichkeit und Bildverarbeitung bieten in diesem Zusammenhang nun eine Vielzahl von Anwendungsmöglichkeiten. Vertrauliche Informationen, Begriffe und Themen wie kommerziell sensible Informationen und personenbezogene Daten (GDPR) können intelligent maskiert und demaskiert werden, abhängig von der Zielgruppe, die die Daten nutzt. Nachfolgend finden Sie eine Illustration zu den möglichen Schritten für die Entwicklung eines ähnlichen Modells.
Vektor-Darstellungen der Sätze mit Modellen, wie BERT, GPT und anderen, erleichtern die Suche innerhalb von Dokumenten auf Basis von Ähnlichkeit. Das bedeutet, dass auch Funktionalitäten wie das Auffinden ähnlicher Wörter oder Ausdrücke innerhalb eines Dokuments zum Schwärzen möglich sind.”
Vertragsanalysen sind eine weitere Gruppe von Anwendungsfällen, die mit Text Analytics und NLP in Due-Diligence-Prozessen eingesetzt werden. Sei es für einen Käufer, der bestehende Verträge eines potenziellen Zielunternehmens überprüft, oder für das Zielunternehmen, das eine erste diagnostische Analyse durchführt – ein rationalisierter und automatisierter Prozess kann erhebliche Ersparnisse an manueller Arbeit bringen. Verträge halten Informationen unstrukturiert fest, enthalten aber wichtige Klauseln, die während des Due-Diligence-Prozesses untergehen können. Die gründliche Analyse der Verträge ist häufig mit exorbitanten Anwaltskosten verbunden. Semantische Suche, intelligentes Tagging und die Zusammenfassung wichtiger Informationen aus Verträgen können die Anzahl der Stunden, die Anwälte für die Analyse der Verträge benötigen, deutlich reduzieren und damit Kosten sparen.
Research und Analyse des Investitionsumfelds
Buy-Side-Firmen haben bereits mehrere Einsatzmöglichkeiten für die Analyse unstrukturierter Daten für Research- oder Investment-Management-Zwecke identifiziert. Neben Textdaten gibt es auch Anwendungsfälle für die Nutzung von Informationen zum Fußgängerverkehr, zur Online-Suche und anderen ähnlichen Daten für verfeinerte Prognosen. Während des Beginns der Pandemie haben viele Analysten ihre finanziellen Ziele für die Unternehmen nur langsam aktualisiert, obwohl viele der Unternehmen ihre Gewinnprognosen zurückgezogen haben. Während der Finanzkrise wurde ein ähnliches Phänomen beobachtet.
In Zeiten der Unsicherheit werden finanzielle Indikatoren seltener aktualisiert, während die aktuellen Herausforderungen und das bestehende Umfeld für Investitionen ausführlich in Textform diskutiert wird.”
LPA
Investment-Manager, die diese Daten in ihre Entscheidungsprozesse einbeziehen, haben einen ganzheitlichen Blick auf das aktuelle Klima. Normalerweise würde ein Analyst diese Berichte überprüfen. Aber in einer schnelllebigen Umgebung ist die manuelle Durchsicht aller Dokumente nicht realisierbar. Daher können NLP- und Textanalyseverfahren dabei helfen, ein erstes Screening der Berichte durchzuführen und die Bereiche hervorzuheben, für die eine nähere Untersuchung sinnvoll ist.
Nowcasting und Zentralbank-Research
Während durch den Lockdown in der Pandemie verursachten Volatilität, hatten die Zentralbanken Schwierigkeiten, ihre Geldpolitik anzupassen. Konventionell verwendete Zahlen für geldpolitische Gremien, wie BIP, Verbraucherstimmungsindizes, Inflationszahlen, sind rückwärtsgerichtet.
 George Karapetyan fungiert als zentraler Fachexperte für Künstliche Intelligenz und Machine Learning bei LPA Consulting (Website). Als Full-Stack-Berater kombiniert er Advanced Analytics, Data Science und Machine Learning mit tiefgreifender Kapitalmarktexpertise. Als Co-Leiter der LPA Rapid Prototyping Factory entwickelt George geschäftsorientierte KI-Anwendungsfälle für Finanzdienstleister.
George Karapetyan fungiert als zentraler Fachexperte für Künstliche Intelligenz und Machine Learning bei LPA Consulting (Website). Als Full-Stack-Berater kombiniert er Advanced Analytics, Data Science und Machine Learning mit tiefgreifender Kapitalmarktexpertise. Als Co-Leiter der LPA Rapid Prototyping Factory entwickelt George geschäftsorientierte KI-Anwendungsfälle für Finanzdienstleister.
Zuvor war George bei Infosys Consulting als Co-Leiter für Themen im Bereich “Next in Banking” tätig, wo er für die Identifizierung und Implementierung von KI Anwendungsfälle und Prototypen verantwortlich war. Bevor er nach Deutschland gezogen ist, war er maßgeblich an der Implementierung einer landesweiten digitalen Versicherungsplattform in Zusammenarbeit mit Bureau Veritas und der Zentralbank von Armenien beteiligt. Er hat einen doppelten Bachelor-Abschluss von IAE Jean Moulin Lyon 3 und der Französischen Universität in Armenien sowie einen Master von der Goethe-Universität in Frankfurt in International Management. George hat seine Kompetenzen in empirischen Methoden an der Global School of Empirical Methods an der Universität St. Gallen vertieft. Weiterhin spezialisierte er sich auf Data Science und Machine Learning bei Infosys Consulting (Website).
Große Zentralbanken haben daher verstärkt auf das so genannte Nowcasting zurückgegriffen. Der Bedarf an sofortigen Daten in Stressszenarien hat eine hohe Priorität.”
Daher bietet Nowcasting durch die Nutzung von Hochfrequenzdaten, wie Texte und Zeitungsartikel, einen unmittelbaren Einblick in das Marktumfeld. Nowcasting wird nicht nur für geldpolitische Entscheidungen verwendet, sondern auch, um die Auswirkungen der getroffenen Entscheidungen abzuschätzen und bei Bedarf anzupassen. Der Trick besteht darin, den Datensatz in einer Zeitreihe zu konstruieren, die mit entsprechenden numerischen Indikatoren abgeglichen werden kann. Forscher der norwegischen Zentralbank verwenden zu diesem Zweck LDA (Latent Drichlet Allocation), um Themen aus Nachrichtenquellen zu extrahieren und das US-BIP, das Investitionswachstum und den Verbrauch zu prognostizieren.
Drei Empfehlungen für kleine und mittelgroße Finanzinstitute (FI)
Alternative Datenquellen wie Texte weisen eine ganze Reihe von Vorteilen gegenüber herkömmlichen numerischen Indikatoren auf. Diese habe eine hohe Frequenz, erzählen eine breitere Geschichte über die Wirtschaft, enthalten qualitative Informationen und sprechen über Erwartungen. Vor diesem Hintergrund gibt es 3 Dinge, die kleine und mittelgroße Finanzinstitute tun sollten, um einen Wettbewerbsvorteil gegenüber den größeren etablierten Marktteilnehmern zu erlangen:
1. Technologie- und Fachteams in den Finanzinstituten sollten regelmäßig Workshops durchführen, um geschäftsorientierte Anwendungsfälle für die Nutzung von KI, ML und NLP zu identifizieren. Das Gespräch mit Beratungsunternehmen hilft bei der Identifizierung von Anwendungsfällen, da die Branche breiter aufgestellt ist und die Beratungsunternehmen kontinuierlich forschen. 2. Erwägen Sie den Einsatz von No-Code-KI-Plattformen, um Fachbereichen die Möglichkeit zum Experimentieren zu geben. Während des Experimentierens werden Ideen zum Leben erweckt. Durch eine engere Zusammenarbeit mit fachlichen Teams kann ein viel stärkerer Business Case hinter den Technologie-Initiativen erstellt werden. 3. Bevorzugen Sie individuelle Lösungen gegenüber Standardlösungen. Standardlösungen, die dem breiteren Markt angeboten werden, sind für die Konkurrenz zugänglich und somit ist der Wettbewerbsvorteil nicht nachhaltig. George Karapetyan, LPA GruppeSie finden diesen Artikel im Internet auf der Website:
https://itfm.link/122410


Schreiben Sie einen Kommentar